mirror of
https://github.com/mendableai/firecrawl.git
synced 2024-11-16 03:32:22 +08:00
Merge branch 'main' into pr/623
This commit is contained in:
commit
48eb6fc494
2
.github/ISSUE_TEMPLATE/bug_report.md
vendored
2
.github/ISSUE_TEMPLATE/bug_report.md
vendored
|
|
@ -1,7 +1,7 @@
|
||||||
---
|
---
|
||||||
name: Bug report
|
name: Bug report
|
||||||
about: Create a report to help us improve
|
about: Create a report to help us improve
|
||||||
title: "[BUG]"
|
title: "[Bug] "
|
||||||
labels: bug
|
labels: bug
|
||||||
assignees: ''
|
assignees: ''
|
||||||
|
|
||||||
|
|
|
||||||
2
.github/ISSUE_TEMPLATE/feature_request.md
vendored
2
.github/ISSUE_TEMPLATE/feature_request.md
vendored
|
|
@ -1,7 +1,7 @@
|
||||||
---
|
---
|
||||||
name: Feature request
|
name: Feature request
|
||||||
about: Suggest an idea for this project
|
about: Suggest an idea for this project
|
||||||
title: "[Feat]"
|
title: "[Feat] "
|
||||||
labels: ''
|
labels: ''
|
||||||
assignees: ''
|
assignees: ''
|
||||||
|
|
||||||
|
|
|
||||||
40
.github/ISSUE_TEMPLATE/self_host_issue.md
vendored
Normal file
40
.github/ISSUE_TEMPLATE/self_host_issue.md
vendored
Normal file
|
|
@ -0,0 +1,40 @@
|
||||||
|
---
|
||||||
|
name: Self-host issue
|
||||||
|
about: Report an issue with self-hosting Firecrawl
|
||||||
|
title: "[Self-Host] "
|
||||||
|
labels: self-host
|
||||||
|
assignees: ''
|
||||||
|
|
||||||
|
---
|
||||||
|
|
||||||
|
**Describe the Issue**
|
||||||
|
Provide a clear and concise description of the self-hosting issue you're experiencing.
|
||||||
|
|
||||||
|
**To Reproduce**
|
||||||
|
Steps to reproduce the issue:
|
||||||
|
1. Configure the environment or settings with '...'
|
||||||
|
2. Run the command '...'
|
||||||
|
3. Observe the error or unexpected output at '...'
|
||||||
|
4. Log output/error message
|
||||||
|
|
||||||
|
**Expected Behavior**
|
||||||
|
A clear and concise description of what you expected to happen when self-hosting.
|
||||||
|
|
||||||
|
**Screenshots**
|
||||||
|
If applicable, add screenshots or copies of the command line output to help explain the self-hosting issue.
|
||||||
|
|
||||||
|
**Environment (please complete the following information):**
|
||||||
|
- OS: [e.g. macOS, Linux, Windows]
|
||||||
|
- Firecrawl Version: [e.g. 1.2.3]
|
||||||
|
- Node.js Version: [e.g. 14.x]
|
||||||
|
- Docker Version (if applicable): [e.g. 20.10.14]
|
||||||
|
- Database Type and Version: [e.g. PostgreSQL 13.4]
|
||||||
|
|
||||||
|
**Logs**
|
||||||
|
If applicable, include detailed logs to help understand the self-hosting problem.
|
||||||
|
|
||||||
|
**Configuration**
|
||||||
|
Provide relevant parts of your configuration files (with sensitive information redacted).
|
||||||
|
|
||||||
|
**Additional Context**
|
||||||
|
Add any other context about the self-hosting issue here, such as specific infrastructure details, network setup, or any modifications made to the original Firecrawl setup.
|
||||||
3
.github/workflows/ci.yml
vendored
3
.github/workflows/ci.yml
vendored
|
|
@ -28,7 +28,8 @@ env:
|
||||||
HYPERDX_API_KEY: ${{ secrets.HYPERDX_API_KEY }}
|
HYPERDX_API_KEY: ${{ secrets.HYPERDX_API_KEY }}
|
||||||
HDX_NODE_BETA_MODE: 1
|
HDX_NODE_BETA_MODE: 1
|
||||||
FIRE_ENGINE_BETA_URL: ${{ secrets.FIRE_ENGINE_BETA_URL }}
|
FIRE_ENGINE_BETA_URL: ${{ secrets.FIRE_ENGINE_BETA_URL }}
|
||||||
|
USE_DB_AUTHENTICATION: ${{ secrets.USE_DB_AUTHENTICATION }}
|
||||||
|
ENV: ${{ secrets.ENV }}
|
||||||
|
|
||||||
jobs:
|
jobs:
|
||||||
pre-deploy:
|
pre-deploy:
|
||||||
|
|
|
||||||
8
.github/workflows/fly-direct.yml
vendored
8
.github/workflows/fly-direct.yml
vendored
|
|
@ -1,7 +1,7 @@
|
||||||
name: Fly Deploy Direct
|
name: Fly Deploy Direct
|
||||||
on:
|
on:
|
||||||
schedule:
|
schedule:
|
||||||
- cron: '0 */2 * * *'
|
- cron: '0 * * * *'
|
||||||
|
|
||||||
env:
|
env:
|
||||||
ANTHROPIC_API_KEY: ${{ secrets.ANTHROPIC_API_KEY }}
|
ANTHROPIC_API_KEY: ${{ secrets.ANTHROPIC_API_KEY }}
|
||||||
|
|
@ -22,7 +22,13 @@ env:
|
||||||
SUPABASE_SERVICE_TOKEN: ${{ secrets.SUPABASE_SERVICE_TOKEN }}
|
SUPABASE_SERVICE_TOKEN: ${{ secrets.SUPABASE_SERVICE_TOKEN }}
|
||||||
SUPABASE_URL: ${{ secrets.SUPABASE_URL }}
|
SUPABASE_URL: ${{ secrets.SUPABASE_URL }}
|
||||||
TEST_API_KEY: ${{ secrets.TEST_API_KEY }}
|
TEST_API_KEY: ${{ secrets.TEST_API_KEY }}
|
||||||
|
PYPI_USERNAME: ${{ secrets.PYPI_USERNAME }}
|
||||||
|
PYPI_PASSWORD: ${{ secrets.PYPI_PASSWORD }}
|
||||||
|
NPM_TOKEN: ${{ secrets.NPM_TOKEN }}
|
||||||
|
CRATES_IO_TOKEN: ${{ secrets.CRATES_IO_TOKEN }}
|
||||||
SENTRY_AUTH_TOKEN: ${{ secrets.SENTRY_AUTH_TOKEN }}
|
SENTRY_AUTH_TOKEN: ${{ secrets.SENTRY_AUTH_TOKEN }}
|
||||||
|
USE_DB_AUTHENTICATION: ${{ secrets.USE_DB_AUTHENTICATION }}
|
||||||
|
ENV: ${{ secrets.ENV }}
|
||||||
|
|
||||||
jobs:
|
jobs:
|
||||||
deploy:
|
deploy:
|
||||||
|
|
|
||||||
304
.github/workflows/fly.yml
vendored
304
.github/workflows/fly.yml
vendored
|
|
@ -29,9 +29,10 @@ env:
|
||||||
CRATES_IO_TOKEN: ${{ secrets.CRATES_IO_TOKEN }}
|
CRATES_IO_TOKEN: ${{ secrets.CRATES_IO_TOKEN }}
|
||||||
SENTRY_AUTH_TOKEN: ${{ secrets.SENTRY_AUTH_TOKEN }}
|
SENTRY_AUTH_TOKEN: ${{ secrets.SENTRY_AUTH_TOKEN }}
|
||||||
USE_DB_AUTHENTICATION: ${{ secrets.USE_DB_AUTHENTICATION }}
|
USE_DB_AUTHENTICATION: ${{ secrets.USE_DB_AUTHENTICATION }}
|
||||||
|
ENV: ${{ secrets.ENV }}
|
||||||
|
|
||||||
jobs:
|
jobs:
|
||||||
pre-deploy-e2e-tests:
|
pre-deploy:
|
||||||
name: Pre-deploy checks
|
name: Pre-deploy checks
|
||||||
runs-on: ubuntu-latest
|
runs-on: ubuntu-latest
|
||||||
services:
|
services:
|
||||||
|
|
@ -58,197 +59,15 @@ jobs:
|
||||||
run: npm run workers &
|
run: npm run workers &
|
||||||
working-directory: ./apps/api
|
working-directory: ./apps/api
|
||||||
id: start_workers
|
id: start_workers
|
||||||
- name: Wait for the application to be ready
|
|
||||||
run: |
|
|
||||||
sleep 10
|
|
||||||
- name: Run E2E tests
|
- name: Run E2E tests
|
||||||
run: |
|
run: |
|
||||||
npm run test:prod
|
npm run test:prod
|
||||||
working-directory: ./apps/api
|
working-directory: ./apps/api
|
||||||
|
|
||||||
pre-deploy-test-suite:
|
|
||||||
name: Test Suite
|
|
||||||
needs: pre-deploy-e2e-tests
|
|
||||||
runs-on: ubuntu-latest
|
|
||||||
services:
|
|
||||||
redis:
|
|
||||||
image: redis
|
|
||||||
ports:
|
|
||||||
- 6379:6379
|
|
||||||
steps:
|
|
||||||
- uses: actions/checkout@v3
|
|
||||||
- name: Set up Node.js
|
|
||||||
uses: actions/setup-node@v3
|
|
||||||
with:
|
|
||||||
node-version: "20"
|
|
||||||
- name: Install pnpm
|
|
||||||
run: npm install -g pnpm
|
|
||||||
- name: Install dependencies
|
|
||||||
run: pnpm install
|
|
||||||
working-directory: ./apps/api
|
|
||||||
- name: Start the application
|
|
||||||
run: npm start &
|
|
||||||
working-directory: ./apps/api
|
|
||||||
id: start_app
|
|
||||||
- name: Start workers
|
|
||||||
run: npm run workers &
|
|
||||||
working-directory: ./apps/api
|
|
||||||
id: start_workers
|
|
||||||
- name: Install dependencies
|
|
||||||
run: pnpm install
|
|
||||||
working-directory: ./apps/test-suite
|
|
||||||
- name: Run E2E tests
|
|
||||||
run: |
|
|
||||||
npm run test:suite
|
|
||||||
working-directory: ./apps/test-suite
|
|
||||||
|
|
||||||
python-sdk-tests:
|
|
||||||
name: Python SDK Tests
|
|
||||||
needs: pre-deploy-e2e-tests
|
|
||||||
runs-on: ubuntu-latest
|
|
||||||
services:
|
|
||||||
redis:
|
|
||||||
image: redis
|
|
||||||
ports:
|
|
||||||
- 6379:6379
|
|
||||||
steps:
|
|
||||||
- uses: actions/checkout@v3
|
|
||||||
- name: Set up Python
|
|
||||||
uses: actions/setup-python@v4
|
|
||||||
with:
|
|
||||||
python-version: '3.x'
|
|
||||||
- name: Install pnpm
|
|
||||||
run: npm install -g pnpm
|
|
||||||
- name: Install dependencies
|
|
||||||
run: pnpm install
|
|
||||||
working-directory: ./apps/api
|
|
||||||
- name: Start the application
|
|
||||||
run: npm start &
|
|
||||||
working-directory: ./apps/api
|
|
||||||
id: start_app
|
|
||||||
- name: Start workers
|
|
||||||
run: npm run workers &
|
|
||||||
working-directory: ./apps/api
|
|
||||||
id: start_workers
|
|
||||||
- name: Install Python dependencies
|
|
||||||
run: |
|
|
||||||
python -m pip install --upgrade pip
|
|
||||||
pip install -r requirements.txt
|
|
||||||
working-directory: ./apps/python-sdk
|
|
||||||
- name: Run E2E tests for Python SDK
|
|
||||||
run: |
|
|
||||||
pytest firecrawl/__tests__/v1/e2e_withAuth/test.py
|
|
||||||
working-directory: ./apps/python-sdk
|
|
||||||
|
|
||||||
js-sdk-tests:
|
|
||||||
name: JavaScript SDK Tests
|
|
||||||
needs: pre-deploy-e2e-tests
|
|
||||||
runs-on: ubuntu-latest
|
|
||||||
services:
|
|
||||||
redis:
|
|
||||||
image: redis
|
|
||||||
ports:
|
|
||||||
- 6379:6379
|
|
||||||
steps:
|
|
||||||
- uses: actions/checkout@v3
|
|
||||||
- name: Set up Node.js
|
|
||||||
uses: actions/setup-node@v3
|
|
||||||
with:
|
|
||||||
node-version: "20"
|
|
||||||
- name: Install pnpm
|
|
||||||
run: npm install -g pnpm
|
|
||||||
- name: Install dependencies
|
|
||||||
run: pnpm install
|
|
||||||
working-directory: ./apps/api
|
|
||||||
- name: Start the application
|
|
||||||
run: npm start &
|
|
||||||
working-directory: ./apps/api
|
|
||||||
id: start_app
|
|
||||||
- name: Start workers
|
|
||||||
run: npm run workers &
|
|
||||||
working-directory: ./apps/api
|
|
||||||
id: start_workers
|
|
||||||
- name: Install dependencies for JavaScript SDK
|
|
||||||
run: pnpm install
|
|
||||||
working-directory: ./apps/js-sdk/firecrawl
|
|
||||||
- name: Run E2E tests for JavaScript SDK
|
|
||||||
run: npm run test
|
|
||||||
working-directory: ./apps/js-sdk/firecrawl
|
|
||||||
|
|
||||||
go-sdk-tests:
|
|
||||||
name: Go SDK Tests
|
|
||||||
needs: pre-deploy-e2e-tests
|
|
||||||
runs-on: ubuntu-latest
|
|
||||||
services:
|
|
||||||
redis:
|
|
||||||
image: redis
|
|
||||||
ports:
|
|
||||||
- 6379:6379
|
|
||||||
steps:
|
|
||||||
- uses: actions/checkout@v3
|
|
||||||
- name: Set up Go
|
|
||||||
uses: actions/setup-go@v5
|
|
||||||
with:
|
|
||||||
go-version-file: "go.mod"
|
|
||||||
- name: Install pnpm
|
|
||||||
run: npm install -g pnpm
|
|
||||||
- name: Install dependencies
|
|
||||||
run: pnpm install
|
|
||||||
working-directory: ./apps/api
|
|
||||||
- name: Start the application
|
|
||||||
run: npm start &
|
|
||||||
working-directory: ./apps/api
|
|
||||||
id: start_app
|
|
||||||
- name: Start workers
|
|
||||||
run: npm run workers &
|
|
||||||
working-directory: ./apps/api
|
|
||||||
id: start_workers
|
|
||||||
- name: Install dependencies for Go SDK
|
|
||||||
run: go mod tidy
|
|
||||||
working-directory: ./apps/go-sdk
|
|
||||||
- name: Run tests for Go SDK
|
|
||||||
run: go test -v ./... -timeout 180s
|
|
||||||
working-directory: ./apps/go-sdk/firecrawl
|
|
||||||
|
|
||||||
rust-sdk-tests:
|
|
||||||
name: Rust SDK Tests
|
|
||||||
needs: pre-deploy-e2e-tests
|
|
||||||
runs-on: ubuntu-latest
|
|
||||||
services:
|
|
||||||
redis:
|
|
||||||
image: redis
|
|
||||||
ports:
|
|
||||||
- 6379:6379
|
|
||||||
steps:
|
|
||||||
- name: Checkout repository
|
|
||||||
uses: actions/checkout@v3
|
|
||||||
- name: Install pnpm
|
|
||||||
run: npm install -g pnpm
|
|
||||||
- name: Install dependencies for API
|
|
||||||
run: pnpm install
|
|
||||||
working-directory: ./apps/api
|
|
||||||
- name: Start the application
|
|
||||||
run: npm start &
|
|
||||||
working-directory: ./apps/api
|
|
||||||
id: start_app
|
|
||||||
- name: Start workers
|
|
||||||
run: npm run workers &
|
|
||||||
working-directory: ./apps/api
|
|
||||||
id: start_workers
|
|
||||||
- name: Set up Rust
|
|
||||||
uses: actions/setup-rust@v1
|
|
||||||
with:
|
|
||||||
rust-version: stable
|
|
||||||
- name: Try the lib build
|
|
||||||
working-directory: ./apps/rust-sdk
|
|
||||||
run: cargo build
|
|
||||||
- name: Run E2E tests for Rust SDK
|
|
||||||
run: cargo test --test e2e_with_auth
|
|
||||||
|
|
||||||
deploy:
|
deploy:
|
||||||
name: Deploy app
|
name: Deploy app
|
||||||
|
needs: pre-deploy
|
||||||
runs-on: ubuntu-latest
|
runs-on: ubuntu-latest
|
||||||
needs: [pre-deploy-test-suite, python-sdk-tests, js-sdk-tests, rust-sdk-tests]
|
|
||||||
steps:
|
steps:
|
||||||
- uses: actions/checkout@v3
|
- uses: actions/checkout@v3
|
||||||
- uses: superfly/flyctl-actions/setup-flyctl@master
|
- uses: superfly/flyctl-actions/setup-flyctl@master
|
||||||
|
|
@ -259,119 +78,4 @@ jobs:
|
||||||
BULL_AUTH_KEY: ${{ secrets.BULL_AUTH_KEY }}
|
BULL_AUTH_KEY: ${{ secrets.BULL_AUTH_KEY }}
|
||||||
SENTRY_AUTH_TOKEN: ${{ secrets.SENTRY_AUTH_TOKEN }}
|
SENTRY_AUTH_TOKEN: ${{ secrets.SENTRY_AUTH_TOKEN }}
|
||||||
|
|
||||||
build-and-publish-python-sdk:
|
|
||||||
name: Build and publish Python SDK
|
|
||||||
runs-on: ubuntu-latest
|
|
||||||
needs: deploy
|
|
||||||
|
|
||||||
steps:
|
|
||||||
- name: Checkout repository
|
|
||||||
uses: actions/checkout@v3
|
|
||||||
|
|
||||||
- name: Set up Python
|
|
||||||
uses: actions/setup-python@v4
|
|
||||||
with:
|
|
||||||
python-version: '3.x'
|
|
||||||
|
|
||||||
- name: Install dependencies
|
|
||||||
run: |
|
|
||||||
python -m pip install --upgrade pip
|
|
||||||
pip install setuptools wheel twine build requests packaging
|
|
||||||
|
|
||||||
- name: Run version check script
|
|
||||||
id: version_check_script
|
|
||||||
run: |
|
|
||||||
PYTHON_SDK_VERSION_INCREMENTED=$(python .github/scripts/check_version_has_incremented.py python ./apps/python-sdk/firecrawl firecrawl-py)
|
|
||||||
echo "PYTHON_SDK_VERSION_INCREMENTED=$PYTHON_SDK_VERSION_INCREMENTED" >> $GITHUB_ENV
|
|
||||||
|
|
||||||
- name: Build the package
|
|
||||||
if: ${{ env.PYTHON_SDK_VERSION_INCREMENTED == 'true' }}
|
|
||||||
run: |
|
|
||||||
python -m build
|
|
||||||
working-directory: ./apps/python-sdk
|
|
||||||
|
|
||||||
- name: Publish to PyPI
|
|
||||||
if: ${{ env.PYTHON_SDK_VERSION_INCREMENTED == 'true' }}
|
|
||||||
env:
|
|
||||||
TWINE_USERNAME: ${{ secrets.PYPI_USERNAME }}
|
|
||||||
TWINE_PASSWORD: ${{ secrets.PYPI_PASSWORD }}
|
|
||||||
run: |
|
|
||||||
twine upload dist/*
|
|
||||||
working-directory: ./apps/python-sdk
|
|
||||||
|
|
||||||
build-and-publish-js-sdk:
|
|
||||||
name: Build and publish JavaScript SDK
|
|
||||||
runs-on: ubuntu-latest
|
|
||||||
needs: deploy
|
|
||||||
|
|
||||||
steps:
|
|
||||||
- uses: actions/checkout@v3
|
|
||||||
- name: Set up Node.js
|
|
||||||
uses: actions/setup-node@v3
|
|
||||||
with:
|
|
||||||
node-version: '20'
|
|
||||||
registry-url: 'https://registry.npmjs.org/'
|
|
||||||
scope: '@mendable'
|
|
||||||
always-auth: true
|
|
||||||
|
|
||||||
- name: Install pnpm
|
|
||||||
run: npm install -g pnpm
|
|
||||||
|
|
||||||
- name: Install python for running version check script
|
|
||||||
run: |
|
|
||||||
python -m pip install --upgrade pip
|
|
||||||
pip install setuptools wheel requests packaging
|
|
||||||
|
|
||||||
- name: Install dependencies for JavaScript SDK
|
|
||||||
run: pnpm install
|
|
||||||
working-directory: ./apps/js-sdk/firecrawl
|
|
||||||
|
|
||||||
- name: Run version check script
|
|
||||||
id: version_check_script
|
|
||||||
run: |
|
|
||||||
VERSION_INCREMENTED=$(python .github/scripts/check_version_has_incremented.py js ./apps/js-sdk/firecrawl @mendable/firecrawl-js)
|
|
||||||
echo "VERSION_INCREMENTED=$VERSION_INCREMENTED" >> $GITHUB_ENV
|
|
||||||
|
|
||||||
- name: Build and publish to npm
|
|
||||||
if: ${{ env.VERSION_INCREMENTED == 'true' }}
|
|
||||||
env:
|
|
||||||
NODE_AUTH_TOKEN: ${{ secrets.NPM_TOKEN }}
|
|
||||||
run: |
|
|
||||||
npm run build-and-publish
|
|
||||||
working-directory: ./apps/js-sdk/firecrawl
|
|
||||||
build-and-publish-rust-sdk:
|
|
||||||
name: Build and publish Rust SDK
|
|
||||||
runs-on: ubuntu-latest
|
|
||||||
needs: deploy
|
|
||||||
|
|
||||||
steps:
|
|
||||||
- name: Checkout repository
|
|
||||||
uses: actions/checkout@v3
|
|
||||||
|
|
||||||
- name: Set up Rust
|
|
||||||
uses: actions-rs/toolchain@v1
|
|
||||||
with:
|
|
||||||
toolchain: stable
|
|
||||||
default: true
|
|
||||||
profile: minimal
|
|
||||||
|
|
||||||
- name: Install dependencies
|
|
||||||
run: cargo build --release
|
|
||||||
|
|
||||||
- name: Run version check script
|
|
||||||
id: version_check_script
|
|
||||||
run: |
|
|
||||||
VERSION_INCREMENTED=$(cargo search --limit 1 my_crate_name | grep my_crate_name)
|
|
||||||
echo "VERSION_INCREMENTED=$VERSION_INCREMENTED" >> $GITHUB_ENV
|
|
||||||
|
|
||||||
- name: Build the package
|
|
||||||
if: ${{ env.VERSION_INCREMENTED == 'true' }}
|
|
||||||
run: cargo package
|
|
||||||
working-directory: ./apps/rust-sdk
|
|
||||||
|
|
||||||
- name: Publish to crates.io
|
|
||||||
if: ${{ env.VERSION_INCREMENTED == 'true' }}
|
|
||||||
env:
|
|
||||||
CARGO_REG_TOKEN: ${{ secrets.CRATES_IO_TOKEN }}
|
|
||||||
run: cargo publish
|
|
||||||
working-directory: ./apps/rust-sdk
|
|
||||||
5
.gitignore
vendored
5
.gitignore
vendored
|
|
@ -19,5 +19,10 @@ apps/test-suite/load-test-results/test-run-report.json
|
||||||
apps/playwright-service-ts/node_modules/
|
apps/playwright-service-ts/node_modules/
|
||||||
apps/playwright-service-ts/package-lock.json
|
apps/playwright-service-ts/package-lock.json
|
||||||
|
|
||||||
|
|
||||||
|
/examples/o1_web_crawler/venv
|
||||||
*.pyc
|
*.pyc
|
||||||
.rdb
|
.rdb
|
||||||
|
|
||||||
|
apps/js-sdk/firecrawl/dist
|
||||||
|
|
||||||
|
|
|
||||||
|
|
@ -103,7 +103,7 @@ This should return the response Hello, world!
|
||||||
If you’d like to test the crawl endpoint, you can run this
|
If you’d like to test the crawl endpoint, you can run this
|
||||||
|
|
||||||
```curl
|
```curl
|
||||||
curl -X POST http://localhost:3002/v0/crawl \
|
curl -X POST http://localhost:3002/v1/crawl \
|
||||||
-H 'Content-Type: application/json' \
|
-H 'Content-Type: application/json' \
|
||||||
-d '{
|
-d '{
|
||||||
"url": "https://mendable.ai"
|
"url": "https://mendable.ai"
|
||||||
|
|
|
||||||
39
README.md
39
README.md
|
|
@ -34,9 +34,9 @@
|
||||||
|
|
||||||
# 🔥 Firecrawl
|
# 🔥 Firecrawl
|
||||||
|
|
||||||
Crawl and convert any website into LLM-ready markdown or structured data. Built by [Mendable.ai](https://mendable.ai?ref=gfirecrawl) and the Firecrawl community. Includes powerful scraping, crawling and data extraction capabilities.
|
Empower your AI apps with clean data from any website. Featuring advanced scraping, crawling, and data extraction capabilities.
|
||||||
|
|
||||||
_This repository is in its early development stages. We are still merging custom modules in the mono repo. It's not completely yet ready for full self-host deployment, but you can already run it locally._
|
_This repository is in development, and we’re still integrating custom modules into the mono repo. It's not fully ready for self-hosted deployment yet, but you can run it locally._
|
||||||
|
|
||||||
## What is Firecrawl?
|
## What is Firecrawl?
|
||||||
|
|
||||||
|
|
@ -52,9 +52,12 @@ _Pst. hey, you, join our stargazers :)_
|
||||||
|
|
||||||
We provide an easy to use API with our hosted version. You can find the playground and documentation [here](https://firecrawl.dev/playground). You can also self host the backend if you'd like.
|
We provide an easy to use API with our hosted version. You can find the playground and documentation [here](https://firecrawl.dev/playground). You can also self host the backend if you'd like.
|
||||||
|
|
||||||
- [x] [API](https://firecrawl.dev/playground)
|
Check out the following resources to get started:
|
||||||
- [x] [Python SDK](https://github.com/mendableai/firecrawl/tree/main/apps/python-sdk)
|
- [x] [API](https://docs.firecrawl.dev/api-reference/introduction)
|
||||||
- [x] [Node SDK](https://github.com/mendableai/firecrawl/tree/main/apps/js-sdk)
|
- [x] [Python SDK](https://docs.firecrawl.dev/sdks/python)
|
||||||
|
- [x] [Node SDK](https://docs.firecrawl.dev/sdks/node)
|
||||||
|
- [x] [Go SDK](https://docs.firecrawl.dev/sdks/go)
|
||||||
|
- [x] [Rust SDK](https://docs.firecrawl.dev/sdks/rust)
|
||||||
- [x] [Langchain Integration 🦜🔗](https://python.langchain.com/docs/integrations/document_loaders/firecrawl/)
|
- [x] [Langchain Integration 🦜🔗](https://python.langchain.com/docs/integrations/document_loaders/firecrawl/)
|
||||||
- [x] [Langchain JS Integration 🦜🔗](https://js.langchain.com/docs/integrations/document_loaders/web_loaders/firecrawl)
|
- [x] [Langchain JS Integration 🦜🔗](https://js.langchain.com/docs/integrations/document_loaders/web_loaders/firecrawl)
|
||||||
- [x] [Llama Index Integration 🦙](https://docs.llamaindex.ai/en/latest/examples/data_connectors/WebPageDemo/#using-firecrawl-reader)
|
- [x] [Llama Index Integration 🦙](https://docs.llamaindex.ai/en/latest/examples/data_connectors/WebPageDemo/#using-firecrawl-reader)
|
||||||
|
|
@ -62,8 +65,12 @@ We provide an easy to use API with our hosted version. You can find the playgrou
|
||||||
- [x] [Langflow Integration](https://docs.langflow.org/)
|
- [x] [Langflow Integration](https://docs.langflow.org/)
|
||||||
- [x] [Crew.ai Integration](https://docs.crewai.com/)
|
- [x] [Crew.ai Integration](https://docs.crewai.com/)
|
||||||
- [x] [Flowise AI Integration](https://docs.flowiseai.com/integrations/langchain/document-loaders/firecrawl)
|
- [x] [Flowise AI Integration](https://docs.flowiseai.com/integrations/langchain/document-loaders/firecrawl)
|
||||||
|
- [x] [Composio Integration](https://composio.dev/tools/firecrawl/all)
|
||||||
- [x] [PraisonAI Integration](https://docs.praison.ai/firecrawl/)
|
- [x] [PraisonAI Integration](https://docs.praison.ai/firecrawl/)
|
||||||
- [x] [Zapier Integration](https://zapier.com/apps/firecrawl/integrations)
|
- [x] [Zapier Integration](https://zapier.com/apps/firecrawl/integrations)
|
||||||
|
- [x] [Cargo Integration](https://docs.getcargo.io/integration/firecrawl)
|
||||||
|
- [x] [Pipedream Integration](https://pipedream.com/apps/firecrawl/)
|
||||||
|
- [x] [Pabbly Integration](https://www.pabbly.com/connect/integrations/firecrawl/)
|
||||||
- [ ] Want an SDK or Integration? Let us know by opening an issue.
|
- [ ] Want an SDK or Integration? Let us know by opening an issue.
|
||||||
|
|
||||||
To run locally, refer to guide [here](https://github.com/mendableai/firecrawl/blob/main/SELF_HOST.md).
|
To run locally, refer to guide [here](https://github.com/mendableai/firecrawl/blob/main/SELF_HOST.md).
|
||||||
|
|
@ -402,15 +409,12 @@ class TopArticlesSchema(BaseModel):
|
||||||
top: List[ArticleSchema] = Field(..., max_items=5, description="Top 5 stories")
|
top: List[ArticleSchema] = Field(..., max_items=5, description="Top 5 stories")
|
||||||
|
|
||||||
data = app.scrape_url('https://news.ycombinator.com', {
|
data = app.scrape_url('https://news.ycombinator.com', {
|
||||||
'extractorOptions': {
|
'formats': ['extract'],
|
||||||
'extractionSchema': TopArticlesSchema.model_json_schema(),
|
'extract': {
|
||||||
'mode': 'llm-extraction'
|
'schema': TopArticlesSchema.model_json_schema()
|
||||||
},
|
|
||||||
'pageOptions':{
|
|
||||||
'onlyMainContent': True
|
|
||||||
}
|
}
|
||||||
})
|
})
|
||||||
print(data["llm_extraction"])
|
print(data["extract"])
|
||||||
```
|
```
|
||||||
|
|
||||||
## Using the Node SDK
|
## Using the Node SDK
|
||||||
|
|
@ -490,6 +494,17 @@ const scrapeResult = await app.scrapeUrl("https://news.ycombinator.com", {
|
||||||
console.log(scrapeResult.data["llm_extraction"]);
|
console.log(scrapeResult.data["llm_extraction"]);
|
||||||
```
|
```
|
||||||
|
|
||||||
|
## Open Source vs Cloud Offering
|
||||||
|
|
||||||
|
Firecrawl is open source available under the AGPL-3.0 license.
|
||||||
|
|
||||||
|
To deliver the best possible product, we offer a hosted version of Firecrawl alongside our open-source offering. The cloud solution allows us to continuously innovate and maintain a high-quality, sustainable service for all users.
|
||||||
|
|
||||||
|
Firecrawl Cloud is available at [firecrawl.dev](https://firecrawl.dev) and offers a range of features that are not available in the open source version:
|
||||||
|
|
||||||
|
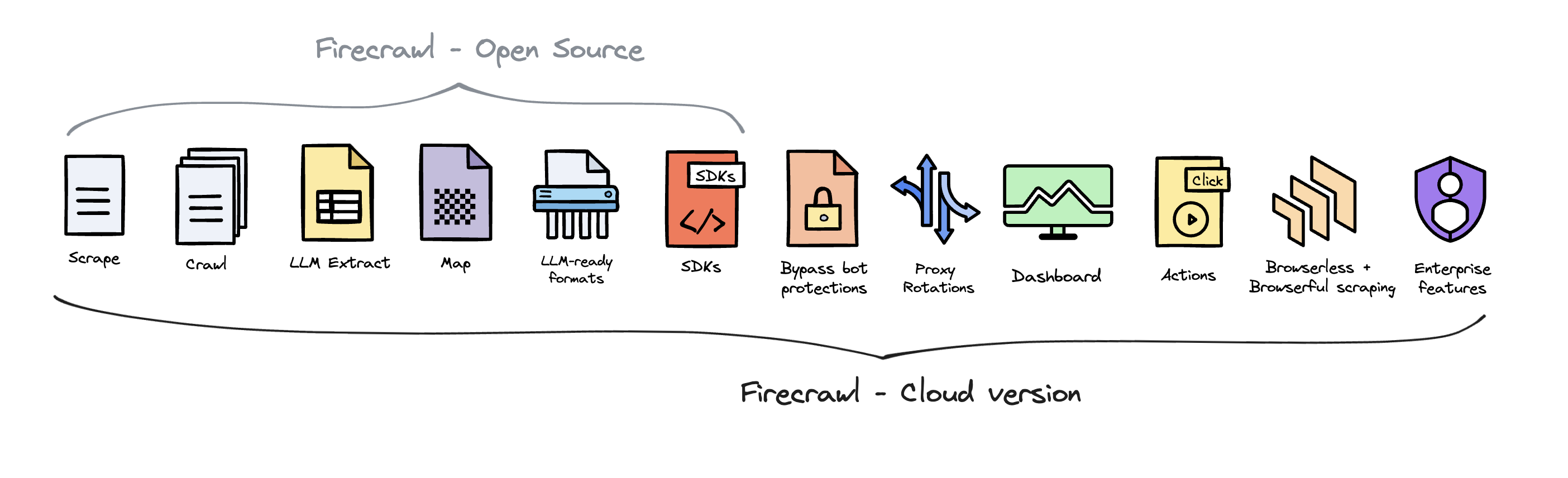
|
||||||
|
|
||||||
|
|
||||||
## Contributing
|
## Contributing
|
||||||
|
|
||||||
We love contributions! Please read our [contributing guide](CONTRIBUTING.md) before submitting a pull request.
|
We love contributions! Please read our [contributing guide](CONTRIBUTING.md) before submitting a pull request.
|
||||||
|
|
|
||||||
|
|
@ -106,7 +106,7 @@ You should be able to see the Bull Queue Manager UI on `http://localhost:3002/ad
|
||||||
If you’d like to test the crawl endpoint, you can run this:
|
If you’d like to test the crawl endpoint, you can run this:
|
||||||
|
|
||||||
```bash
|
```bash
|
||||||
curl -X POST http://localhost:3002/v0/crawl \
|
curl -X POST http://localhost:3002/v1/crawl \
|
||||||
-H 'Content-Type: application/json' \
|
-H 'Content-Type: application/json' \
|
||||||
-d '{
|
-d '{
|
||||||
"url": "https://mendable.ai"
|
"url": "https://mendable.ai"
|
||||||
|
|
|
||||||
|
|
@ -17,8 +17,15 @@ RUN pnpm install
|
||||||
RUN --mount=type=secret,id=SENTRY_AUTH_TOKEN \
|
RUN --mount=type=secret,id=SENTRY_AUTH_TOKEN \
|
||||||
bash -c 'export SENTRY_AUTH_TOKEN="$(cat /run/secrets/SENTRY_AUTH_TOKEN)"; if [ -z $SENTRY_AUTH_TOKEN ]; then pnpm run build:nosentry; else pnpm run build; fi'
|
bash -c 'export SENTRY_AUTH_TOKEN="$(cat /run/secrets/SENTRY_AUTH_TOKEN)"; if [ -z $SENTRY_AUTH_TOKEN ]; then pnpm run build:nosentry; else pnpm run build; fi'
|
||||||
|
|
||||||
# Install packages needed for deployment
|
# Install Go
|
||||||
|
FROM golang:1.19 AS go-base
|
||||||
|
COPY src/lib/go-html-to-md /app/src/lib/go-html-to-md
|
||||||
|
|
||||||
|
# Install Go dependencies and build parser lib
|
||||||
|
RUN cd /app/src/lib/go-html-to-md && \
|
||||||
|
go mod tidy && \
|
||||||
|
go build -o html-to-markdown.so -buildmode=c-shared html-to-markdown.go && \
|
||||||
|
chmod +x html-to-markdown.so
|
||||||
|
|
||||||
FROM base
|
FROM base
|
||||||
RUN apt-get update -qq && \
|
RUN apt-get update -qq && \
|
||||||
|
|
@ -26,10 +33,8 @@ RUN apt-get update -qq && \
|
||||||
rm -rf /var/lib/apt/lists /var/cache/apt/archives
|
rm -rf /var/lib/apt/lists /var/cache/apt/archives
|
||||||
COPY --from=prod-deps /app/node_modules /app/node_modules
|
COPY --from=prod-deps /app/node_modules /app/node_modules
|
||||||
COPY --from=build /app /app
|
COPY --from=build /app /app
|
||||||
|
COPY --from=go-base /app/src/lib/go-html-to-md/html-to-markdown.so /app/dist/src/lib/go-html-to-md/html-to-markdown.so
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
# Start the server by default, this can be overwritten at runtime
|
# Start the server by default, this can be overwritten at runtime
|
||||||
EXPOSE 8080
|
EXPOSE 8080
|
||||||
ENV PUPPETEER_EXECUTABLE_PATH="/usr/bin/chromium"
|
ENV PUPPETEER_EXECUTABLE_PATH="/usr/bin/chromium"
|
||||||
|
|
@ -86,6 +86,7 @@
|
||||||
"joplin-turndown-plugin-gfm": "^1.0.12",
|
"joplin-turndown-plugin-gfm": "^1.0.12",
|
||||||
"json-schema-to-zod": "^2.3.0",
|
"json-schema-to-zod": "^2.3.0",
|
||||||
"keyword-extractor": "^0.0.28",
|
"keyword-extractor": "^0.0.28",
|
||||||
|
"koffi": "^2.9.0",
|
||||||
"langchain": "^0.2.8",
|
"langchain": "^0.2.8",
|
||||||
"languagedetect": "^2.0.0",
|
"languagedetect": "^2.0.0",
|
||||||
"logsnag": "^1.0.0",
|
"logsnag": "^1.0.0",
|
||||||
|
|
|
||||||
|
|
@ -122,6 +122,9 @@ importers:
|
||||||
keyword-extractor:
|
keyword-extractor:
|
||||||
specifier: ^0.0.28
|
specifier: ^0.0.28
|
||||||
version: 0.0.28
|
version: 0.0.28
|
||||||
|
koffi:
|
||||||
|
specifier: ^2.9.0
|
||||||
|
version: 2.9.0
|
||||||
langchain:
|
langchain:
|
||||||
specifier: ^0.2.8
|
specifier: ^0.2.8
|
||||||
version: 0.2.8(@supabase/supabase-js@2.44.2)(axios@1.7.2)(cheerio@1.0.0-rc.12)(handlebars@4.7.8)(html-to-text@9.0.5)(ioredis@5.4.1)(mammoth@1.7.2)(mongodb@6.6.2(socks@2.8.3))(openai@4.57.0(zod@3.23.8))(pdf-parse@1.1.1)(puppeteer@22.12.1(typescript@5.4.5))(redis@4.6.14)(ws@8.18.0)
|
version: 0.2.8(@supabase/supabase-js@2.44.2)(axios@1.7.2)(cheerio@1.0.0-rc.12)(handlebars@4.7.8)(html-to-text@9.0.5)(ioredis@5.4.1)(mammoth@1.7.2)(mongodb@6.6.2(socks@2.8.3))(openai@4.57.0(zod@3.23.8))(pdf-parse@1.1.1)(puppeteer@22.12.1(typescript@5.4.5))(redis@4.6.14)(ws@8.18.0)
|
||||||
|
|
@ -3170,6 +3173,9 @@ packages:
|
||||||
resolution: {integrity: sha512-eTIzlVOSUR+JxdDFepEYcBMtZ9Qqdef+rnzWdRZuMbOywu5tO2w2N7rqjoANZ5k9vywhL6Br1VRjUIgTQx4E8w==}
|
resolution: {integrity: sha512-eTIzlVOSUR+JxdDFepEYcBMtZ9Qqdef+rnzWdRZuMbOywu5tO2w2N7rqjoANZ5k9vywhL6Br1VRjUIgTQx4E8w==}
|
||||||
engines: {node: '>=6'}
|
engines: {node: '>=6'}
|
||||||
|
|
||||||
|
koffi@2.9.0:
|
||||||
|
resolution: {integrity: sha512-KCsuJ2gM58n6bNdR2Z7gqsh/3TchxxQFbVgax2/UvAjRTgwNSYAJDx9E3jrkBP4jEDHWRCfE47Y2OG+/fiSvEw==}
|
||||||
|
|
||||||
langchain@0.2.8:
|
langchain@0.2.8:
|
||||||
resolution: {integrity: sha512-kb2IOMA71xH8e6EXFg0l4S+QSMC/c796pj1+7mPBkR91HHwoyHZhFRrBaZv4tV+Td+Ba91J2uEDBmySklZLpNQ==}
|
resolution: {integrity: sha512-kb2IOMA71xH8e6EXFg0l4S+QSMC/c796pj1+7mPBkR91HHwoyHZhFRrBaZv4tV+Td+Ba91J2uEDBmySklZLpNQ==}
|
||||||
engines: {node: '>=18'}
|
engines: {node: '>=18'}
|
||||||
|
|
@ -8492,6 +8498,8 @@ snapshots:
|
||||||
|
|
||||||
kleur@3.0.3: {}
|
kleur@3.0.3: {}
|
||||||
|
|
||||||
|
koffi@2.9.0: {}
|
||||||
|
|
||||||
langchain@0.2.8(@supabase/supabase-js@2.44.2)(axios@1.7.2)(cheerio@1.0.0-rc.12)(handlebars@4.7.8)(html-to-text@9.0.5)(ioredis@5.4.1)(mammoth@1.7.2)(mongodb@6.6.2(socks@2.8.3))(openai@4.57.0(zod@3.23.8))(pdf-parse@1.1.1)(puppeteer@22.12.1(typescript@5.4.5))(redis@4.6.14)(ws@8.18.0):
|
langchain@0.2.8(@supabase/supabase-js@2.44.2)(axios@1.7.2)(cheerio@1.0.0-rc.12)(handlebars@4.7.8)(html-to-text@9.0.5)(ioredis@5.4.1)(mammoth@1.7.2)(mongodb@6.6.2(socks@2.8.3))(openai@4.57.0(zod@3.23.8))(pdf-parse@1.1.1)(puppeteer@22.12.1(typescript@5.4.5))(redis@4.6.14)(ws@8.18.0):
|
||||||
dependencies:
|
dependencies:
|
||||||
'@langchain/core': 0.2.12(langchain@0.2.8(@supabase/supabase-js@2.44.2)(axios@1.7.2)(cheerio@1.0.0-rc.12)(handlebars@4.7.8)(html-to-text@9.0.5)(ioredis@5.4.1)(mammoth@1.7.2)(mongodb@6.6.2(socks@2.8.3))(openai@4.57.0(zod@3.23.8))(pdf-parse@1.1.1)(puppeteer@22.12.1(typescript@5.4.5))(redis@4.6.14)(ws@8.18.0))(openai@4.57.0(zod@3.23.8))
|
'@langchain/core': 0.2.12(langchain@0.2.8(@supabase/supabase-js@2.44.2)(axios@1.7.2)(cheerio@1.0.0-rc.12)(handlebars@4.7.8)(html-to-text@9.0.5)(ioredis@5.4.1)(mammoth@1.7.2)(mongodb@6.6.2(socks@2.8.3))(openai@4.57.0(zod@3.23.8))(pdf-parse@1.1.1)(puppeteer@22.12.1(typescript@5.4.5))(redis@4.6.14)(ws@8.18.0))(openai@4.57.0(zod@3.23.8))
|
||||||
|
|
|
||||||
|
|
@ -1,11 +1,11 @@
|
||||||
import request from "supertest";
|
import request from "supertest";
|
||||||
import dotenv from "dotenv";
|
import { configDotenv } from "dotenv";
|
||||||
import {
|
import {
|
||||||
ScrapeRequest,
|
ScrapeRequest,
|
||||||
ScrapeResponseRequestTest,
|
ScrapeResponseRequestTest,
|
||||||
} from "../../controllers/v1/types";
|
} from "../../controllers/v1/types";
|
||||||
|
|
||||||
dotenv.config();
|
configDotenv();
|
||||||
const TEST_URL = "http://127.0.0.1:3002";
|
const TEST_URL = "http://127.0.0.1:3002";
|
||||||
|
|
||||||
describe("E2E Tests for v1 API Routes", () => {
|
describe("E2E Tests for v1 API Routes", () => {
|
||||||
|
|
@ -22,6 +22,13 @@ describe("E2E Tests for v1 API Routes", () => {
|
||||||
const response: ScrapeResponseRequestTest = await request(TEST_URL).get(
|
const response: ScrapeResponseRequestTest = await request(TEST_URL).get(
|
||||||
"/is-production"
|
"/is-production"
|
||||||
);
|
);
|
||||||
|
|
||||||
|
console.log('process.env.USE_DB_AUTHENTICATION', process.env.USE_DB_AUTHENTICATION);
|
||||||
|
console.log('?', process.env.USE_DB_AUTHENTICATION === 'true');
|
||||||
|
const useDbAuthentication = process.env.USE_DB_AUTHENTICATION === 'true';
|
||||||
|
console.log('!!useDbAuthentication', !!useDbAuthentication);
|
||||||
|
console.log('!useDbAuthentication', !useDbAuthentication);
|
||||||
|
|
||||||
expect(response.statusCode).toBe(200);
|
expect(response.statusCode).toBe(200);
|
||||||
expect(response.body).toHaveProperty("isProduction");
|
expect(response.body).toHaveProperty("isProduction");
|
||||||
});
|
});
|
||||||
|
|
|
||||||
|
|
@ -5,6 +5,8 @@ import { supabase_service } from "../../../src/services/supabase";
|
||||||
import { Logger } from "../../../src/lib/logger";
|
import { Logger } from "../../../src/lib/logger";
|
||||||
import { getCrawl, saveCrawl } from "../../../src/lib/crawl-redis";
|
import { getCrawl, saveCrawl } from "../../../src/lib/crawl-redis";
|
||||||
import * as Sentry from "@sentry/node";
|
import * as Sentry from "@sentry/node";
|
||||||
|
import { configDotenv } from "dotenv";
|
||||||
|
configDotenv();
|
||||||
|
|
||||||
export async function crawlCancelController(req: Request, res: Response) {
|
export async function crawlCancelController(req: Request, res: Response) {
|
||||||
try {
|
try {
|
||||||
|
|
|
||||||
|
|
@ -4,14 +4,16 @@ import { RateLimiterMode } from "../../../src/types";
|
||||||
import { getScrapeQueue } from "../../../src/services/queue-service";
|
import { getScrapeQueue } from "../../../src/services/queue-service";
|
||||||
import { Logger } from "../../../src/lib/logger";
|
import { Logger } from "../../../src/lib/logger";
|
||||||
import { getCrawl, getCrawlJobs } from "../../../src/lib/crawl-redis";
|
import { getCrawl, getCrawlJobs } from "../../../src/lib/crawl-redis";
|
||||||
import { supabaseGetJobsById } from "../../../src/lib/supabase-jobs";
|
import { supabaseGetJobsByCrawlId } from "../../../src/lib/supabase-jobs";
|
||||||
import * as Sentry from "@sentry/node";
|
import * as Sentry from "@sentry/node";
|
||||||
|
import { configDotenv } from "dotenv";
|
||||||
|
configDotenv();
|
||||||
|
|
||||||
export async function getJobs(ids: string[]) {
|
export async function getJobs(crawlId: string, ids: string[]) {
|
||||||
const jobs = (await Promise.all(ids.map(x => getScrapeQueue().getJob(x)))).filter(x => x);
|
const jobs = (await Promise.all(ids.map(x => getScrapeQueue().getJob(x)))).filter(x => x);
|
||||||
|
|
||||||
if (process.env.USE_DB_AUTHENTICATION === "true") {
|
if (process.env.USE_DB_AUTHENTICATION === "true") {
|
||||||
const supabaseData = await supabaseGetJobsById(ids);
|
const supabaseData = await supabaseGetJobsByCrawlId(crawlId);
|
||||||
|
|
||||||
supabaseData.forEach(x => {
|
supabaseData.forEach(x => {
|
||||||
const job = jobs.find(y => y.id === x.job_id);
|
const job = jobs.find(y => y.id === x.job_id);
|
||||||
|
|
@ -50,7 +52,7 @@ export async function crawlStatusController(req: Request, res: Response) {
|
||||||
|
|
||||||
const jobIDs = await getCrawlJobs(req.params.jobId);
|
const jobIDs = await getCrawlJobs(req.params.jobId);
|
||||||
|
|
||||||
const jobs = (await getJobs(jobIDs)).sort((a, b) => a.timestamp - b.timestamp);
|
const jobs = (await getJobs(req.params.jobId, jobIDs)).sort((a, b) => a.timestamp - b.timestamp);
|
||||||
const jobStatuses = await Promise.all(jobs.map(x => x.getState()));
|
const jobStatuses = await Promise.all(jobs.map(x => x.getState()));
|
||||||
const jobStatus = sc.cancelled ? "failed" : jobStatuses.every(x => x === "completed") ? "completed" : jobStatuses.some(x => x === "failed") ? "failed" : "active";
|
const jobStatus = sc.cancelled ? "failed" : jobStatuses.every(x => x === "completed") ? "completed" : jobStatuses.some(x => x === "failed") ? "failed" : "active";
|
||||||
|
|
||||||
|
|
|
||||||
|
|
@ -39,7 +39,7 @@ export async function scrapeHelper(
|
||||||
returnCode: number;
|
returnCode: number;
|
||||||
}> {
|
}> {
|
||||||
const url = req.body.url;
|
const url = req.body.url;
|
||||||
if (!url) {
|
if (typeof url !== "string") {
|
||||||
return { success: false, error: "Url is required", returnCode: 400 };
|
return { success: false, error: "Url is required", returnCode: 400 };
|
||||||
}
|
}
|
||||||
|
|
||||||
|
|
@ -229,7 +229,7 @@ export async function scrapeController(req: Request, res: Response) {
|
||||||
|
|
||||||
if (result.success) {
|
if (result.success) {
|
||||||
let creditsToBeBilled = 1;
|
let creditsToBeBilled = 1;
|
||||||
const creditsPerLLMExtract = 49;
|
const creditsPerLLMExtract = 4;
|
||||||
|
|
||||||
if (extractorOptions.mode.includes("llm-extraction")) {
|
if (extractorOptions.mode.includes("llm-extraction")) {
|
||||||
// creditsToBeBilled = creditsToBeBilled + (creditsPerLLMExtract * filteredDocs.length);
|
// creditsToBeBilled = creditsToBeBilled + (creditsPerLLMExtract * filteredDocs.length);
|
||||||
|
|
|
||||||
|
|
@ -22,7 +22,7 @@ export async function crawlJobStatusPreviewController(req: Request, res: Respons
|
||||||
// }
|
// }
|
||||||
// }
|
// }
|
||||||
|
|
||||||
const jobs = (await getJobs(jobIDs)).sort((a, b) => a.timestamp - b.timestamp);
|
const jobs = (await getJobs(req.params.jobId, jobIDs)).sort((a, b) => a.timestamp - b.timestamp);
|
||||||
const jobStatuses = await Promise.all(jobs.map(x => x.getState()));
|
const jobStatuses = await Promise.all(jobs.map(x => x.getState()));
|
||||||
const jobStatus = sc.cancelled ? "failed" : jobStatuses.every(x => x === "completed") ? "completed" : jobStatuses.some(x => x === "failed") ? "failed" : "active";
|
const jobStatus = sc.cancelled ? "failed" : jobStatuses.every(x => x === "completed") ? "completed" : jobStatuses.some(x => x === "failed") ? "failed" : "active";
|
||||||
|
|
||||||
|
|
|
||||||
|
|
@ -5,6 +5,8 @@ import { supabase_service } from "../../services/supabase";
|
||||||
import { Logger } from "../../lib/logger";
|
import { Logger } from "../../lib/logger";
|
||||||
import { getCrawl, saveCrawl } from "../../lib/crawl-redis";
|
import { getCrawl, saveCrawl } from "../../lib/crawl-redis";
|
||||||
import * as Sentry from "@sentry/node";
|
import * as Sentry from "@sentry/node";
|
||||||
|
import { configDotenv } from "dotenv";
|
||||||
|
configDotenv();
|
||||||
|
|
||||||
export async function crawlCancelController(req: Request, res: Response) {
|
export async function crawlCancelController(req: Request, res: Response) {
|
||||||
try {
|
try {
|
||||||
|
|
|
||||||
|
|
@ -103,6 +103,7 @@ async function crawlStatusWS(ws: WebSocket, req: RequestWithAuth<CrawlStatusPara
|
||||||
send(ws, {
|
send(ws, {
|
||||||
type: "catchup",
|
type: "catchup",
|
||||||
data: {
|
data: {
|
||||||
|
success: true,
|
||||||
status,
|
status,
|
||||||
total: jobIDs.length,
|
total: jobIDs.length,
|
||||||
completed: doneJobIDs.length,
|
completed: doneJobIDs.length,
|
||||||
|
|
|
||||||
|
|
@ -3,6 +3,8 @@ import { CrawlStatusParams, CrawlStatusResponse, ErrorResponse, legacyDocumentCo
|
||||||
import { getCrawl, getCrawlExpiry, getCrawlJobs, getDoneJobsOrdered, getDoneJobsOrderedLength } from "../../lib/crawl-redis";
|
import { getCrawl, getCrawlExpiry, getCrawlJobs, getDoneJobsOrdered, getDoneJobsOrderedLength } from "../../lib/crawl-redis";
|
||||||
import { getScrapeQueue } from "../../services/queue-service";
|
import { getScrapeQueue } from "../../services/queue-service";
|
||||||
import { supabaseGetJobById, supabaseGetJobsById } from "../../lib/supabase-jobs";
|
import { supabaseGetJobById, supabaseGetJobsById } from "../../lib/supabase-jobs";
|
||||||
|
import { configDotenv } from "dotenv";
|
||||||
|
configDotenv();
|
||||||
|
|
||||||
export async function getJob(id: string) {
|
export async function getJob(id: string) {
|
||||||
const job = await getScrapeQueue().getJob(id);
|
const job = await getScrapeQueue().getJob(id);
|
||||||
|
|
@ -92,7 +94,8 @@ export async function crawlStatusController(req: RequestWithAuth<CrawlStatusPara
|
||||||
|
|
||||||
const data = doneJobs.map(x => x.returnvalue);
|
const data = doneJobs.map(x => x.returnvalue);
|
||||||
|
|
||||||
const nextURL = new URL(`${req.protocol}://${req.get("host")}/v1/crawl/${req.params.jobId}`);
|
const protocol = process.env.ENV === "local" ? req.protocol : "https";
|
||||||
|
const nextURL = new URL(`${protocol}://${req.get("host")}/v1/crawl/${req.params.jobId}`);
|
||||||
|
|
||||||
nextURL.searchParams.set("skip", (start + data.length).toString());
|
nextURL.searchParams.set("skip", (start + data.length).toString());
|
||||||
|
|
||||||
|
|
@ -111,6 +114,7 @@ export async function crawlStatusController(req: RequestWithAuth<CrawlStatusPara
|
||||||
}
|
}
|
||||||
|
|
||||||
res.status(200).json({
|
res.status(200).json({
|
||||||
|
success: true,
|
||||||
status,
|
status,
|
||||||
completed: doneJobsLength,
|
completed: doneJobsLength,
|
||||||
total: jobIDs.length,
|
total: jobIDs.length,
|
||||||
|
|
|
||||||
|
|
@ -155,10 +155,12 @@ export async function crawlController(
|
||||||
await callWebhook(req.auth.team_id, id, null, req.body.webhook, true, "crawl.started");
|
await callWebhook(req.auth.team_id, id, null, req.body.webhook, true, "crawl.started");
|
||||||
}
|
}
|
||||||
|
|
||||||
|
const protocol = process.env.ENV === "local" ? req.protocol : "https";
|
||||||
|
|
||||||
return res.status(200).json({
|
return res.status(200).json({
|
||||||
success: true,
|
success: true,
|
||||||
id,
|
id,
|
||||||
url: `${req.protocol}://${req.get("host")}/v1/crawl/${id}`,
|
url: `${protocol}://${req.get("host")}/v1/crawl/${id}`,
|
||||||
});
|
});
|
||||||
}
|
}
|
||||||
|
|
||||||
|
|
|
||||||
|
|
@ -19,8 +19,15 @@ import { billTeam } from "../../services/billing/credit_billing";
|
||||||
import { logJob } from "../../services/logging/log_job";
|
import { logJob } from "../../services/logging/log_job";
|
||||||
import { performCosineSimilarity } from "../../lib/map-cosine";
|
import { performCosineSimilarity } from "../../lib/map-cosine";
|
||||||
import { Logger } from "../../lib/logger";
|
import { Logger } from "../../lib/logger";
|
||||||
|
import Redis from "ioredis";
|
||||||
|
|
||||||
configDotenv();
|
configDotenv();
|
||||||
|
const redis = new Redis(process.env.REDIS_URL);
|
||||||
|
|
||||||
|
// Max Links that /map can return
|
||||||
|
const MAX_MAP_LIMIT = 5000;
|
||||||
|
// Max Links that "Smart /map" can return
|
||||||
|
const MAX_FIRE_ENGINE_RESULTS = 1000;
|
||||||
|
|
||||||
export async function mapController(
|
export async function mapController(
|
||||||
req: RequestWithAuth<{}, MapResponse, MapRequest>,
|
req: RequestWithAuth<{}, MapResponse, MapRequest>,
|
||||||
|
|
@ -30,8 +37,7 @@ export async function mapController(
|
||||||
|
|
||||||
req.body = mapRequestSchema.parse(req.body);
|
req.body = mapRequestSchema.parse(req.body);
|
||||||
|
|
||||||
|
const limit: number = req.body.limit ?? MAX_MAP_LIMIT;
|
||||||
const limit : number = req.body.limit ?? 5000;
|
|
||||||
|
|
||||||
const id = uuidv4();
|
const id = uuidv4();
|
||||||
let links: string[] = [req.body.url];
|
let links: string[] = [req.body.url];
|
||||||
|
|
@ -47,24 +53,61 @@ export async function mapController(
|
||||||
|
|
||||||
const crawler = crawlToCrawler(id, sc);
|
const crawler = crawlToCrawler(id, sc);
|
||||||
|
|
||||||
const sitemap = req.body.ignoreSitemap ? null : await crawler.tryGetSitemap();
|
|
||||||
|
|
||||||
if (sitemap !== null) {
|
|
||||||
sitemap.map((x) => {
|
|
||||||
links.push(x.url);
|
|
||||||
});
|
|
||||||
}
|
|
||||||
|
|
||||||
let urlWithoutWww = req.body.url.replace("www.", "");
|
let urlWithoutWww = req.body.url.replace("www.", "");
|
||||||
|
|
||||||
let mapUrl = req.body.search
|
let mapUrl = req.body.search
|
||||||
? `"${req.body.search}" site:${urlWithoutWww}`
|
? `"${req.body.search}" site:${urlWithoutWww}`
|
||||||
: `site:${req.body.url}`;
|
: `site:${req.body.url}`;
|
||||||
// www. seems to exclude subdomains in some cases
|
|
||||||
const mapResults = await fireEngineMap(mapUrl, {
|
const resultsPerPage = 100;
|
||||||
// limit to 50 results (beta)
|
const maxPages = Math.ceil(Math.min(MAX_FIRE_ENGINE_RESULTS, limit) / resultsPerPage);
|
||||||
numResults: Math.min(limit, 50),
|
|
||||||
});
|
const cacheKey = `fireEngineMap:${mapUrl}`;
|
||||||
|
const cachedResult = await redis.get(cacheKey);
|
||||||
|
|
||||||
|
let allResults: any[];
|
||||||
|
let pagePromises: Promise<any>[];
|
||||||
|
|
||||||
|
if (cachedResult) {
|
||||||
|
allResults = JSON.parse(cachedResult);
|
||||||
|
} else {
|
||||||
|
const fetchPage = async (page: number) => {
|
||||||
|
return fireEngineMap(mapUrl, {
|
||||||
|
numResults: resultsPerPage,
|
||||||
|
page: page,
|
||||||
|
});
|
||||||
|
};
|
||||||
|
|
||||||
|
pagePromises = Array.from({ length: maxPages }, (_, i) => fetchPage(i + 1));
|
||||||
|
allResults = await Promise.all(pagePromises);
|
||||||
|
|
||||||
|
await redis.set(cacheKey, JSON.stringify(allResults), "EX", 24 * 60 * 60); // Cache for 24 hours
|
||||||
|
}
|
||||||
|
|
||||||
|
// Parallelize sitemap fetch with serper search
|
||||||
|
const [sitemap, ...searchResults] = await Promise.all([
|
||||||
|
req.body.ignoreSitemap ? null : crawler.tryGetSitemap(),
|
||||||
|
...(cachedResult ? [] : pagePromises),
|
||||||
|
]);
|
||||||
|
|
||||||
|
if (!cachedResult) {
|
||||||
|
allResults = searchResults;
|
||||||
|
}
|
||||||
|
|
||||||
|
if (sitemap !== null) {
|
||||||
|
sitemap.forEach((x) => {
|
||||||
|
links.push(x.url);
|
||||||
|
});
|
||||||
|
}
|
||||||
|
|
||||||
|
let mapResults = allResults
|
||||||
|
.flat()
|
||||||
|
.filter((result) => result !== null && result !== undefined);
|
||||||
|
|
||||||
|
const minumumCutoff = Math.min(MAX_MAP_LIMIT, limit);
|
||||||
|
if (mapResults.length > minumumCutoff) {
|
||||||
|
mapResults = mapResults.slice(0, minumumCutoff);
|
||||||
|
}
|
||||||
|
|
||||||
if (mapResults.length > 0) {
|
if (mapResults.length > 0) {
|
||||||
if (req.body.search) {
|
if (req.body.search) {
|
||||||
|
|
@ -84,11 +127,19 @@ export async function mapController(
|
||||||
// Perform cosine similarity between the search query and the list of links
|
// Perform cosine similarity between the search query and the list of links
|
||||||
if (req.body.search) {
|
if (req.body.search) {
|
||||||
const searchQuery = req.body.search.toLowerCase();
|
const searchQuery = req.body.search.toLowerCase();
|
||||||
|
|
||||||
links = performCosineSimilarity(links, searchQuery);
|
links = performCosineSimilarity(links, searchQuery);
|
||||||
}
|
}
|
||||||
|
|
||||||
links = links.map((x) => checkAndUpdateURLForMap(x).url.trim());
|
links = links
|
||||||
|
.map((x) => {
|
||||||
|
try {
|
||||||
|
return checkAndUpdateURLForMap(x).url.trim();
|
||||||
|
} catch (_) {
|
||||||
|
return null;
|
||||||
|
}
|
||||||
|
})
|
||||||
|
.filter((x) => x !== null);
|
||||||
|
|
||||||
// allows for subdomains to be included
|
// allows for subdomains to be included
|
||||||
links = links.filter((x) => isSameDomain(x, req.body.url));
|
links = links.filter((x) => isSameDomain(x, req.body.url));
|
||||||
|
|
@ -101,8 +152,10 @@ export async function mapController(
|
||||||
// remove duplicates that could be due to http/https or www
|
// remove duplicates that could be due to http/https or www
|
||||||
links = removeDuplicateUrls(links);
|
links = removeDuplicateUrls(links);
|
||||||
|
|
||||||
billTeam(req.auth.team_id, 1).catch(error => {
|
billTeam(req.auth.team_id, 1).catch((error) => {
|
||||||
Logger.error(`Failed to bill team ${req.auth.team_id} for 1 credit: ${error}`);
|
Logger.error(
|
||||||
|
`Failed to bill team ${req.auth.team_id} for 1 credit: ${error}`
|
||||||
|
);
|
||||||
// Optionally, you could notify an admin or add to a retry queue here
|
// Optionally, you could notify an admin or add to a retry queue here
|
||||||
});
|
});
|
||||||
|
|
||||||
|
|
@ -110,7 +163,7 @@ export async function mapController(
|
||||||
const timeTakenInSeconds = (endTime - startTime) / 1000;
|
const timeTakenInSeconds = (endTime - startTime) / 1000;
|
||||||
|
|
||||||
const linksToReturn = links.slice(0, limit);
|
const linksToReturn = links.slice(0, limit);
|
||||||
|
|
||||||
logJob({
|
logJob({
|
||||||
job_id: id,
|
job_id: id,
|
||||||
success: links.length > 0,
|
success: links.length > 0,
|
||||||
|
|
@ -134,3 +187,51 @@ export async function mapController(
|
||||||
scrape_id: req.body.origin?.includes("website") ? id : undefined,
|
scrape_id: req.body.origin?.includes("website") ? id : undefined,
|
||||||
});
|
});
|
||||||
}
|
}
|
||||||
|
|
||||||
|
// Subdomain sitemap url checking
|
||||||
|
|
||||||
|
// // For each result, check for subdomains, get their sitemaps and add them to the links
|
||||||
|
// const processedUrls = new Set();
|
||||||
|
// const processedSubdomains = new Set();
|
||||||
|
|
||||||
|
// for (const result of links) {
|
||||||
|
// let url;
|
||||||
|
// let hostParts;
|
||||||
|
// try {
|
||||||
|
// url = new URL(result);
|
||||||
|
// hostParts = url.hostname.split('.');
|
||||||
|
// } catch (e) {
|
||||||
|
// continue;
|
||||||
|
// }
|
||||||
|
|
||||||
|
// console.log("hostParts", hostParts);
|
||||||
|
// // Check if it's a subdomain (more than 2 parts, and not 'www')
|
||||||
|
// if (hostParts.length > 2 && hostParts[0] !== 'www') {
|
||||||
|
// const subdomain = hostParts[0];
|
||||||
|
// console.log("subdomain", subdomain);
|
||||||
|
// const subdomainUrl = `${url.protocol}//${subdomain}.${hostParts.slice(-2).join('.')}`;
|
||||||
|
// console.log("subdomainUrl", subdomainUrl);
|
||||||
|
|
||||||
|
// if (!processedSubdomains.has(subdomainUrl)) {
|
||||||
|
// processedSubdomains.add(subdomainUrl);
|
||||||
|
|
||||||
|
// const subdomainCrawl = crawlToCrawler(id, {
|
||||||
|
// originUrl: subdomainUrl,
|
||||||
|
// crawlerOptions: legacyCrawlerOptions(req.body),
|
||||||
|
// pageOptions: {},
|
||||||
|
// team_id: req.auth.team_id,
|
||||||
|
// createdAt: Date.now(),
|
||||||
|
// plan: req.auth.plan,
|
||||||
|
// });
|
||||||
|
// const subdomainSitemap = await subdomainCrawl.tryGetSitemap();
|
||||||
|
// if (subdomainSitemap) {
|
||||||
|
// subdomainSitemap.forEach((x) => {
|
||||||
|
// if (!processedUrls.has(x.url)) {
|
||||||
|
// processedUrls.add(x.url);
|
||||||
|
// links.push(x.url);
|
||||||
|
// }
|
||||||
|
// });
|
||||||
|
// }
|
||||||
|
// }
|
||||||
|
// }
|
||||||
|
// }
|
||||||
|
|
|
||||||
|
|
@ -103,7 +103,7 @@ export async function scrapeController(
|
||||||
return;
|
return;
|
||||||
}
|
}
|
||||||
if(req.body.extract && req.body.formats.includes("extract")) {
|
if(req.body.extract && req.body.formats.includes("extract")) {
|
||||||
creditsToBeBilled = 50;
|
creditsToBeBilled = 5;
|
||||||
}
|
}
|
||||||
|
|
||||||
billTeam(req.auth.team_id, creditsToBeBilled).catch(error => {
|
billTeam(req.auth.team_id, creditsToBeBilled).catch(error => {
|
||||||
|
|
|
||||||
|
|
@ -30,7 +30,14 @@ export const url = z.preprocess(
|
||||||
"URL must have a valid top-level domain or be a valid path"
|
"URL must have a valid top-level domain or be a valid path"
|
||||||
)
|
)
|
||||||
.refine(
|
.refine(
|
||||||
(x) => checkUrl(x as string),
|
(x) => {
|
||||||
|
try {
|
||||||
|
checkUrl(x as string)
|
||||||
|
return true;
|
||||||
|
} catch (_) {
|
||||||
|
return false;
|
||||||
|
}
|
||||||
|
},
|
||||||
"Invalid URL"
|
"Invalid URL"
|
||||||
)
|
)
|
||||||
.refine(
|
.refine(
|
||||||
|
|
@ -63,7 +70,8 @@ export const scrapeOptions = z.object({
|
||||||
])
|
])
|
||||||
.array()
|
.array()
|
||||||
.optional()
|
.optional()
|
||||||
.default(["markdown"]),
|
.default(["markdown"])
|
||||||
|
.refine(x => !(x.includes("screenshot") && x.includes("screenshot@fullPage")), "You may only specify either screenshot or screenshot@fullPage"),
|
||||||
headers: z.record(z.string(), z.string()).optional(),
|
headers: z.record(z.string(), z.string()).optional(),
|
||||||
includeTags: z.string().array().optional(),
|
includeTags: z.string().array().optional(),
|
||||||
excludeTags: z.string().array().optional(),
|
excludeTags: z.string().array().optional(),
|
||||||
|
|
@ -257,6 +265,7 @@ export type CrawlStatusParams = {
|
||||||
export type CrawlStatusResponse =
|
export type CrawlStatusResponse =
|
||||||
| ErrorResponse
|
| ErrorResponse
|
||||||
| {
|
| {
|
||||||
|
success: true;
|
||||||
status: "scraping" | "completed" | "failed" | "cancelled";
|
status: "scraping" | "completed" | "failed" | "cancelled";
|
||||||
completed: number;
|
completed: number;
|
||||||
total: number;
|
total: number;
|
||||||
|
|
@ -322,6 +331,7 @@ export function legacyScrapeOptions(x: ScrapeOptions): PageOptions {
|
||||||
removeTags: x.excludeTags,
|
removeTags: x.excludeTags,
|
||||||
onlyMainContent: x.onlyMainContent,
|
onlyMainContent: x.onlyMainContent,
|
||||||
waitFor: x.waitFor,
|
waitFor: x.waitFor,
|
||||||
|
headers: x.headers,
|
||||||
includeLinks: x.formats.includes("links"),
|
includeLinks: x.formats.includes("links"),
|
||||||
screenshot: x.formats.includes("screenshot"),
|
screenshot: x.formats.includes("screenshot"),
|
||||||
fullPageScreenshot: x.formats.includes("screenshot@fullPage"),
|
fullPageScreenshot: x.formats.includes("screenshot@fullPage"),
|
||||||
|
|
@ -339,7 +349,7 @@ export function legacyExtractorOptions(x: ExtractOptions): ExtractorOptions {
|
||||||
}
|
}
|
||||||
|
|
||||||
export function legacyDocumentConverter(doc: any): Document {
|
export function legacyDocumentConverter(doc: any): Document {
|
||||||
if (doc === null || doc === undefined) return doc;
|
if (doc === null || doc === undefined) return null;
|
||||||
|
|
||||||
if (doc.metadata) {
|
if (doc.metadata) {
|
||||||
if (doc.metadata.screenshot) {
|
if (doc.metadata.screenshot) {
|
||||||
|
|
|
||||||
|
|
@ -201,16 +201,20 @@ if (cluster.isMaster) {
|
||||||
Sentry.setupExpressErrorHandler(app);
|
Sentry.setupExpressErrorHandler(app);
|
||||||
|
|
||||||
app.use((err: unknown, req: Request<{}, ErrorResponse, undefined>, res: ResponseWithSentry<ErrorResponse>, next: NextFunction) => {
|
app.use((err: unknown, req: Request<{}, ErrorResponse, undefined>, res: ResponseWithSentry<ErrorResponse>, next: NextFunction) => {
|
||||||
|
if (err instanceof SyntaxError && 'status' in err && err.status === 400 && 'body' in err) {
|
||||||
|
return res.status(400).json({ success: false, error: 'Bad request, malformed JSON' });
|
||||||
|
}
|
||||||
|
|
||||||
const id = res.sentry ?? uuidv4();
|
const id = res.sentry ?? uuidv4();
|
||||||
let verbose = JSON.stringify(err);
|
let verbose = JSON.stringify(err);
|
||||||
if (verbose === "{}") {
|
if (verbose === "{}") {
|
||||||
if (err instanceof Error) {
|
if (err instanceof Error) {
|
||||||
verbose = JSON.stringify({
|
verbose = JSON.stringify({
|
||||||
message: err.message,
|
message: err.message,
|
||||||
name: err.name,
|
name: err.name,
|
||||||
stack: err.stack,
|
stack: err.stack,
|
||||||
});
|
});
|
||||||
}
|
}
|
||||||
}
|
}
|
||||||
|
|
||||||
Logger.error("Error occurred in request! (" + req.path + ") -- ID " + id + " -- " + verbose);
|
Logger.error("Error occurred in request! (" + req.path + ") -- ID " + id + " -- " + verbose);
|
||||||
|
|
|
||||||
40
apps/api/src/lib/__tests__/html-to-markdown.test.ts
Normal file
40
apps/api/src/lib/__tests__/html-to-markdown.test.ts
Normal file
|
|
@ -0,0 +1,40 @@
|
||||||
|
import { parseMarkdown } from '../html-to-markdown';
|
||||||
|
|
||||||
|
describe('parseMarkdown', () => {
|
||||||
|
it('should correctly convert simple HTML to Markdown', async () => {
|
||||||
|
const html = '<p>Hello, world!</p>';
|
||||||
|
const expectedMarkdown = 'Hello, world!';
|
||||||
|
await expect(parseMarkdown(html)).resolves.toBe(expectedMarkdown);
|
||||||
|
});
|
||||||
|
|
||||||
|
it('should convert complex HTML with nested elements to Markdown', async () => {
|
||||||
|
const html = '<div><p>Hello <strong>bold</strong> world!</p><ul><li>List item</li></ul></div>';
|
||||||
|
const expectedMarkdown = 'Hello **bold** world!\n\n- List item';
|
||||||
|
await expect(parseMarkdown(html)).resolves.toBe(expectedMarkdown);
|
||||||
|
});
|
||||||
|
|
||||||
|
it('should return empty string when input is empty', async () => {
|
||||||
|
const html = '';
|
||||||
|
const expectedMarkdown = '';
|
||||||
|
await expect(parseMarkdown(html)).resolves.toBe(expectedMarkdown);
|
||||||
|
});
|
||||||
|
|
||||||
|
it('should handle null input gracefully', async () => {
|
||||||
|
const html = null;
|
||||||
|
const expectedMarkdown = '';
|
||||||
|
await expect(parseMarkdown(html)).resolves.toBe(expectedMarkdown);
|
||||||
|
});
|
||||||
|
|
||||||
|
it('should handle various types of invalid HTML gracefully', async () => {
|
||||||
|
const invalidHtmls = [
|
||||||
|
{ html: '<html><p>Unclosed tag', expected: 'Unclosed tag' },
|
||||||
|
{ html: '<div><span>Missing closing div', expected: 'Missing closing div' },
|
||||||
|
{ html: '<p><strong>Wrong nesting</em></strong></p>', expected: '**Wrong nesting**' },
|
||||||
|
{ html: '<a href="http://example.com">Link without closing tag', expected: '[Link without closing tag](http://example.com)' }
|
||||||
|
];
|
||||||
|
|
||||||
|
for (const { html, expected } of invalidHtmls) {
|
||||||
|
await expect(parseMarkdown(html)).resolves.toBe(expected);
|
||||||
|
}
|
||||||
|
});
|
||||||
|
});
|
||||||
|
|
@ -28,7 +28,7 @@ export type PageOptions = {
|
||||||
onlyIncludeTags?: string | string[];
|
onlyIncludeTags?: string | string[];
|
||||||
includeLinks?: boolean;
|
includeLinks?: boolean;
|
||||||
useFastMode?: boolean; // beta
|
useFastMode?: boolean; // beta
|
||||||
disableJSDom?: boolean; // beta
|
disableJsDom?: boolean; // beta
|
||||||
atsv?: boolean; // beta
|
atsv?: boolean; // beta
|
||||||
};
|
};
|
||||||
|
|
||||||
|
|
|
||||||
7
apps/api/src/lib/go-html-to-md/README.md
Normal file
7
apps/api/src/lib/go-html-to-md/README.md
Normal file
|
|
@ -0,0 +1,7 @@
|
||||||
|
To build the go-html-to-md library, run the following command:
|
||||||
|
|
||||||
|
```bash
|
||||||
|
cd apps/api/src/lib/go-html-to-md
|
||||||
|
go build -o html-to-markdown.so -buildmode=c-shared html-to-markdown.go
|
||||||
|
chmod +x html-to-markdown.so
|
||||||
|
```
|
||||||
14
apps/api/src/lib/go-html-to-md/go.mod
Normal file
14
apps/api/src/lib/go-html-to-md/go.mod
Normal file
|
|
@ -0,0 +1,14 @@
|
||||||
|
module html-to-markdown.go
|
||||||
|
|
||||||
|
go 1.19
|
||||||
|
|
||||||
|
require github.com/JohannesKaufmann/html-to-markdown v1.6.0
|
||||||
|
|
||||||
|
require (
|
||||||
|
github.com/PuerkitoBio/goquery v1.9.2 // indirect
|
||||||
|
github.com/andybalholm/cascadia v1.3.2 // indirect
|
||||||
|
github.com/kr/pretty v0.3.0 // indirect
|
||||||
|
golang.org/x/net v0.25.0 // indirect
|
||||||
|
gopkg.in/check.v1 v1.0.0-20201130134442-10cb98267c6c // indirect
|
||||||
|
gopkg.in/yaml.v2 v2.4.0 // indirect
|
||||||
|
)
|
||||||
93
apps/api/src/lib/go-html-to-md/go.sum
Normal file
93
apps/api/src/lib/go-html-to-md/go.sum
Normal file
|
|
@ -0,0 +1,93 @@
|
||||||
|
github.com/JohannesKaufmann/html-to-markdown v1.6.0 h1:04VXMiE50YYfCfLboJCLcgqF5x+rHJnb1ssNmqpLH/k=
|
||||||
|
github.com/JohannesKaufmann/html-to-markdown v1.6.0/go.mod h1:NUI78lGg/a7vpEJTz/0uOcYMaibytE4BUOQS8k78yPQ=
|
||||||
|
github.com/PuerkitoBio/goquery v1.9.2 h1:4/wZksC3KgkQw7SQgkKotmKljk0M6V8TUvA8Wb4yPeE=
|
||||||
|
github.com/PuerkitoBio/goquery v1.9.2/go.mod h1:GHPCaP0ODyyxqcNoFGYlAprUFH81NuRPd0GX3Zu2Mvk=
|
||||||
|
github.com/andybalholm/cascadia v1.3.2 h1:3Xi6Dw5lHF15JtdcmAHD3i1+T8plmv7BQ/nsViSLyss=
|
||||||
|
github.com/andybalholm/cascadia v1.3.2/go.mod h1:7gtRlve5FxPPgIgX36uWBX58OdBsSS6lUvCFb+h7KvU=
|
||||||
|
github.com/creack/pty v1.1.9/go.mod h1:oKZEueFk5CKHvIhNR5MUki03XCEU+Q6VDXinZuGJ33E=
|
||||||
|
github.com/davecgh/go-spew v1.1.0/go.mod h1:J7Y8YcW2NihsgmVo/mv3lAwl/skON4iLHjSsI+c5H38=
|
||||||
|
github.com/davecgh/go-spew v1.1.1/go.mod h1:J7Y8YcW2NihsgmVo/mv3lAwl/skON4iLHjSsI+c5H38=
|
||||||
|
github.com/kr/pretty v0.1.0/go.mod h1:dAy3ld7l9f0ibDNOQOHHMYYIIbhfbHSm3C4ZsoJORNo=
|
||||||
|
github.com/kr/pretty v0.2.1/go.mod h1:ipq/a2n7PKx3OHsz4KJII5eveXtPO4qwEXGdVfWzfnI=
|
||||||
|
github.com/kr/pretty v0.3.0 h1:WgNl7dwNpEZ6jJ9k1snq4pZsg7DOEN8hP9Xw0Tsjwk0=
|
||||||
|
github.com/kr/pretty v0.3.0/go.mod h1:640gp4NfQd8pI5XOwp5fnNeVWj67G7CFk/SaSQn7NBk=
|
||||||
|
github.com/kr/pty v1.1.1/go.mod h1:pFQYn66WHrOpPYNljwOMqo10TkYh1fy3cYio2l3bCsQ=
|
||||||
|
github.com/kr/text v0.1.0/go.mod h1:4Jbv+DJW3UT/LiOwJeYQe1efqtUx/iVham/4vfdArNI=
|
||||||
|
github.com/kr/text v0.2.0 h1:5Nx0Ya0ZqY2ygV366QzturHI13Jq95ApcVaJBhpS+AY=
|
||||||
|
github.com/kr/text v0.2.0/go.mod h1:eLer722TekiGuMkidMxC/pM04lWEeraHUUmBw8l2grE=
|
||||||
|
github.com/pkg/errors v0.8.1/go.mod h1:bwawxfHBFNV+L2hUp1rHADufV3IMtnDRdf1r5NINEl0=
|
||||||
|
github.com/pmezard/go-difflib v1.0.0 h1:4DBwDE0NGyQoBHbLQYPwSUPoCMWR5BEzIk/f1lZbAQM=
|
||||||
|
github.com/pmezard/go-difflib v1.0.0/go.mod h1:iKH77koFhYxTK1pcRnkKkqfTogsbg7gZNVY4sRDYZ/4=
|
||||||
|
github.com/rogpeppe/go-internal v1.6.1 h1:/FiVV8dS/e+YqF2JvO3yXRFbBLTIuSDkuC7aBOAvL+k=
|
||||||
|
github.com/rogpeppe/go-internal v1.6.1/go.mod h1:xXDCJY+GAPziupqXw64V24skbSoqbTEfhy4qGm1nDQc=
|
||||||
|
github.com/sebdah/goldie/v2 v2.5.3 h1:9ES/mNN+HNUbNWpVAlrzuZ7jE+Nrczbj8uFRjM7624Y=
|
||||||
|
github.com/sebdah/goldie/v2 v2.5.3/go.mod h1:oZ9fp0+se1eapSRjfYbsV/0Hqhbuu3bJVvKI/NNtssI=
|
||||||
|
github.com/sergi/go-diff v1.0.0/go.mod h1:0CfEIISq7TuYL3j771MWULgwwjU+GofnZX9QAmXWZgo=
|
||||||
|
github.com/sergi/go-diff v1.3.1 h1:xkr+Oxo4BOQKmkn/B9eMK0g5Kg/983T9DqqPHwYqD+8=
|
||||||
|
github.com/sergi/go-diff v1.3.1/go.mod h1:aMJSSKb2lpPvRNec0+w3fl7LP9IOFzdc9Pa4NFbPK1I=
|
||||||
|
github.com/stretchr/objx v0.1.0/go.mod h1:HFkY916IF+rwdDfMAkV7OtwuqBVzrE8GR6GFx+wExME=
|
||||||
|
github.com/stretchr/testify v1.3.0/go.mod h1:M5WIy9Dh21IEIfnGCwXGc5bZfKNJtfHm1UVUgZn+9EI=
|
||||||
|
github.com/stretchr/testify v1.4.0/go.mod h1:j7eGeouHqKxXV5pUuKE4zz7dFj8WfuZ+81PSLYec5m4=
|
||||||
|
github.com/yuin/goldmark v1.4.13/go.mod h1:6yULJ656Px+3vBD8DxQVa3kxgyrAnzto9xy5taEt/CY=
|
||||||
|
github.com/yuin/goldmark v1.7.1 h1:3bajkSilaCbjdKVsKdZjZCLBNPL9pYzrCakKaf4U49U=
|
||||||
|
github.com/yuin/goldmark v1.7.1/go.mod h1:uzxRWxtg69N339t3louHJ7+O03ezfj6PlliRlaOzY1E=
|
||||||
|
golang.org/x/crypto v0.0.0-20190308221718-c2843e01d9a2/go.mod h1:djNgcEr1/C05ACkg1iLfiJU5Ep61QUkGW8qpdssI0+w=
|
||||||
|
golang.org/x/crypto v0.0.0-20210921155107-089bfa567519/go.mod h1:GvvjBRRGRdwPK5ydBHafDWAxML/pGHZbMvKqRZ5+Abc=
|
||||||
|
golang.org/x/crypto v0.19.0/go.mod h1:Iy9bg/ha4yyC70EfRS8jz+B6ybOBKMaSxLj6P6oBDfU=
|
||||||
|
golang.org/x/crypto v0.22.0/go.mod h1:vr6Su+7cTlO45qkww3VDJlzDn0ctJvRgYbC2NvXHt+M=
|
||||||
|
golang.org/x/crypto v0.23.0/go.mod h1:CKFgDieR+mRhux2Lsu27y0fO304Db0wZe70UKqHu0v8=
|
||||||
|
golang.org/x/mod v0.6.0-dev.0.20220419223038-86c51ed26bb4/go.mod h1:jJ57K6gSWd91VN4djpZkiMVwK6gcyfeH4XE8wZrZaV4=
|
||||||
|
golang.org/x/mod v0.8.0/go.mod h1:iBbtSCu2XBx23ZKBPSOrRkjjQPZFPuis4dIYUhu/chs=
|
||||||
|
golang.org/x/net v0.0.0-20190620200207-3b0461eec859/go.mod h1:z5CRVTTTmAJ677TzLLGU+0bjPO0LkuOLi4/5GtJWs/s=
|
||||||
|
golang.org/x/net v0.0.0-20210226172049-e18ecbb05110/go.mod h1:m0MpNAwzfU5UDzcl9v0D8zg8gWTRqZa9RBIspLL5mdg=
|
||||||
|
golang.org/x/net v0.0.0-20220722155237-a158d28d115b/go.mod h1:XRhObCWvk6IyKnWLug+ECip1KBveYUHfp+8e9klMJ9c=
|
||||||
|
golang.org/x/net v0.6.0/go.mod h1:2Tu9+aMcznHK/AK1HMvgo6xiTLG5rD5rZLDS+rp2Bjs=
|
||||||
|
golang.org/x/net v0.9.0/go.mod h1:d48xBJpPfHeWQsugry2m+kC02ZBRGRgulfHnEXEuWns=
|
||||||
|
golang.org/x/net v0.10.0/go.mod h1:0qNGK6F8kojg2nk9dLZ2mShWaEBan6FAoqfSigmmuDg=
|
||||||
|
golang.org/x/net v0.21.0/go.mod h1:bIjVDfnllIU7BJ2DNgfnXvpSvtn8VRwhlsaeUTyUS44=
|
||||||
|
golang.org/x/net v0.24.0/go.mod h1:2Q7sJY5mzlzWjKtYUEXSlBWCdyaioyXzRB2RtU8KVE8=
|
||||||
|
golang.org/x/net v0.25.0 h1:d/OCCoBEUq33pjydKrGQhw7IlUPI2Oylr+8qLx49kac=
|
||||||
|
golang.org/x/net v0.25.0/go.mod h1:JkAGAh7GEvH74S6FOH42FLoXpXbE/aqXSrIQjXgsiwM=
|
||||||
|
golang.org/x/sync v0.0.0-20190423024810-112230192c58/go.mod h1:RxMgew5VJxzue5/jJTE5uejpjVlOe/izrB70Jof72aM=
|
||||||
|
golang.org/x/sync v0.0.0-20220722155255-886fb9371eb4/go.mod h1:RxMgew5VJxzue5/jJTE5uejpjVlOe/izrB70Jof72aM=
|
||||||
|
golang.org/x/sync v0.1.0/go.mod h1:RxMgew5VJxzue5/jJTE5uejpjVlOe/izrB70Jof72aM=
|
||||||
|
golang.org/x/sys v0.0.0-20190215142949-d0b11bdaac8a/go.mod h1:STP8DvDyc/dI5b8T5hshtkjS+E42TnysNCUPdjciGhY=
|
||||||
|
golang.org/x/sys v0.0.0-20201119102817-f84b799fce68/go.mod h1:h1NjWce9XRLGQEsW7wpKNCjG9DtNlClVuFLEZdDNbEs=
|
||||||
|
golang.org/x/sys v0.0.0-20210615035016-665e8c7367d1/go.mod h1:oPkhp1MJrh7nUepCBck5+mAzfO9JrbApNNgaTdGDITg=
|
||||||
|
golang.org/x/sys v0.0.0-20220520151302-bc2c85ada10a/go.mod h1:oPkhp1MJrh7nUepCBck5+mAzfO9JrbApNNgaTdGDITg=
|
||||||
|
golang.org/x/sys v0.0.0-20220722155257-8c9f86f7a55f/go.mod h1:oPkhp1MJrh7nUepCBck5+mAzfO9JrbApNNgaTdGDITg=
|
||||||
|
golang.org/x/sys v0.5.0/go.mod h1:oPkhp1MJrh7nUepCBck5+mAzfO9JrbApNNgaTdGDITg=
|
||||||
|
golang.org/x/sys v0.7.0/go.mod h1:oPkhp1MJrh7nUepCBck5+mAzfO9JrbApNNgaTdGDITg=
|
||||||
|
golang.org/x/sys v0.8.0/go.mod h1:oPkhp1MJrh7nUepCBck5+mAzfO9JrbApNNgaTdGDITg=
|
||||||
|
golang.org/x/sys v0.17.0/go.mod h1:/VUhepiaJMQUp4+oa/7Zr1D23ma6VTLIYjOOTFZPUcA=
|
||||||
|
golang.org/x/sys v0.19.0/go.mod h1:/VUhepiaJMQUp4+oa/7Zr1D23ma6VTLIYjOOTFZPUcA=
|
||||||
|
golang.org/x/sys v0.20.0/go.mod h1:/VUhepiaJMQUp4+oa/7Zr1D23ma6VTLIYjOOTFZPUcA=
|
||||||
|
golang.org/x/term v0.0.0-20201126162022-7de9c90e9dd1/go.mod h1:bj7SfCRtBDWHUb9snDiAeCFNEtKQo2Wmx5Cou7ajbmo=
|
||||||
|
golang.org/x/term v0.0.0-20210927222741-03fcf44c2211/go.mod h1:jbD1KX2456YbFQfuXm/mYQcufACuNUgVhRMnK/tPxf8=
|
||||||
|
golang.org/x/term v0.5.0/go.mod h1:jMB1sMXY+tzblOD4FWmEbocvup2/aLOaQEp7JmGp78k=
|
||||||
|
golang.org/x/term v0.7.0/go.mod h1:P32HKFT3hSsZrRxla30E9HqToFYAQPCMs/zFMBUFqPY=
|
||||||
|
golang.org/x/term v0.8.0/go.mod h1:xPskH00ivmX89bAKVGSKKtLOWNx2+17Eiy94tnKShWo=
|
||||||
|
golang.org/x/term v0.17.0/go.mod h1:lLRBjIVuehSbZlaOtGMbcMncT+aqLLLmKrsjNrUguwk=
|
||||||
|
golang.org/x/term v0.19.0/go.mod h1:2CuTdWZ7KHSQwUzKva0cbMg6q2DMI3Mmxp+gKJbskEk=
|
||||||
|
golang.org/x/term v0.20.0/go.mod h1:8UkIAJTvZgivsXaD6/pH6U9ecQzZ45awqEOzuCvwpFY=
|
||||||
|
golang.org/x/text v0.3.0/go.mod h1:NqM8EUOU14njkJ3fqMW+pc6Ldnwhi/IjpwHt7yyuwOQ=
|
||||||
|
golang.org/x/text v0.3.3/go.mod h1:5Zoc/QRtKVWzQhOtBMvqHzDpF6irO9z98xDceosuGiQ=
|
||||||
|
golang.org/x/text v0.3.7/go.mod h1:u+2+/6zg+i71rQMx5EYifcz6MCKuco9NR6JIITiCfzQ=
|
||||||
|
golang.org/x/text v0.7.0/go.mod h1:mrYo+phRRbMaCq/xk9113O4dZlRixOauAjOtrjsXDZ8=
|
||||||
|
golang.org/x/text v0.9.0/go.mod h1:e1OnstbJyHTd6l/uOt8jFFHp6TRDWZR/bV3emEE/zU8=
|
||||||
|
golang.org/x/text v0.14.0/go.mod h1:18ZOQIKpY8NJVqYksKHtTdi31H5itFRjB5/qKTNYzSU=
|
||||||
|
golang.org/x/text v0.15.0/go.mod h1:18ZOQIKpY8NJVqYksKHtTdi31H5itFRjB5/qKTNYzSU=
|
||||||
|
golang.org/x/tools v0.0.0-20180917221912-90fa682c2a6e/go.mod h1:n7NCudcB/nEzxVGmLbDWY5pfWTLqBcC2KZ6jyYvM4mQ=
|
||||||
|
golang.org/x/tools v0.0.0-20191119224855-298f0cb1881e/go.mod h1:b+2E5dAYhXwXZwtnZ6UAqBI28+e2cm9otk0dWdXHAEo=
|
||||||
|
golang.org/x/tools v0.1.12/go.mod h1:hNGJHUnrk76NpqgfD5Aqm5Crs+Hm0VOH/i9J2+nxYbc=
|
||||||
|
golang.org/x/tools v0.6.0/go.mod h1:Xwgl3UAJ/d3gWutnCtw505GrjyAbvKui8lOU390QaIU=
|
||||||
|
golang.org/x/xerrors v0.0.0-20190717185122-a985d3407aa7/go.mod h1:I/5z698sn9Ka8TeJc9MKroUUfqBBauWjQqLJ2OPfmY0=
|
||||||
|
gopkg.in/check.v1 v0.0.0-20161208181325-20d25e280405/go.mod h1:Co6ibVJAznAaIkqp8huTwlJQCZ016jof/cbN4VW5Yz0=
|
||||||
|
gopkg.in/check.v1 v1.0.0-20180628173108-788fd7840127/go.mod h1:Co6ibVJAznAaIkqp8huTwlJQCZ016jof/cbN4VW5Yz0=
|
||||||
|
gopkg.in/check.v1 v1.0.0-20190902080502-41f04d3bba15/go.mod h1:Co6ibVJAznAaIkqp8huTwlJQCZ016jof/cbN4VW5Yz0=
|
||||||
|
gopkg.in/check.v1 v1.0.0-20201130134442-10cb98267c6c h1:Hei/4ADfdWqJk1ZMxUNpqntNwaWcugrBjAiHlqqRiVk=
|
||||||
|
gopkg.in/check.v1 v1.0.0-20201130134442-10cb98267c6c/go.mod h1:JHkPIbrfpd72SG/EVd6muEfDQjcINNoR0C8j2r3qZ4Q=
|
||||||
|
gopkg.in/errgo.v2 v2.1.0/go.mod h1:hNsd1EY+bozCKY1Ytp96fpM3vjJbqLJn88ws8XvfDNI=
|
||||||
|
gopkg.in/yaml.v2 v2.2.2/go.mod h1:hI93XBmqTisBFMUTm0b8Fm+jr3Dg1NNxqwp+5A1VGuI=
|
||||||
|
gopkg.in/yaml.v2 v2.4.0 h1:D8xgwECY7CYvx+Y2n4sBz93Jn9JRvxdiyyo8CTfuKaY=
|
||||||
|
gopkg.in/yaml.v2 v2.4.0/go.mod h1:RDklbk79AGWmwhnvt/jBztapEOGDOx6ZbXqjP6csGnQ=
|
||||||
25
apps/api/src/lib/go-html-to-md/html-to-markdown.go
Normal file
25
apps/api/src/lib/go-html-to-md/html-to-markdown.go
Normal file
|
|
@ -0,0 +1,25 @@
|
||||||
|
package main
|
||||||
|
|
||||||
|
import (
|
||||||
|
"C"
|
||||||
|
"log"
|
||||||
|
|
||||||
|
md "github.com/JohannesKaufmann/html-to-markdown"
|
||||||
|
"github.com/JohannesKaufmann/html-to-markdown/plugin"
|
||||||
|
)
|
||||||
|
|
||||||
|
//export ConvertHTMLToMarkdown
|
||||||
|
func ConvertHTMLToMarkdown(html *C.char) *C.char {
|
||||||
|
converter := md.NewConverter("", true, nil)
|
||||||
|
converter.Use(plugin.GitHubFlavored())
|
||||||
|
|
||||||
|
markdown, err := converter.ConvertString(C.GoString(html))
|
||||||
|
if err != nil {
|
||||||
|
log.Fatal(err)
|
||||||
|
}
|
||||||
|
return C.CString(markdown)
|
||||||
|
}
|
||||||
|
|
||||||
|
func main() {
|
||||||
|
// This function is required for the main package
|
||||||
|
}
|
||||||
|
|
@ -1,8 +1,68 @@
|
||||||
|
|
||||||
export async function parseMarkdown(html: string) {
|
import koffi from 'koffi';
|
||||||
|
import { join } from 'path';
|
||||||
|
import "../services/sentry"
|
||||||
|
import * as Sentry from "@sentry/node";
|
||||||
|
|
||||||
|
import dotenv from 'dotenv';
|
||||||
|
import { Logger } from './logger';
|
||||||
|
dotenv.config();
|
||||||
|
|
||||||
|
// TODO: add a timeout to the Go parser
|
||||||
|
|
||||||
|
class GoMarkdownConverter {
|
||||||
|
private static instance: GoMarkdownConverter;
|
||||||
|
private convert: any;
|
||||||
|
|
||||||
|
private constructor() {
|
||||||
|
const goExecutablePath = join(__dirname, 'go-html-to-md/html-to-markdown.so');
|
||||||
|
const lib = koffi.load(goExecutablePath);
|
||||||
|
this.convert = lib.func('ConvertHTMLToMarkdown', 'string', ['string']);
|
||||||
|
}
|
||||||
|
|
||||||
|
public static getInstance(): GoMarkdownConverter {
|
||||||
|
if (!GoMarkdownConverter.instance) {
|
||||||
|
GoMarkdownConverter.instance = new GoMarkdownConverter();
|
||||||
|
}
|
||||||
|
return GoMarkdownConverter.instance;
|
||||||
|
}
|
||||||
|
|
||||||
|
public async convertHTMLToMarkdown(html: string): Promise<string> {
|
||||||
|
return new Promise<string>((resolve, reject) => {
|
||||||
|
this.convert.async(html, (err: Error, res: string) => {
|
||||||
|
if (err) {
|
||||||
|
reject(err);
|
||||||
|
} else {
|
||||||
|
resolve(res);
|
||||||
|
}
|
||||||
|
});
|
||||||
|
});
|
||||||
|
}
|
||||||
|
}
|
||||||
|
|
||||||
|
export async function parseMarkdown(html: string): Promise<string> {
|
||||||
|
if (!html) {
|
||||||
|
return '';
|
||||||
|
}
|
||||||
|
|
||||||
|
try {
|
||||||
|
if (process.env.USE_GO_MARKDOWN_PARSER == "true") {
|
||||||
|
const converter = GoMarkdownConverter.getInstance();
|
||||||
|
let markdownContent = await converter.convertHTMLToMarkdown(html);
|
||||||
|
|
||||||
|
markdownContent = processMultiLineLinks(markdownContent);
|
||||||
|
markdownContent = removeSkipToContentLinks(markdownContent);
|
||||||
|
Logger.info(`HTML to Markdown conversion using Go parser successful`);
|
||||||
|
return markdownContent;
|
||||||
|
}
|
||||||
|
} catch (error) {
|
||||||
|
Sentry.captureException(error);
|
||||||
|
Logger.error(`Error converting HTML to Markdown with Go parser: ${error}`);
|
||||||
|
}
|
||||||
|
|
||||||
|
// Fallback to TurndownService if Go parser fails or is not enabled
|
||||||
var TurndownService = require("turndown");
|
var TurndownService = require("turndown");
|
||||||
var turndownPluginGfm = require('joplin-turndown-plugin-gfm')
|
var turndownPluginGfm = require('joplin-turndown-plugin-gfm');
|
||||||
|
|
||||||
|
|
||||||
const turndownService = new TurndownService();
|
const turndownService = new TurndownService();
|
||||||
turndownService.addRule("inlineLink", {
|
turndownService.addRule("inlineLink", {
|
||||||
|
|
@ -21,29 +81,20 @@ export async function parseMarkdown(html: string) {
|
||||||
});
|
});
|
||||||
var gfm = turndownPluginGfm.gfm;
|
var gfm = turndownPluginGfm.gfm;
|
||||||
turndownService.use(gfm);
|
turndownService.use(gfm);
|
||||||
let markdownContent = "";
|
|
||||||
const turndownPromise = new Promise<string>((resolve, reject) => {
|
|
||||||
try {
|
|
||||||
const result = turndownService.turndown(html);
|
|
||||||
resolve(result);
|
|
||||||
} catch (error) {
|
|
||||||
reject("Error converting HTML to Markdown: " + error);
|
|
||||||
}
|
|
||||||
});
|
|
||||||
|
|
||||||
const timeoutPromise = new Promise<string>((resolve, reject) => {
|
|
||||||
const timeout = 5000; // Timeout in milliseconds
|
|
||||||
setTimeout(() => reject("Conversion timed out after " + timeout + "ms"), timeout);
|
|
||||||
});
|
|
||||||
|
|
||||||
try {
|
try {
|
||||||
markdownContent = await Promise.race([turndownPromise, timeoutPromise]);
|
let markdownContent = await turndownService.turndown(html);
|
||||||
|
markdownContent = processMultiLineLinks(markdownContent);
|
||||||
|
markdownContent = removeSkipToContentLinks(markdownContent);
|
||||||
|
|
||||||
|
return markdownContent;
|
||||||
} catch (error) {
|
} catch (error) {
|
||||||
console.error(error);
|
console.error("Error converting HTML to Markdown: ", error);
|
||||||
return ""; // Optionally return an empty string or handle the error as needed
|
return ""; // Optionally return an empty string or handle the error as needed
|
||||||
}
|
}
|
||||||
|
}
|
||||||
|
|
||||||
// multiple line links
|
function processMultiLineLinks(markdownContent: string): string {
|
||||||
let insideLinkContent = false;
|
let insideLinkContent = false;
|
||||||
let newMarkdownContent = "";
|
let newMarkdownContent = "";
|
||||||
let linkOpenCount = 0;
|
let linkOpenCount = 0;
|
||||||
|
|
@ -63,12 +114,14 @@ export async function parseMarkdown(html: string) {
|
||||||
newMarkdownContent += char;
|
newMarkdownContent += char;
|
||||||
}
|
}
|
||||||
}
|
}
|
||||||
markdownContent = newMarkdownContent;
|
return newMarkdownContent;
|
||||||
|
}
|
||||||
|
|
||||||
|
function removeSkipToContentLinks(markdownContent: string): string {
|
||||||
// Remove [Skip to Content](#page) and [Skip to content](#skip)
|
// Remove [Skip to Content](#page) and [Skip to content](#skip)
|
||||||
markdownContent = markdownContent.replace(
|
const newMarkdownContent = markdownContent.replace(
|
||||||
/\[Skip to Content\]\(#[^\)]*\)/gi,
|
/\[Skip to Content\]\(#[^\)]*\)/gi,
|
||||||
""
|
""
|
||||||
);
|
);
|
||||||
return markdownContent;
|
return newMarkdownContent;
|
||||||
}
|
}
|
||||||
|
|
@ -1,3 +1,6 @@
|
||||||
|
import { configDotenv } from "dotenv";
|
||||||
|
configDotenv();
|
||||||
|
|
||||||
enum LogLevel {
|
enum LogLevel {
|
||||||
NONE = 'NONE', // No logs will be output.
|
NONE = 'NONE', // No logs will be output.
|
||||||
ERROR = 'ERROR', // For logging error messages that indicate a failure in a specific operation.
|
ERROR = 'ERROR', // For logging error messages that indicate a failure in a specific operation.
|
||||||
|
|
|
||||||
|
|
@ -2,6 +2,8 @@ import { Job } from "bullmq";
|
||||||
import type { baseScrapers } from "../scraper/WebScraper/single_url";
|
import type { baseScrapers } from "../scraper/WebScraper/single_url";
|
||||||
import { supabase_service as supabase } from "../services/supabase";
|
import { supabase_service as supabase } from "../services/supabase";
|
||||||
import { Logger } from "./logger";
|
import { Logger } from "./logger";
|
||||||
|
import { configDotenv } from "dotenv";
|
||||||
|
configDotenv();
|
||||||
|
|
||||||
export type ScrapeErrorEvent = {
|
export type ScrapeErrorEvent = {
|
||||||
type: "error",
|
type: "error",
|
||||||
|
|
|
||||||
|
|
@ -2,6 +2,11 @@ import { supabase_service } from "../services/supabase";
|
||||||
import { Logger } from "./logger";
|
import { Logger } from "./logger";
|
||||||
import * as Sentry from "@sentry/node";
|
import * as Sentry from "@sentry/node";
|
||||||
|
|
||||||
|
/**
|
||||||
|
* Get a single firecrawl_job by ID
|
||||||
|
* @param jobId ID of Job
|
||||||
|
* @returns {any | null} Job
|
||||||
|
*/
|
||||||
export const supabaseGetJobById = async (jobId: string) => {
|
export const supabaseGetJobById = async (jobId: string) => {
|
||||||
const { data, error } = await supabase_service
|
const { data, error } = await supabase_service
|
||||||
.from("firecrawl_jobs")
|
.from("firecrawl_jobs")
|
||||||
|
|
@ -20,13 +25,43 @@ export const supabaseGetJobById = async (jobId: string) => {
|
||||||
return data;
|
return data;
|
||||||
};
|
};
|
||||||
|
|
||||||
|
/**
|
||||||
|
* Get multiple firecrawl_jobs by ID. Use this if you're not requesting a lot (50+) of jobs at once.
|
||||||
|
* @param jobIds IDs of Jobs
|
||||||
|
* @returns {any[]} Jobs
|
||||||
|
*/
|
||||||
export const supabaseGetJobsById = async (jobIds: string[]) => {
|
export const supabaseGetJobsById = async (jobIds: string[]) => {
|
||||||
const { data, error } = await supabase_service.rpc("get_jobs_by_ids", {
|
const { data, error } = await supabase_service
|
||||||
job_ids: jobIds,
|
.from("firecrawl_jobs")
|
||||||
});
|
.select()
|
||||||
|
.in("job_id", jobIds);
|
||||||
|
|
||||||
if (error) {
|
if (error) {
|
||||||
Logger.error(`Error in get_jobs_by_ids: ${error}`);
|
Logger.error(`Error in supabaseGetJobsById: ${error}`);
|
||||||
|
Sentry.captureException(error);
|
||||||
|
return [];
|
||||||
|
}
|
||||||
|
|
||||||
|
if (!data) {
|
||||||
|
return [];
|
||||||
|
}
|
||||||
|
|
||||||
|
return data;
|
||||||
|
};
|
||||||
|
|
||||||
|
/**
|
||||||
|
* Get multiple firecrawl_jobs by crawl ID. Use this if you need a lot of jobs at once.
|
||||||
|
* @param crawlId ID of crawl
|
||||||
|
* @returns {any[]} Jobs
|
||||||
|
*/
|
||||||
|
export const supabaseGetJobsByCrawlId = async (crawlId: string) => {
|
||||||
|
const { data, error } = await supabase_service
|
||||||
|
.from("firecrawl_jobs")
|
||||||
|
.select()
|
||||||
|
.eq("crawl_id", crawlId)
|
||||||
|
|
||||||
|
if (error) {
|
||||||
|
Logger.error(`Error in supabaseGetJobsByCrawlId: ${error}`);
|
||||||
Sentry.captureException(error);
|
Sentry.captureException(error);
|
||||||
return [];
|
return [];
|
||||||
}
|
}
|
||||||
|
|
|
||||||
|
|
@ -1,6 +1,8 @@
|
||||||
import { AuthResponse } from "../../src/types";
|
import { AuthResponse } from "../../src/types";
|
||||||
import { Logger } from "./logger";
|
import { Logger } from "./logger";
|
||||||
import * as Sentry from "@sentry/node";
|
import * as Sentry from "@sentry/node";
|
||||||
|
import { configDotenv } from "dotenv";
|
||||||
|
configDotenv();
|
||||||
|
|
||||||
let warningCount = 0;
|
let warningCount = 0;
|
||||||
|
|
||||||
|
|
|
||||||
|
|
@ -12,6 +12,8 @@ import { Document } from "../lib/entities";
|
||||||
import { supabase_service } from "../services/supabase";
|
import { supabase_service } from "../services/supabase";
|
||||||
import { Logger } from "../lib/logger";
|
import { Logger } from "../lib/logger";
|
||||||
import { ScrapeEvents } from "../lib/scrape-events";
|
import { ScrapeEvents } from "../lib/scrape-events";
|
||||||
|
import { configDotenv } from "dotenv";
|
||||||
|
configDotenv();
|
||||||
|
|
||||||
export async function startWebScraperPipeline({
|
export async function startWebScraperPipeline({
|
||||||
job,
|
job,
|
||||||
|
|
|
||||||
|
|
@ -83,7 +83,7 @@ function idempotencyMiddleware(req: Request, res: Response, next: NextFunction)
|
||||||
}
|
}
|
||||||
|
|
||||||
function blocklistMiddleware(req: Request, res: Response, next: NextFunction) {
|
function blocklistMiddleware(req: Request, res: Response, next: NextFunction) {
|
||||||
if (req.body.url && isUrlBlocked(req.body.url)) {
|
if (typeof req.body.url === "string" && isUrlBlocked(req.body.url)) {
|
||||||
if (!res.headersSent) {
|
if (!res.headersSent) {
|
||||||
return res.status(403).json({ success: false, error: "URL is blocked. Firecrawl currently does not support social media scraping due to policy restrictions." });
|
return res.status(403).json({ success: false, error: "URL is blocked. Firecrawl currently does not support social media scraping due to policy restrictions." });
|
||||||
}
|
}
|
||||||
|
|
|
||||||
|
|
@ -589,6 +589,9 @@ export class WebScraperDataProvider {
|
||||||
includeLinks: options.pageOptions?.includeLinks ?? true,
|
includeLinks: options.pageOptions?.includeLinks ?? true,
|
||||||
fullPageScreenshot: options.pageOptions?.fullPageScreenshot ?? false,
|
fullPageScreenshot: options.pageOptions?.fullPageScreenshot ?? false,
|
||||||
screenshot: options.pageOptions?.screenshot ?? false,
|
screenshot: options.pageOptions?.screenshot ?? false,
|
||||||
|
useFastMode: options.pageOptions?.useFastMode ?? false,
|
||||||
|
disableJsDom: options.pageOptions?.disableJsDom ?? false,
|
||||||
|
atsv: options.pageOptions?.atsv ?? false
|
||||||
};
|
};
|
||||||
this.extractorOptions = options.extractorOptions ?? { mode: "markdown" };
|
this.extractorOptions = options.extractorOptions ?? { mode: "markdown" };
|
||||||
this.replaceAllPathsWithAbsolutePaths =
|
this.replaceAllPathsWithAbsolutePaths =
|
||||||
|
|
|
||||||
|
|
@ -55,7 +55,7 @@ export async function scrapWithFireEngine({
|
||||||
try {
|
try {
|
||||||
const reqParams = await generateRequestParams(url);
|
const reqParams = await generateRequestParams(url);
|
||||||
let waitParam = reqParams["params"]?.wait ?? waitFor;
|
let waitParam = reqParams["params"]?.wait ?? waitFor;
|
||||||
let engineParam = reqParams["params"]?.engine ?? reqParams["params"]?.fireEngineOptions?.engine ?? fireEngineOptions?.engine ?? "playwright";
|
let engineParam = reqParams["params"]?.engine ?? reqParams["params"]?.fireEngineOptions?.engine ?? fireEngineOptions?.engine ?? "chrome-cdp";
|
||||||
let screenshotParam = reqParams["params"]?.screenshot ?? screenshot;
|
let screenshotParam = reqParams["params"]?.screenshot ?? screenshot;
|
||||||
let fullPageScreenshotParam = reqParams["params"]?.fullPageScreenshot ?? fullPageScreenshot;
|
let fullPageScreenshotParam = reqParams["params"]?.fullPageScreenshot ?? fullPageScreenshot;
|
||||||
let fireEngineOptionsParam : FireEngineOptions = reqParams["params"]?.fireEngineOptions ?? fireEngineOptions;
|
let fireEngineOptionsParam : FireEngineOptions = reqParams["params"]?.fireEngineOptions ?? fireEngineOptions;
|
||||||
|
|
@ -69,15 +69,15 @@ export async function scrapWithFireEngine({
|
||||||
|
|
||||||
let engine = engineParam; // do we want fireEngineOptions as first choice?
|
let engine = engineParam; // do we want fireEngineOptions as first choice?
|
||||||
|
|
||||||
Logger.info(
|
|
||||||
`⛏️ Fire-Engine (${engine}): Scraping ${url} | params: { wait: ${waitParam}, screenshot: ${screenshotParam}, fullPageScreenshot: ${fullPageScreenshot}, method: ${fireEngineOptionsParam?.method ?? "null"} }`
|
|
||||||
);
|
|
||||||
|
|
||||||
if (pageOptions?.useFastMode) {
|
if (pageOptions?.useFastMode) {
|
||||||
fireEngineOptionsParam.engine = "tlsclient";
|
fireEngineOptionsParam.engine = "tlsclient";
|
||||||
engine = "tlsclient";
|
engine = "tlsclient";
|
||||||
}
|
}
|
||||||
|
|
||||||
|
Logger.info(
|
||||||
|
`⛏️ Fire-Engine (${engine}): Scraping ${url} | params: { wait: ${waitParam}, screenshot: ${screenshotParam}, fullPageScreenshot: ${fullPageScreenshot}, method: ${fireEngineOptionsParam?.method ?? "null"} }`
|
||||||
|
);
|
||||||
|
|
||||||
// atsv is only available for beta customers
|
// atsv is only available for beta customers
|
||||||
const betaCustomersString = process.env.BETA_CUSTOMERS;
|
const betaCustomersString = process.env.BETA_CUSTOMERS;
|
||||||
const betaCustomers = betaCustomersString ? betaCustomersString.split(",") : [];
|
const betaCustomers = betaCustomersString ? betaCustomersString.split(",") : [];
|
||||||
|
|
@ -96,6 +96,7 @@ export async function scrapWithFireEngine({
|
||||||
const _response = await Sentry.startSpan({
|
const _response = await Sentry.startSpan({
|
||||||
name: "Call to fire-engine"
|
name: "Call to fire-engine"
|
||||||
}, async span => {
|
}, async span => {
|
||||||
|
|
||||||
return await axiosInstance.post(
|
return await axiosInstance.post(
|
||||||
process.env.FIRE_ENGINE_BETA_URL + endpoint,
|
process.env.FIRE_ENGINE_BETA_URL + endpoint,
|
||||||
{
|
{
|
||||||
|
|
@ -104,12 +105,13 @@ export async function scrapWithFireEngine({
|
||||||
screenshot: screenshotParam,
|
screenshot: screenshotParam,
|
||||||
fullPageScreenshot: fullPageScreenshotParam,
|
fullPageScreenshot: fullPageScreenshotParam,
|
||||||
headers: headers,
|
headers: headers,
|
||||||
pageOptions: pageOptions,
|
|
||||||
disableJsDom: pageOptions?.disableJsDom ?? false,
|
disableJsDom: pageOptions?.disableJsDom ?? false,
|
||||||
priority,
|
priority,
|
||||||
engine,
|
engine,
|
||||||
instantReturn: true,
|
instantReturn: true,
|
||||||
...fireEngineOptionsParam,
|
...fireEngineOptionsParam,
|
||||||
|
atsv: pageOptions?.atsv ?? false,
|
||||||
|
scrollXPaths: pageOptions?.scrollXPaths ?? [],
|
||||||
},
|
},
|
||||||
{
|
{
|
||||||
headers: {
|
headers: {
|
||||||
|
|
@ -125,7 +127,7 @@ export async function scrapWithFireEngine({
|
||||||
|
|
||||||
let checkStatusResponse = await axiosInstance.get(`${process.env.FIRE_ENGINE_BETA_URL}/scrape/${_response.data.jobId}`);
|
let checkStatusResponse = await axiosInstance.get(`${process.env.FIRE_ENGINE_BETA_URL}/scrape/${_response.data.jobId}`);
|
||||||
while (checkStatusResponse.data.processing && Date.now() - startTime < universalTimeout + waitParam) {
|
while (checkStatusResponse.data.processing && Date.now() - startTime < universalTimeout + waitParam) {
|
||||||
await new Promise(resolve => setTimeout(resolve, 1000)); // wait 1 second
|
await new Promise(resolve => setTimeout(resolve, 250)); // wait 0.25 seconds
|
||||||
checkStatusResponse = await axiosInstance.get(`${process.env.FIRE_ENGINE_BETA_URL}/scrape/${_response.data.jobId}`);
|
checkStatusResponse = await axiosInstance.get(`${process.env.FIRE_ENGINE_BETA_URL}/scrape/${_response.data.jobId}`);
|
||||||
}
|
}
|
||||||
|
|
||||||
|
|
|
||||||
|
|
@ -28,8 +28,8 @@ const useFireEngine = process.env.FIRE_ENGINE_BETA_URL !== '' && process.env.FIR
|
||||||
|
|
||||||
export const baseScrapers = [
|
export const baseScrapers = [
|
||||||
useFireEngine ? "fire-engine;chrome-cdp" : undefined,
|
useFireEngine ? "fire-engine;chrome-cdp" : undefined,
|
||||||
useFireEngine ? "fire-engine" : undefined,
|
|
||||||
useScrapingBee ? "scrapingBee" : undefined,
|
useScrapingBee ? "scrapingBee" : undefined,
|
||||||
|
useFireEngine ? "fire-engine" : undefined,
|
||||||
useFireEngine ? undefined : "playwright",
|
useFireEngine ? undefined : "playwright",
|
||||||
useScrapingBee ? "scrapingBeeLoad" : undefined,
|
useScrapingBee ? "scrapingBeeLoad" : undefined,
|
||||||
"fetch",
|
"fetch",
|
||||||
|
|
@ -89,22 +89,22 @@ function getScrapingFallbackOrder(
|
||||||
|
|
||||||
let defaultOrder = [
|
let defaultOrder = [
|
||||||
useFireEngine ? "fire-engine;chrome-cdp" : undefined,
|
useFireEngine ? "fire-engine;chrome-cdp" : undefined,
|
||||||
useFireEngine ? "fire-engine" : undefined,
|
|
||||||
useScrapingBee ? "scrapingBee" : undefined,
|
useScrapingBee ? "scrapingBee" : undefined,
|
||||||
|
useFireEngine ? "fire-engine" : undefined,
|
||||||
useScrapingBee ? "scrapingBeeLoad" : undefined,
|
useScrapingBee ? "scrapingBeeLoad" : undefined,
|
||||||
useFireEngine ? undefined : "playwright",
|
useFireEngine ? undefined : "playwright",
|
||||||
"fetch",
|
"fetch",
|
||||||
].filter(Boolean);
|
].filter(Boolean);
|
||||||
|
|
||||||
if (isWaitPresent || isScreenshotPresent || isHeadersPresent) {
|
// if (isWaitPresent || isScreenshotPresent || isHeadersPresent) {
|
||||||
defaultOrder = [
|
// defaultOrder = [
|
||||||
"fire-engine",
|
// "fire-engine",
|
||||||
useFireEngine ? undefined : "playwright",
|
// useFireEngine ? undefined : "playwright",
|
||||||
...defaultOrder.filter(
|
// ...defaultOrder.filter(
|
||||||
(scraper) => scraper !== "fire-engine" && scraper !== "playwright"
|
// (scraper) => scraper !== "fire-engine" && scraper !== "playwright"
|
||||||
),
|
// ),
|
||||||
].filter(Boolean);
|
// ].filter(Boolean);
|
||||||
}
|
// }
|
||||||
|
|
||||||
const filteredDefaultOrder = defaultOrder.filter(
|
const filteredDefaultOrder = defaultOrder.filter(
|
||||||
(scraper: (typeof baseScrapers)[number]) =>
|
(scraper: (typeof baseScrapers)[number]) =>
|
||||||
|
|
@ -146,6 +146,9 @@ export async function scrapSingleUrl(
|
||||||
parsePDF: pageOptions.parsePDF ?? true,
|
parsePDF: pageOptions.parsePDF ?? true,
|
||||||
removeTags: pageOptions.removeTags ?? [],
|
removeTags: pageOptions.removeTags ?? [],
|
||||||
onlyIncludeTags: pageOptions.onlyIncludeTags ?? [],
|
onlyIncludeTags: pageOptions.onlyIncludeTags ?? [],
|
||||||
|
useFastMode: pageOptions.useFastMode ?? false,
|
||||||
|
disableJsDom: pageOptions.disableJsDom ?? false,
|
||||||
|
atsv: pageOptions.atsv ?? false
|
||||||
}
|
}
|
||||||
|
|
||||||
if (extractorOptions) {
|
if (extractorOptions) {
|
||||||
|
|
@ -200,6 +203,7 @@ export async function scrapSingleUrl(
|
||||||
fireEngineOptions: {
|
fireEngineOptions: {
|
||||||
engine: engine,
|
engine: engine,
|
||||||
atsv: pageOptions.atsv,
|
atsv: pageOptions.atsv,
|
||||||
|
disableJsDom: pageOptions.disableJsDom,
|
||||||
},
|
},
|
||||||
priority,
|
priority,
|
||||||
teamId,
|
teamId,
|
||||||
|
|
|
||||||
|
|
@ -36,17 +36,15 @@ export async function getLinksFromSitemap(
|
||||||
const root = parsed.urlset || parsed.sitemapindex;
|
const root = parsed.urlset || parsed.sitemapindex;
|
||||||
|
|
||||||
if (root && root.sitemap) {
|
if (root && root.sitemap) {
|
||||||
for (const sitemap of root.sitemap) {
|
const sitemapPromises = root.sitemap
|
||||||
if (sitemap.loc && sitemap.loc.length > 0) {
|
.filter(sitemap => sitemap.loc && sitemap.loc.length > 0)
|
||||||
await getLinksFromSitemap({ sitemapUrl: sitemap.loc[0], allUrls, mode });
|
.map(sitemap => getLinksFromSitemap({ sitemapUrl: sitemap.loc[0], allUrls, mode }));
|
||||||
}
|
await Promise.all(sitemapPromises);
|
||||||
}
|
|
||||||
} else if (root && root.url) {
|
} else if (root && root.url) {
|
||||||
for (const url of root.url) {
|
const validUrls = root.url
|
||||||
if (url.loc && url.loc.length > 0 && !WebCrawler.prototype.isFile(url.loc[0])) {
|
.filter(url => url.loc && url.loc.length > 0 && !WebCrawler.prototype.isFile(url.loc[0]))
|
||||||
allUrls.push(url.loc[0]);
|
.map(url => url.loc[0]);
|
||||||
}
|
allUrls.push(...validUrls);
|
||||||
}
|
|
||||||
}
|
}
|
||||||
} catch (error) {
|
} catch (error) {
|
||||||
Logger.debug(`Error processing sitemapUrl: ${sitemapUrl} | Error: ${error.message}`);
|
Logger.debug(`Error processing sitemapUrl: ${sitemapUrl} | Error: ${error.message}`);
|
||||||
|
|
|
||||||
|
|
@ -242,5 +242,13 @@ export const urlSpecificParams = {
|
||||||
engine: "chrome-cdp",
|
engine: "chrome-cdp",
|
||||||
},
|
},
|
||||||
},
|
},
|
||||||
|
},
|
||||||
|
"lorealparis.hu":{
|
||||||
|
defaultScraper: "fire-engine",
|
||||||
|
params:{
|
||||||
|
fireEngineOptions:{
|
||||||
|
engine: "tlsclient",
|
||||||
|
},
|
||||||
|
},
|
||||||
}
|
}
|
||||||
};
|
};
|
||||||
|
|
|
||||||
|
|
@ -39,16 +39,8 @@ export const excludeNonMainTags = [
|
||||||
"#search",
|
"#search",
|
||||||
".share",
|
".share",
|
||||||
"#share",
|
"#share",
|
||||||
".pagination",
|
|
||||||
"#pagination",
|
|
||||||
".widget",
|
".widget",
|
||||||
"#widget",
|
"#widget",
|
||||||
".related",
|
|
||||||
"#related",
|
|
||||||
".tag",
|
|
||||||
"#tag",
|
|
||||||
".category",
|
|
||||||
"#category",
|
|
||||||
".cookie",
|
".cookie",
|
||||||
"#cookie"
|
"#cookie"
|
||||||
];
|
];
|
||||||
|
|
|
||||||
|
|
@ -1,10 +1,14 @@
|
||||||
import axios from "axios";
|
import axios from "axios";
|
||||||
import dotenv from "dotenv";
|
import dotenv from "dotenv";
|
||||||
import { SearchResult } from "../../src/lib/entities";
|
import { SearchResult } from "../../src/lib/entities";
|
||||||
|
import * as Sentry from "@sentry/node";
|
||||||
|
import { Logger } from "../lib/logger";
|
||||||
|
|
||||||
dotenv.config();
|
dotenv.config();
|
||||||
|
|
||||||
export async function fireEngineMap(q: string, options: {
|
export async function fireEngineMap(
|
||||||
|
q: string,
|
||||||
|
options: {
|
||||||
tbs?: string;
|
tbs?: string;
|
||||||
filter?: string;
|
filter?: string;
|
||||||
lang?: string;
|
lang?: string;
|
||||||
|
|
@ -12,34 +16,43 @@ export async function fireEngineMap(q: string, options: {
|
||||||
location?: string;
|
location?: string;
|
||||||
numResults: number;
|
numResults: number;
|
||||||
page?: number;
|
page?: number;
|
||||||
}): Promise<SearchResult[]> {
|
|
||||||
let data = JSON.stringify({
|
|
||||||
query: q,
|
|
||||||
lang: options.lang,
|
|
||||||
country: options.country,
|
|
||||||
location: options.location,
|
|
||||||
tbs: options.tbs,
|
|
||||||
numResults: options.numResults,
|
|
||||||
page: options.page ?? 1,
|
|
||||||
});
|
|
||||||
|
|
||||||
if (!process.env.FIRE_ENGINE_BETA_URL) {
|
|
||||||
console.warn("(v1/map Beta) Results might differ from cloud offering currently.");
|
|
||||||
return [];
|
|
||||||
}
|
}
|
||||||
|
): Promise<SearchResult[]> {
|
||||||
|
try {
|
||||||
|
let data = JSON.stringify({
|
||||||
|
query: q,
|
||||||
|
lang: options.lang,
|
||||||
|
country: options.country,
|
||||||
|
location: options.location,
|
||||||
|
tbs: options.tbs,
|
||||||
|
numResults: options.numResults,
|
||||||
|
page: options.page ?? 1,
|
||||||
|
});
|
||||||
|
|
||||||
let config = {
|
if (!process.env.FIRE_ENGINE_BETA_URL) {
|
||||||
method: "POST",
|
console.warn(
|
||||||
url: `${process.env.FIRE_ENGINE_BETA_URL}/search`,
|
"(v1/map Beta) Results might differ from cloud offering currently."
|
||||||
headers: {
|
);
|
||||||
"Content-Type": "application/json",
|
return [];
|
||||||
},
|
}
|
||||||
data: data,
|
|
||||||
};
|
let config = {
|
||||||
const response = await axios(config);
|
method: "POST",
|
||||||
if (response && response) {
|
url: `${process.env.FIRE_ENGINE_BETA_URL}/search`,
|
||||||
return response.data
|
headers: {
|
||||||
} else {
|
"Content-Type": "application/json",
|
||||||
|
},
|
||||||
|
data: data,
|
||||||
|
};
|
||||||
|
const response = await axios(config);
|
||||||
|
if (response && response) {
|
||||||
|
return response.data;
|
||||||
|
} else {
|
||||||
|
return [];
|
||||||
|
}
|
||||||
|
} catch (error) {
|
||||||
|
Logger.error(error);
|
||||||
|
Sentry.captureException(error);
|
||||||
return [];
|
return [];
|
||||||
}
|
}
|
||||||
}
|
}
|
||||||
|
|
|
||||||
|
|
@ -5,7 +5,7 @@ import { supabase_service } from "../supabase";
|
||||||
import { Logger } from "../../lib/logger";
|
import { Logger } from "../../lib/logger";
|
||||||
import { getValue, setValue } from "../redis";
|
import { getValue, setValue } from "../redis";
|
||||||
import { redlock } from "../redlock";
|
import { redlock } from "../redlock";
|
||||||
|
import * as Sentry from "@sentry/node";
|
||||||
|
|
||||||
const FREE_CREDITS = 500;
|
const FREE_CREDITS = 500;
|
||||||
|
|
||||||
|
|
@ -176,9 +176,25 @@ export async function supaCheckTeamCredits(team_id: string, credits: number) {
|
||||||
return { success: true, message: "Preview team, no credits used", remainingCredits: Infinity };
|
return { success: true, message: "Preview team, no credits used", remainingCredits: Infinity };
|
||||||
}
|
}
|
||||||
|
|
||||||
// Retrieve the team's active subscription and check for available coupons concurrently
|
|
||||||
const [{ data: subscription, error: subscriptionError }, { data: coupons }] =
|
let cacheKeySubscription = `subscription_${team_id}`;
|
||||||
await Promise.all([
|
let cacheKeyCoupons = `coupons_${team_id}`;
|
||||||
|
|
||||||
|
// Try to get data from cache first
|
||||||
|
const [cachedSubscription, cachedCoupons] = await Promise.all([
|
||||||
|
getValue(cacheKeySubscription),
|
||||||
|
getValue(cacheKeyCoupons)
|
||||||
|
]);
|
||||||
|
|
||||||
|
let subscription, subscriptionError;
|
||||||
|
let coupons : {credits: number}[];
|
||||||
|
|
||||||
|
if (cachedSubscription && cachedCoupons) {
|
||||||
|
subscription = JSON.parse(cachedSubscription);
|
||||||
|
coupons = JSON.parse(cachedCoupons);
|
||||||
|
} else {
|
||||||
|
// If not in cache, retrieve from database
|
||||||
|
const [subscriptionResult, couponsResult] = await Promise.all([
|
||||||
supabase_service
|
supabase_service
|
||||||
.from("subscriptions")
|
.from("subscriptions")
|
||||||
.select("id, price_id, current_period_start, current_period_end")
|
.select("id, price_id, current_period_start, current_period_end")
|
||||||
|
|
@ -192,6 +208,16 @@ export async function supaCheckTeamCredits(team_id: string, credits: number) {
|
||||||
.eq("status", "active"),
|
.eq("status", "active"),
|
||||||
]);
|
]);
|
||||||
|
|
||||||
|
subscription = subscriptionResult.data;
|
||||||
|
subscriptionError = subscriptionResult.error;
|
||||||
|
coupons = couponsResult.data;
|
||||||
|
|
||||||
|
// Cache the results for a minute, sub can be null and that's fine
|
||||||
|
await setValue(cacheKeySubscription, JSON.stringify(subscription), 60); // Cache for 1 minute, even if null
|
||||||
|
await setValue(cacheKeyCoupons, JSON.stringify(coupons), 60); // Cache for 1 minute
|
||||||
|
|
||||||
|
}
|
||||||
|
|
||||||
let couponCredits = 0;
|
let couponCredits = 0;
|
||||||
if (coupons && coupons.length > 0) {
|
if (coupons && coupons.length > 0) {
|
||||||
couponCredits = coupons.reduce(
|
couponCredits = coupons.reduce(
|
||||||
|
|
@ -200,53 +226,67 @@ export async function supaCheckTeamCredits(team_id: string, credits: number) {
|
||||||
);
|
);
|
||||||
}
|
}
|
||||||
|
|
||||||
|
|
||||||
|
// If there are available coupons and they are enough for the operation
|
||||||
|
if (couponCredits >= credits) {
|
||||||
|
return { success: true, message: "Sufficient credits available", remainingCredits: couponCredits };
|
||||||
|
}
|
||||||
|
|
||||||
|
|
||||||
// Free credits, no coupons
|
// Free credits, no coupons
|
||||||
if (!subscription || subscriptionError) {
|
if (!subscription || subscriptionError) {
|
||||||
|
|
||||||
// If there is no active subscription but there are available coupons
|
|
||||||
if (couponCredits >= credits) {
|
|
||||||
return { success: true, message: "Sufficient credits available", remainingCredits: couponCredits };
|
|
||||||
}
|
|
||||||
|
|
||||||
let creditUsages;
|
let creditUsages;
|
||||||
let creditUsageError;
|
let creditUsageError;
|
||||||
let retries = 0;
|
let totalCreditsUsed = 0;
|
||||||
const maxRetries = 3;
|
const cacheKeyCreditUsage = `credit_usage_${team_id}`;
|
||||||
const retryInterval = 2000; // 2 seconds
|
|
||||||
|
|
||||||
while (retries < maxRetries) {
|
// Try to get credit usage from cache
|
||||||
const result = await supabase_service
|
const cachedCreditUsage = await getValue(cacheKeyCreditUsage);
|
||||||
.from("credit_usage")
|
|
||||||
.select("credits_used")
|
|
||||||
.is("subscription_id", null)
|
|
||||||
.eq("team_id", team_id);
|
|
||||||
|
|
||||||
creditUsages = result.data;
|
if (cachedCreditUsage) {
|
||||||
creditUsageError = result.error;
|
totalCreditsUsed = parseInt(cachedCreditUsage);
|
||||||
|
} else {
|
||||||
|
let retries = 0;
|
||||||
|
const maxRetries = 3;
|
||||||
|
const retryInterval = 2000; // 2 seconds
|
||||||
|
|
||||||
if (!creditUsageError) {
|
while (retries < maxRetries) {
|
||||||
break;
|
// Reminder, this has an 1000 limit.
|
||||||
|
const result = await supabase_service
|
||||||
|
.from("credit_usage")
|
||||||
|
.select("credits_used")
|
||||||
|
.is("subscription_id", null)
|
||||||
|
.eq("team_id", team_id);
|
||||||
|
|
||||||
|
creditUsages = result.data;
|
||||||
|
creditUsageError = result.error;
|
||||||
|
|
||||||
|
if (!creditUsageError) {
|
||||||
|
break;
|
||||||
|
}
|
||||||
|
|
||||||
|
retries++;
|
||||||
|
if (retries < maxRetries) {
|
||||||
|
await new Promise(resolve => setTimeout(resolve, retryInterval));
|
||||||
|
}
|
||||||
}
|
}
|
||||||
|
|
||||||
retries++;
|
if (creditUsageError) {
|
||||||
if (retries < maxRetries) {
|
Logger.error(`Credit usage error after ${maxRetries} attempts: ${creditUsageError}`);
|
||||||
await new Promise(resolve => setTimeout(resolve, retryInterval));
|
throw new Error(
|
||||||
|
`Failed to retrieve credit usage for team_id: ${team_id}`
|
||||||
|
);
|
||||||
}
|
}
|
||||||
}
|
|
||||||
|
|
||||||
if (creditUsageError) {
|
totalCreditsUsed = creditUsages.reduce(
|
||||||
Logger.error(`Credit usage error after ${maxRetries} attempts: ${creditUsageError}`);
|
(acc, usage) => acc + usage.credits_used,
|
||||||
throw new Error(
|
0
|
||||||
`Failed to retrieve credit usage for team_id: ${team_id}`
|
|
||||||
);
|
);
|
||||||
}
|
|
||||||
|
|
||||||
const totalCreditsUsed = creditUsages.reduce(
|
// Cache the result for 30 seconds
|
||||||
(acc, usage) => acc + usage.credits_used,
|
await setValue(cacheKeyCreditUsage, totalCreditsUsed.toString(), 30);
|
||||||
0
|
}
|
||||||
);
|
|
||||||
|
|
||||||
Logger.info(`totalCreditsUsed: ${totalCreditsUsed}`);
|
Logger.info(`totalCreditsUsed: ${totalCreditsUsed}`);
|
||||||
|
|
||||||
|
|
@ -254,7 +294,7 @@ export async function supaCheckTeamCredits(team_id: string, credits: number) {
|
||||||
end.setDate(end.getDate() + 30);
|
end.setDate(end.getDate() + 30);
|
||||||
// check if usage is within 80% of the limit
|
// check if usage is within 80% of the limit
|
||||||
const creditLimit = FREE_CREDITS;
|
const creditLimit = FREE_CREDITS;
|
||||||
const creditUsagePercentage = (totalCreditsUsed + credits) / creditLimit;
|
const creditUsagePercentage = totalCreditsUsed / creditLimit;
|
||||||
|
|
||||||
// Add a check to ensure totalCreditsUsed is greater than 0
|
// Add a check to ensure totalCreditsUsed is greater than 0
|
||||||
if (totalCreditsUsed > 0 && creditUsagePercentage >= 0.8 && creditUsagePercentage < 1) {
|
if (totalCreditsUsed > 0 && creditUsagePercentage >= 0.8 && creditUsagePercentage < 1) {
|
||||||
|
|
@ -268,7 +308,7 @@ export async function supaCheckTeamCredits(team_id: string, credits: number) {
|
||||||
}
|
}
|
||||||
|
|
||||||
// 5. Compare the total credits used with the credits allowed by the plan.
|
// 5. Compare the total credits used with the credits allowed by the plan.
|
||||||
if (totalCreditsUsed + credits > FREE_CREDITS) {
|
if (totalCreditsUsed >= FREE_CREDITS) {
|
||||||
// Send email notification for insufficient credits
|
// Send email notification for insufficient credits
|
||||||
await sendNotification(
|
await sendNotification(
|
||||||
team_id,
|
team_id,
|
||||||
|
|
@ -312,7 +352,7 @@ export async function supaCheckTeamCredits(team_id: string, credits: number) {
|
||||||
|
|
||||||
if (creditUsages && creditUsages.length > 0) {
|
if (creditUsages && creditUsages.length > 0) {
|
||||||
totalCreditsUsed = creditUsages[0].total_credits_used;
|
totalCreditsUsed = creditUsages[0].total_credits_used;
|
||||||
await setValue(cacheKey, totalCreditsUsed.toString(), 1800); // Cache for 30 minutes
|
await setValue(cacheKey, totalCreditsUsed.toString(), 500); // Cache for 8 minutes
|
||||||
// Logger.info(`Cache set for credit usage: ${totalCreditsUsed}`);
|
// Logger.info(`Cache set for credit usage: ${totalCreditsUsed}`);
|
||||||
}
|
}
|
||||||
}
|
}
|
||||||
|
|
@ -325,39 +365,62 @@ export async function supaCheckTeamCredits(team_id: string, credits: number) {
|
||||||
|
|
||||||
// Adjust total credits used by subtracting coupon value
|
// Adjust total credits used by subtracting coupon value
|
||||||
const adjustedCreditsUsed = Math.max(0, totalCreditsUsed - couponCredits);
|
const adjustedCreditsUsed = Math.max(0, totalCreditsUsed - couponCredits);
|
||||||
// Get the price details
|
|
||||||
const { data: price, error: priceError } = await supabase_service
|
|
||||||
.from("prices")
|
|
||||||
.select("credits")
|
|
||||||
.eq("id", subscription.price_id)
|
|
||||||
.single();
|
|
||||||
|
|
||||||
if (priceError) {
|
// Get the price details from cache or database
|
||||||
throw new Error(
|
const priceCacheKey = `price_${subscription.price_id}`;
|
||||||
`Failed to retrieve price for price_id: ${subscription.price_id}`
|
let price : {credits: number};
|
||||||
);
|
|
||||||
|
try {
|
||||||
|
const cachedPrice = await getValue(priceCacheKey);
|
||||||
|
if (cachedPrice) {
|
||||||
|
price = JSON.parse(cachedPrice);
|
||||||
|
} else {
|
||||||
|
const { data, error: priceError } = await supabase_service
|
||||||
|
.from("prices")
|
||||||
|
.select("credits")
|
||||||
|
.eq("id", subscription.price_id)
|
||||||
|
.single();
|
||||||
|
|
||||||
|
if (priceError) {
|
||||||
|
throw new Error(
|
||||||
|
`Failed to retrieve price for price_id: ${subscription.price_id}`
|
||||||
|
);
|
||||||
|
}
|
||||||
|
|
||||||
|
price = data;
|
||||||
|
// There are only 21 records, so this is super fine
|
||||||
|
// Cache the price for a long time (e.g., 1 day)
|
||||||
|
await setValue(priceCacheKey, JSON.stringify(price), 86400);
|
||||||
|
}
|
||||||
|
} catch (error) {
|
||||||
|
Logger.error(`Error retrieving or caching price: ${error}`);
|
||||||
|
Sentry.captureException(error);
|
||||||
|
// If errors, just assume it's a big number so user don't get an error
|
||||||
|
price = { credits: 10000000 };
|
||||||
}
|
}
|
||||||
|
|
||||||
const creditLimit = price.credits;
|
const creditLimit = price.credits;
|
||||||
const creditUsagePercentage = (adjustedCreditsUsed + credits) / creditLimit;
|
|
||||||
|
// Removal of + credits
|
||||||
|
const creditUsagePercentage = adjustedCreditsUsed / creditLimit;
|
||||||
|
|
||||||
// Compare the adjusted total credits used with the credits allowed by the plan
|
// Compare the adjusted total credits used with the credits allowed by the plan
|
||||||
if (adjustedCreditsUsed + credits > price.credits) {
|
if (adjustedCreditsUsed >= price.credits) {
|
||||||
// await sendNotification(
|
await sendNotification(
|
||||||
// team_id,
|
team_id,
|
||||||
// NotificationType.LIMIT_REACHED,
|
NotificationType.LIMIT_REACHED,
|
||||||
// subscription.current_period_start,
|
subscription.current_period_start,
|
||||||
// subscription.current_period_end
|
subscription.current_period_end
|
||||||
// );
|
);
|
||||||
return { success: false, message: "Insufficient credits, please upgrade!", remainingCredits: creditLimit - adjustedCreditsUsed };
|
return { success: false, message: "Insufficient credits, please upgrade!", remainingCredits: creditLimit - adjustedCreditsUsed };
|
||||||
} else if (creditUsagePercentage >= 0.8) {
|
} else if (creditUsagePercentage >= 0.8 && creditUsagePercentage < 1) {
|
||||||
// Send email notification for approaching credit limit
|
// Send email notification for approaching credit limit
|
||||||
// await sendNotification(
|
await sendNotification(
|
||||||
// team_id,
|
team_id,
|
||||||
// NotificationType.APPROACHING_LIMIT,
|
NotificationType.APPROACHING_LIMIT,
|
||||||
// subscription.current_period_start,
|
subscription.current_period_start,
|
||||||
// subscription.current_period_end
|
subscription.current_period_end
|
||||||
// );
|
);
|
||||||
}
|
}
|
||||||
|
|
||||||
return { success: true, message: "Sufficient credits available", remainingCredits: creditLimit - adjustedCreditsUsed };
|
return { success: true, message: "Sufficient credits available", remainingCredits: creditLimit - adjustedCreditsUsed };
|
||||||
|
|
|
||||||
|
|
@ -1,6 +1,7 @@
|
||||||
import { supabase_service } from "../supabase";
|
import { supabase_service } from "../supabase";
|
||||||
import { Logger } from "../../../src/lib/logger";
|
import { Logger } from "../../../src/lib/logger";
|
||||||
import "dotenv/config";
|
import { configDotenv } from "dotenv";
|
||||||
|
configDotenv();
|
||||||
|
|
||||||
export async function logCrawl(job_id: string, team_id: string) {
|
export async function logCrawl(job_id: string, team_id: string) {
|
||||||
const useDbAuthentication = process.env.USE_DB_AUTHENTICATION === 'true';
|
const useDbAuthentication = process.env.USE_DB_AUTHENTICATION === 'true';
|
||||||
|
|
|
||||||
|
|
@ -4,6 +4,8 @@ import { FirecrawlJob } from "../../types";
|
||||||
import { posthog } from "../posthog";
|
import { posthog } from "../posthog";
|
||||||
import "dotenv/config";
|
import "dotenv/config";
|
||||||
import { Logger } from "../../lib/logger";
|
import { Logger } from "../../lib/logger";
|
||||||
|
import { configDotenv } from "dotenv";
|
||||||
|
configDotenv();
|
||||||
|
|
||||||
export async function logJob(job: FirecrawlJob) {
|
export async function logJob(job: FirecrawlJob) {
|
||||||
try {
|
try {
|
||||||
|
|
|
||||||
|
|
@ -3,6 +3,8 @@ import { ScrapeLog } from "../../types";
|
||||||
import { supabase_service } from "../supabase";
|
import { supabase_service } from "../supabase";
|
||||||
import { PageOptions } from "../../lib/entities";
|
import { PageOptions } from "../../lib/entities";
|
||||||
import { Logger } from "../../lib/logger";
|
import { Logger } from "../../lib/logger";
|
||||||
|
import { configDotenv } from "dotenv";
|
||||||
|
configDotenv();
|
||||||
|
|
||||||
export async function logScrape(
|
export async function logScrape(
|
||||||
scrapeLog: ScrapeLog,
|
scrapeLog: ScrapeLog,
|
||||||
|
|
|
||||||
|
|
@ -67,6 +67,6 @@ export function waitForJob(jobId: string, timeout: number) {
|
||||||
reject((await getScrapeQueue().getJob(jobId)).failedReason);
|
reject((await getScrapeQueue().getJob(jobId)).failedReason);
|
||||||
}
|
}
|
||||||
}
|
}
|
||||||
}, 1000);
|
}, 500);
|
||||||
})
|
})
|
||||||
}
|
}
|
||||||
|
|
|
||||||
|
|
@ -16,6 +16,14 @@ export function getScrapeQueue() {
|
||||||
scrapeQueueName,
|
scrapeQueueName,
|
||||||
{
|
{
|
||||||
connection: redisConnection,
|
connection: redisConnection,
|
||||||
|
defaultJobOptions: {
|
||||||
|
removeOnComplete: {
|
||||||
|
age: 90000, // 25 hours
|
||||||
|
},
|
||||||
|
removeOnFail: {
|
||||||
|
age: 90000, // 25 hours
|
||||||
|
},
|
||||||
|
},
|
||||||
}
|
}
|
||||||
// {
|
// {
|
||||||
// settings: {
|
// settings: {
|
||||||
|
|
|
||||||
|
|
@ -36,6 +36,8 @@ import {
|
||||||
} from "../../src/lib/job-priority";
|
} from "../../src/lib/job-priority";
|
||||||
import { PlanType } from "../types";
|
import { PlanType } from "../types";
|
||||||
import { getJobs } from "../../src/controllers/v1/crawl-status";
|
import { getJobs } from "../../src/controllers/v1/crawl-status";
|
||||||
|
import { configDotenv } from "dotenv";
|
||||||
|
configDotenv();
|
||||||
|
|
||||||
if (process.env.ENV === "production") {
|
if (process.env.ENV === "production") {
|
||||||
initSDK({
|
initSDK({
|
||||||
|
|
@ -446,11 +448,13 @@ async function processJob(job: Job, token: string) {
|
||||||
} catch (error) {
|
} catch (error) {
|
||||||
Logger.error(`🐂 Job errored ${job.id} - ${error}`);
|
Logger.error(`🐂 Job errored ${job.id} - ${error}`);
|
||||||
|
|
||||||
Sentry.captureException(error, {
|
if (!(error instanceof Error && error.message.includes("JSON parsing error(s): "))) {
|
||||||
data: {
|
Sentry.captureException(error, {
|
||||||
job: job.id,
|
data: {
|
||||||
},
|
job: job.id,
|
||||||
});
|
},
|
||||||
|
});
|
||||||
|
}
|
||||||
|
|
||||||
if (error instanceof CustomError) {
|
if (error instanceof CustomError) {
|
||||||
// Here we handle the error, then save the failed job
|
// Here we handle the error, then save the failed job
|
||||||
|
|
|
||||||
|
|
@ -6,7 +6,7 @@ const RATE_LIMITS = {
|
||||||
crawl: {
|
crawl: {
|
||||||
default: 3,
|
default: 3,
|
||||||
free: 2,
|
free: 2,
|
||||||
starter: 3,
|
starter: 10,
|
||||||
standard: 5,
|
standard: 5,
|
||||||
standardOld: 40,
|
standardOld: 40,
|
||||||
scale: 50,
|
scale: 50,
|
||||||
|
|
@ -19,9 +19,9 @@ const RATE_LIMITS = {
|
||||||
scrape: {
|
scrape: {
|
||||||
default: 20,
|
default: 20,
|
||||||
free: 10,
|
free: 10,
|
||||||
starter: 20,
|
starter: 100,
|
||||||
standard: 100,
|
standard: 100,
|
||||||
standardOld: 40,
|
standardOld: 100,
|
||||||
scale: 500,
|
scale: 500,
|
||||||
hobby: 20,
|
hobby: 20,
|
||||||
standardNew: 100,
|
standardNew: 100,
|
||||||
|
|
@ -32,8 +32,8 @@ const RATE_LIMITS = {
|
||||||
search: {
|
search: {
|
||||||
default: 20,
|
default: 20,
|
||||||
free: 5,
|
free: 5,
|
||||||
starter: 20,
|
starter: 50,
|
||||||
standard: 40,
|
standard: 50,
|
||||||
standardOld: 40,
|
standardOld: 40,
|
||||||
scale: 500,
|
scale: 500,
|
||||||
hobby: 10,
|
hobby: 10,
|
||||||
|
|
@ -45,9 +45,9 @@ const RATE_LIMITS = {
|
||||||
map:{
|
map:{
|
||||||
default: 20,
|
default: 20,
|
||||||
free: 5,
|
free: 5,
|
||||||
starter: 20,
|
starter: 50,
|
||||||
standard: 40,
|
standard: 50,
|
||||||
standardOld: 40,
|
standardOld: 50,
|
||||||
scale: 500,
|
scale: 500,
|
||||||
hobby: 10,
|
hobby: 10,
|
||||||
standardNew: 50,
|
standardNew: 50,
|
||||||
|
|
@ -104,6 +104,13 @@ export const devBRateLimiter = new RateLimiterRedis({
|
||||||
duration: 60, // Duration in seconds
|
duration: 60, // Duration in seconds
|
||||||
});
|
});
|
||||||
|
|
||||||
|
export const manualRateLimiter = new RateLimiterRedis({
|
||||||
|
storeClient: redisRateLimitClient,
|
||||||
|
keyPrefix: "manual",
|
||||||
|
points: 2000,
|
||||||
|
duration: 60, // Duration in seconds
|
||||||
|
});
|
||||||
|
|
||||||
|
|
||||||
export const scrapeStatusRateLimiter = new RateLimiterRedis({
|
export const scrapeStatusRateLimiter = new RateLimiterRedis({
|
||||||
storeClient: redisRateLimitClient,
|
storeClient: redisRateLimitClient,
|
||||||
|
|
@ -112,14 +119,18 @@ export const scrapeStatusRateLimiter = new RateLimiterRedis({
|
||||||
duration: 60, // Duration in seconds
|
duration: 60, // Duration in seconds
|
||||||
});
|
});
|
||||||
|
|
||||||
|
const testSuiteTokens = ["a01ccae", "6254cf9", "0f96e673", "23befa1b", "69141c4"];
|
||||||
|
|
||||||
|
const manual = ["69be9e74-7624-4990-b20d-08e0acc70cf6"];
|
||||||
|
|
||||||
export function getRateLimiter(
|
export function getRateLimiter(
|
||||||
mode: RateLimiterMode,
|
mode: RateLimiterMode,
|
||||||
token: string,
|
token: string,
|
||||||
plan?: string,
|
plan?: string,
|
||||||
teamId?: string
|
teamId?: string
|
||||||
) {
|
) {
|
||||||
|
|
||||||
if (token.includes("a01ccae") || token.includes("6254cf9") || token.includes("0f96e673") || token.includes("23befa1b")) {
|
if (testSuiteTokens.some(testToken => token.includes(testToken))) {
|
||||||
return testSuiteRateLimiter;
|
return testSuiteRateLimiter;
|
||||||
}
|
}
|
||||||
|
|
||||||
|
|
@ -127,6 +138,10 @@ export function getRateLimiter(
|
||||||
return devBRateLimiter;
|
return devBRateLimiter;
|
||||||
}
|
}
|
||||||
|
|
||||||
|
if(teamId && manual.includes(teamId)) {
|
||||||
|
return manualRateLimiter;
|
||||||
|
}
|
||||||
|
|
||||||
const rateLimitConfig = RATE_LIMITS[mode]; // {default : 5}
|
const rateLimitConfig = RATE_LIMITS[mode]; // {default : 5}
|
||||||
|
|
||||||
if (!rateLimitConfig) return serverRateLimiter;
|
if (!rateLimitConfig) return serverRateLimiter;
|
||||||
|
|
|
||||||
|
|
@ -1,5 +1,7 @@
|
||||||
import { createClient, SupabaseClient } from "@supabase/supabase-js";
|
import { createClient, SupabaseClient } from "@supabase/supabase-js";
|
||||||
import { Logger } from "../lib/logger";
|
import { Logger } from "../lib/logger";
|
||||||
|
import { configDotenv } from "dotenv";
|
||||||
|
configDotenv();
|
||||||
|
|
||||||
// SupabaseService class initializes the Supabase client conditionally based on environment variables.
|
// SupabaseService class initializes the Supabase client conditionally based on environment variables.
|
||||||
class SupabaseService {
|
class SupabaseService {
|
||||||
|
|
|
||||||
|
|
@ -3,6 +3,8 @@ import { legacyDocumentConverter } from "../../src/controllers/v1/types";
|
||||||
import { Logger } from "../../src/lib/logger";
|
import { Logger } from "../../src/lib/logger";
|
||||||
import { supabase_service } from "./supabase";
|
import { supabase_service } from "./supabase";
|
||||||
import { WebhookEventType } from "../types";
|
import { WebhookEventType } from "../types";
|
||||||
|
import { configDotenv } from "dotenv";
|
||||||
|
configDotenv();
|
||||||
|
|
||||||
export const callWebhook = async (
|
export const callWebhook = async (
|
||||||
teamId: string,
|
teamId: string,
|
||||||
|
|
|
||||||
823
apps/api/v1-openapi.json
Normal file
823
apps/api/v1-openapi.json
Normal file
|
|
@ -0,0 +1,823 @@
|
||||||
|
{
|
||||||
|
"openapi": "3.0.0",
|
||||||
|
"info": {
|
||||||
|
"title": "Firecrawl API",
|
||||||
|
"version": "v1",
|
||||||
|
"description": "API for interacting with Firecrawl services to perform web scraping and crawling tasks.",
|
||||||
|
"contact": {
|
||||||
|
"name": "Firecrawl Support",
|
||||||
|
"url": "https://firecrawl.dev",
|
||||||
|
"email": "support@firecrawl.dev"
|
||||||
|
}
|
||||||
|
},
|
||||||
|
"servers": [
|
||||||
|
{
|
||||||
|
"url": "https://api.firecrawl.dev/v1"
|
||||||
|
}
|
||||||
|
],
|
||||||
|
"paths": {
|
||||||
|
"/scrape": {
|
||||||
|
"post": {
|
||||||
|
"summary": "Scrape a single URL and optionally extract information using an LLM",
|
||||||
|
"operationId": "scrapeAndExtractFromUrl",
|
||||||
|
"tags": ["Scraping"],
|
||||||
|
"security": [
|
||||||
|
{
|
||||||
|
"bearerAuth": []
|
||||||
|
}
|
||||||
|
],
|
||||||
|
"requestBody": {
|
||||||
|
"required": true,
|
||||||
|
"content": {
|
||||||
|
"application/json": {
|
||||||
|
"schema": {
|
||||||
|
"type": "object",
|
||||||
|
"properties": {
|
||||||
|
"url": {
|
||||||
|
"type": "string",
|
||||||
|
"format": "uri",
|
||||||
|
"description": "The URL to scrape"
|
||||||
|
},
|
||||||
|
"formats": {
|
||||||
|
"type": "array",
|
||||||
|
"items": {
|
||||||
|
"type": "string",
|
||||||
|
"enum": ["markdown", "html", "rawHtml", "links", "screenshot", "extract", "screenshot@fullPage"]
|
||||||
|
},
|
||||||
|
"description": "Formats to include in the output.",
|
||||||
|
"default": ["markdown"]
|
||||||
|
},
|
||||||
|
"onlyMainContent": {
|
||||||
|
"type": "boolean",
|
||||||
|
"description": "Only return the main content of the page excluding headers, navs, footers, etc.",
|
||||||
|
"default": true
|
||||||
|
},
|
||||||
|
"includeTags": {
|
||||||
|
"type": "array",
|
||||||
|
"items": {
|
||||||
|
"type": "string"
|
||||||
|
},
|
||||||
|
"description": "Tags to include in the output."
|
||||||
|
},
|
||||||
|
"excludeTags": {
|
||||||
|
"type": "array",
|
||||||
|
"items": {
|
||||||
|
"type": "string"
|
||||||
|
},
|
||||||
|
"description": "Tags to exclude from the output."
|
||||||
|
},
|
||||||
|
"headers": {
|
||||||
|
"type": "object",
|
||||||
|
"description": "Headers to send with the request. Can be used to send cookies, user-agent, etc."
|
||||||
|
},
|
||||||
|
"waitFor": {
|
||||||
|
"type": "integer",
|
||||||
|
"description": "Specify a delay in milliseconds before fetching the content, allowing the page sufficient time to load.",
|
||||||
|
"default": 0
|
||||||
|
},
|
||||||
|
"timeout": {
|
||||||
|
"type": "integer",
|
||||||
|
"description": "Timeout in milliseconds for the request",
|
||||||
|
"default": 30000
|
||||||
|
},
|
||||||
|
"extract": {
|
||||||
|
"type": "object",
|
||||||
|
"description": "Extract object",
|
||||||
|
"properties": {
|
||||||
|
"schema": {
|
||||||
|
"type": "object",
|
||||||
|
"description": "The schema to use for the extraction (Optional)"
|
||||||
|
},
|
||||||
|
"systemPrompt": {
|
||||||
|
"type": "string",
|
||||||
|
"description": "The system prompt to use for the extraction (Optional)"
|
||||||
|
},
|
||||||
|
"prompt": {
|
||||||
|
"type": "string",
|
||||||
|
"description": "The prompt to use for the extraction without a schema (Optional)"
|
||||||
|
}
|
||||||
|
}
|
||||||
|
}
|
||||||
|
},
|
||||||
|
"required": ["url"]
|
||||||
|
}
|
||||||
|
}
|
||||||
|
}
|
||||||
|
},
|
||||||
|
"responses": {
|
||||||
|
"200": {
|
||||||
|
"description": "Successful response",
|
||||||
|
"content": {
|
||||||
|
"application/json": {
|
||||||
|
"schema": {
|
||||||
|
"$ref": "#/components/schemas/ScrapeResponse"
|
||||||
|
}
|
||||||
|
}
|
||||||
|
}
|
||||||
|
},
|
||||||
|
"402": {
|
||||||
|
"description": "Payment required",
|
||||||
|
"content": {
|
||||||
|
"application/json": {
|
||||||
|
"schema": {
|
||||||
|
"type": "object",
|
||||||
|
"properties": {
|
||||||
|
"error": {
|
||||||
|
"type": "string",
|
||||||
|
"example": "Payment required to access this resource."
|
||||||
|
}
|
||||||
|
}
|
||||||
|
}
|
||||||
|
}
|
||||||
|
}
|
||||||
|
},
|
||||||
|
"429": {
|
||||||
|
"description": "Too many requests",
|
||||||
|
"content": {
|
||||||
|
"application/json": {
|
||||||
|
"schema": {
|
||||||
|
"type": "object",
|
||||||
|
"properties": {
|
||||||
|
"error": {
|
||||||
|
"type": "string",
|
||||||
|
"example": "Request rate limit exceeded. Please wait and try again later."
|
||||||
|
}
|
||||||
|
}
|
||||||
|
}
|
||||||
|
}
|
||||||
|
}
|
||||||
|
},
|
||||||
|
"500": {
|
||||||
|
"description": "Server error",
|
||||||
|
"content": {
|
||||||
|
"application/json": {
|
||||||
|
"schema": {
|
||||||
|
"type": "object",
|
||||||
|
"properties": {
|
||||||
|
"error": {
|
||||||
|
"type": "string",
|
||||||
|
"example": "An unexpected error occurred on the server."
|
||||||
|
}
|
||||||
|
}
|
||||||
|
}
|
||||||
|
}
|
||||||
|
}
|
||||||
|
}
|
||||||
|
}
|
||||||
|
}
|
||||||
|
},
|
||||||
|
"/crawl/{id}": {
|
||||||
|
"parameters": [
|
||||||
|
{
|
||||||
|
"name": "id",
|
||||||
|
"in": "path",
|
||||||
|
"description": "The ID of the crawl job",
|
||||||
|
"required": true,
|
||||||
|
"schema": {
|
||||||
|
"type": "string",
|
||||||
|
"format": "uuid"
|
||||||
|
}
|
||||||
|
}
|
||||||
|
],
|
||||||
|
"get": {
|
||||||
|
"summary": "Get the status of a crawl job",
|
||||||
|
"operationId": "getCrawlStatus",
|
||||||
|
"tags": ["Crawling"],
|
||||||
|
"security": [
|
||||||
|
{
|
||||||
|
"bearerAuth": []
|
||||||
|
}
|
||||||
|
],
|
||||||
|
"responses": {
|
||||||
|
"200": {
|
||||||
|
"description": "Successful response",
|
||||||
|
"content": {
|
||||||
|
"application/json": {
|
||||||
|
"schema": {
|
||||||
|
"$ref": "#/components/schemas/CrawlStatusResponseObj"
|
||||||
|
}
|
||||||
|
}
|
||||||
|
}
|
||||||
|
},
|
||||||
|
"402": {
|
||||||
|
"description": "Payment required",
|
||||||
|
"content": {
|
||||||
|
"application/json": {
|
||||||
|
"schema": {
|
||||||
|
"type": "object",
|
||||||
|
"properties": {
|
||||||
|
"error": {
|
||||||
|
"type": "string",
|
||||||
|
"example": "Payment required to access this resource."
|
||||||
|
}
|
||||||
|
}
|
||||||
|
}
|
||||||
|
}
|
||||||
|
}
|
||||||
|
},
|
||||||
|
"429": {
|
||||||
|
"description": "Too many requests",
|
||||||
|
"content": {
|
||||||
|
"application/json": {
|
||||||
|
"schema": {
|
||||||
|
"type": "object",
|
||||||
|
"properties": {
|
||||||
|
"error": {
|
||||||
|
"type": "string",
|
||||||
|
"example": "Request rate limit exceeded. Please wait and try again later."
|
||||||
|
}
|
||||||
|
}
|
||||||
|
}
|
||||||
|
}
|
||||||
|
}
|
||||||
|
},
|
||||||
|
"500": {
|
||||||
|
"description": "Server error",
|
||||||
|
"content": {
|
||||||
|
"application/json": {
|
||||||
|
"schema": {
|
||||||
|
"type": "object",
|
||||||
|
"properties": {
|
||||||
|
"error": {
|
||||||
|
"type": "string",
|
||||||
|
"example": "An unexpected error occurred on the server."
|
||||||
|
}
|
||||||
|
}
|
||||||
|
}
|
||||||
|
}
|
||||||
|
}
|
||||||
|
}
|
||||||
|
}
|
||||||
|
},
|
||||||
|
"delete": {
|
||||||
|
"summary": "Cancel a crawl job",
|
||||||
|
"operationId": "cancelCrawl",
|
||||||
|
"tags": ["Crawling"],
|
||||||
|
"security": [
|
||||||
|
{
|
||||||
|
"bearerAuth": []
|
||||||
|
}
|
||||||
|
],
|
||||||
|
"responses": {
|
||||||
|
"200": {
|
||||||
|
"description": "Successful cancellation",
|
||||||
|
"content": {
|
||||||
|
"application/json": {
|
||||||
|
"schema": {
|
||||||
|
"type": "object",
|
||||||
|
"properties": {
|
||||||
|
"success": {
|
||||||
|
"type": "boolean",
|
||||||
|
"example": true
|
||||||
|
},
|
||||||
|
"message": {
|
||||||
|
"type": "string",
|
||||||
|
"example": "Crawl job successfully cancelled."
|
||||||
|
}
|
||||||
|
}
|
||||||
|
}
|
||||||
|
}
|
||||||
|
}
|
||||||
|
},
|
||||||
|
"404": {
|
||||||
|
"description": "Crawl job not found",
|
||||||
|
"content": {
|
||||||
|
"application/json": {
|
||||||
|
"schema": {
|
||||||
|
"type": "object",
|
||||||
|
"properties": {
|
||||||
|
"error": {
|
||||||
|
"type": "string",
|
||||||
|
"example": "Crawl job not found."
|
||||||
|
}
|
||||||
|
}
|
||||||
|
}
|
||||||
|
}
|
||||||
|
}
|
||||||
|
},
|
||||||
|
"500": {
|
||||||
|
"description": "Server error",
|
||||||
|
"content": {
|
||||||
|
"application/json": {
|
||||||
|
"schema": {
|
||||||
|
"type": "object",
|
||||||
|
"properties": {
|
||||||
|
"error": {
|
||||||
|
"type": "string",
|
||||||
|
"example": "An unexpected error occurred on the server."
|
||||||
|
}
|
||||||
|
}
|
||||||
|
}
|
||||||
|
}
|
||||||
|
}
|
||||||
|
}
|
||||||
|
}
|
||||||
|
}
|
||||||
|
},
|
||||||
|
"/crawl": {
|
||||||
|
"post": {
|
||||||
|
"summary": "Crawl multiple URLs based on options",
|
||||||
|
"operationId": "crawlUrls",
|
||||||
|
"tags": ["Crawling"],
|
||||||
|
"security": [
|
||||||
|
{
|
||||||
|
"bearerAuth": []
|
||||||
|
}
|
||||||
|
],
|
||||||
|
"requestBody": {
|
||||||
|
"required": true,
|
||||||
|
"content": {
|
||||||
|
"application/json": {
|
||||||
|
"schema": {
|
||||||
|
"type": "object",
|
||||||
|
"properties": {
|
||||||
|
"url": {
|
||||||
|
"type": "string",
|
||||||
|
"format": "uri",
|
||||||
|
"description": "The base URL to start crawling from"
|
||||||
|
},
|
||||||
|
"excludePaths": {
|
||||||
|
"type": "array",
|
||||||
|
"items": {
|
||||||
|
"type": "string"
|
||||||
|
},
|
||||||
|
"description": "URL patterns to exclude"
|
||||||
|
},
|
||||||
|
"includePaths": {
|
||||||
|
"type": "array",
|
||||||
|
"items": {
|
||||||
|
"type": "string"
|
||||||
|
},
|
||||||
|
"description": "URL patterns to include"
|
||||||
|
},
|
||||||
|
"maxDepth": {
|
||||||
|
"type": "integer",
|
||||||
|
"description": "Maximum depth to crawl relative to the entered URL.",
|
||||||
|
"default": 2
|
||||||
|
},
|
||||||
|
"ignoreSitemap": {
|
||||||
|
"type": "boolean",
|
||||||
|
"description": "Ignore the website sitemap when crawling",
|
||||||
|
"default": true
|
||||||
|
},
|
||||||
|
"limit": {
|
||||||
|
"type": "integer",
|
||||||
|
"description": "Maximum number of pages to crawl",
|
||||||
|
"default": 10
|
||||||
|
},
|
||||||
|
"allowBackwardLinks": {
|
||||||
|
"type": "boolean",
|
||||||
|
"description": "Enables the crawler to navigate from a specific URL to previously linked pages.",
|
||||||
|
"default": false
|
||||||
|
},
|
||||||
|
"allowExternalLinks": {
|
||||||
|
"type": "boolean",
|
||||||
|
"description": "Allows the crawler to follow links to external websites.",
|
||||||
|
"default": false
|
||||||
|
},
|
||||||
|
"webhook": {
|
||||||
|
"type": "string",
|
||||||
|
"description": "The URL to send the webhook to. This will trigger for crawl started (crawl.started) ,every page crawled (crawl.page) and when the crawl is completed (crawl.completed or crawl.failed). The response will be the same as the `/scrape` endpoint."
|
||||||
|
},
|
||||||
|
"scrapeOptions": {
|
||||||
|
"type": "object",
|
||||||
|
"properties": {
|
||||||
|
"formats": {
|
||||||
|
"type": "array",
|
||||||
|
"items": {
|
||||||
|
"type": "string",
|
||||||
|
"enum": ["markdown", "html", "rawHtml", "links", "screenshot"]
|
||||||
|
},
|
||||||
|
"description": "Formats to include in the output.",
|
||||||
|
"default": ["markdown"]
|
||||||
|
},
|
||||||
|
"headers": {
|
||||||
|
"type": "object",
|
||||||
|
"description": "Headers to send with the request. Can be used to send cookies, user-agent, etc."
|
||||||
|
},
|
||||||
|
"includeTags": {
|
||||||
|
"type": "array",
|
||||||
|
"items": {
|
||||||
|
"type": "string"
|
||||||
|
},
|
||||||
|
"description": "Tags to include in the output."
|
||||||
|
},
|
||||||
|
"excludeTags": {
|
||||||
|
"type": "array",
|
||||||
|
"items": {
|
||||||
|
"type": "string"
|
||||||
|
},
|
||||||
|
"description": "Tags to exclude from the output."
|
||||||
|
},
|
||||||
|
"onlyMainContent": {
|
||||||
|
"type": "boolean",
|
||||||
|
"description": "Only return the main content of the page excluding headers, navs, footers, etc.",
|
||||||
|
"default": true
|
||||||
|
},
|
||||||
|
"waitFor": {
|
||||||
|
"type": "integer",
|
||||||
|
"description": "Wait x amount of milliseconds for the page to load to fetch content",
|
||||||
|
"default": 123
|
||||||
|
}
|
||||||
|
}
|
||||||
|
}
|
||||||
|
},
|
||||||
|
"required": ["url"]
|
||||||
|
}
|
||||||
|
}
|
||||||
|
}
|
||||||
|
},
|
||||||
|
"responses": {
|
||||||
|
"200": {
|
||||||
|
"description": "Successful response",
|
||||||
|
"content": {
|
||||||
|
"application/json": {
|
||||||
|
"schema": {
|
||||||
|
"$ref": "#/components/schemas/CrawlResponse"
|
||||||
|
}
|
||||||
|
}
|
||||||
|
}
|
||||||
|
},
|
||||||
|
"402": {
|
||||||
|
"description": "Payment required",
|
||||||
|
"content": {
|
||||||
|
"application/json": {
|
||||||
|
"schema": {
|
||||||
|
"type": "object",
|
||||||
|
"properties": {
|
||||||
|
"error": {
|
||||||
|
"type": "string",
|
||||||
|
"example": "Payment required to access this resource."
|
||||||
|
}
|
||||||
|
}
|
||||||
|
}
|
||||||
|
}
|
||||||
|
}
|
||||||
|
},
|
||||||
|
"429": {
|
||||||
|
"description": "Too many requests",
|
||||||
|
"content": {
|
||||||
|
"application/json": {
|
||||||
|
"schema": {
|
||||||
|
"type": "object",
|
||||||
|
"properties": {
|
||||||
|
"error": {
|
||||||
|
"type": "string",
|
||||||
|
"example": "Request rate limit exceeded. Please wait and try again later."
|
||||||
|
}
|
||||||
|
}
|
||||||
|
}
|
||||||
|
}
|
||||||
|
}
|
||||||
|
},
|
||||||
|
"500": {
|
||||||
|
"description": "Server error",
|
||||||
|
"content": {
|
||||||
|
"application/json": {
|
||||||
|
"schema": {
|
||||||
|
"type": "object",
|
||||||
|
"properties": {
|
||||||
|
"error": {
|
||||||
|
"type": "string",
|
||||||
|
"example": "An unexpected error occurred on the server."
|
||||||
|
}
|
||||||
|
}
|
||||||
|
}
|
||||||
|
}
|
||||||
|
}
|
||||||
|
}
|
||||||
|
}
|
||||||
|
}
|
||||||
|
},
|
||||||
|
"/map": {
|
||||||
|
"post": {
|
||||||
|
"summary": "Map multiple URLs based on options",
|
||||||
|
"operationId": "mapUrls",
|
||||||
|
"tags": ["Mapping"],
|
||||||
|
"security": [
|
||||||
|
{
|
||||||
|
"bearerAuth": []
|
||||||
|
}
|
||||||
|
],
|
||||||
|
"requestBody": {
|
||||||
|
"required": true,
|
||||||
|
"content": {
|
||||||
|
"application/json": {
|
||||||
|
"schema": {
|
||||||
|
"type": "object",
|
||||||
|
"properties": {
|
||||||
|
"url": {
|
||||||
|
"type": "string",
|
||||||
|
"format": "uri",
|
||||||
|
"description": "The base URL to start crawling from"
|
||||||
|
},
|
||||||
|
"search": {
|
||||||
|
"type": "string",
|
||||||
|
"description": "Search query to use for mapping. During the Alpha phase, the 'smart' part of the search functionality is limited to 100 search results. However, if map finds more results, there is no limit applied."
|
||||||
|
},
|
||||||
|
"ignoreSitemap": {
|
||||||
|
"type": "boolean",
|
||||||
|
"description": "Ignore the website sitemap when crawling",
|
||||||
|
"default": true
|
||||||
|
},
|
||||||
|
"includeSubdomains": {
|
||||||
|
"type": "boolean",
|
||||||
|
"description": "Include subdomains of the website",
|
||||||
|
"default": false
|
||||||
|
},
|
||||||
|
"limit": {
|
||||||
|
"type": "integer",
|
||||||
|
"description": "Maximum number of links to return",
|
||||||
|
"default": 5000,
|
||||||
|
"maximum": 5000
|
||||||
|
}
|
||||||
|
},
|
||||||
|
"required": ["url"]
|
||||||
|
}
|
||||||
|
}
|
||||||
|
}
|
||||||
|
},
|
||||||
|
"responses": {
|
||||||
|
"200": {
|
||||||
|
"description": "Successful response",
|
||||||
|
"content": {
|
||||||
|
"application/json": {
|
||||||
|
"schema": {
|
||||||
|
"$ref": "#/components/schemas/MapResponse"
|
||||||
|
}
|
||||||
|
}
|
||||||
|
}
|
||||||
|
},
|
||||||
|
"402": {
|
||||||
|
"description": "Payment required",
|
||||||
|
"content": {
|
||||||
|
"application/json": {
|
||||||
|
"schema": {
|
||||||
|
"type": "object",
|
||||||
|
"properties": {
|
||||||
|
"error": {
|
||||||
|
"type": "string",
|
||||||
|
"example": "Payment required to access this resource."
|
||||||
|
}
|
||||||
|
}
|
||||||
|
}
|
||||||
|
}
|
||||||
|
}
|
||||||
|
},
|
||||||
|
"429": {
|
||||||
|
"description": "Too many requests",
|
||||||
|
"content": {
|
||||||
|
"application/json": {
|
||||||
|
"schema": {
|
||||||
|
"type": "object",
|
||||||
|
"properties": {
|
||||||
|
"error": {
|
||||||
|
"type": "string",
|
||||||
|
"example": "Request rate limit exceeded. Please wait and try again later."
|
||||||
|
}
|
||||||
|
}
|
||||||
|
}
|
||||||
|
}
|
||||||
|
}
|
||||||
|
},
|
||||||
|
"500": {
|
||||||
|
"description": "Server error",
|
||||||
|
"content": {
|
||||||
|
"application/json": {
|
||||||
|
"schema": {
|
||||||
|
"type": "object",
|
||||||
|
"properties": {
|
||||||
|
"error": {
|
||||||
|
"type": "string",
|
||||||
|
"example": "An unexpected error occurred on the server."
|
||||||
|
}
|
||||||
|
}
|
||||||
|
}
|
||||||
|
}
|
||||||
|
}
|
||||||
|
}
|
||||||
|
}
|
||||||
|
}
|
||||||
|
}
|
||||||
|
},
|
||||||
|
"components": {
|
||||||
|
"securitySchemes": {
|
||||||
|
"bearerAuth": {
|
||||||
|
"type": "http",
|
||||||
|
"scheme": "bearer"
|
||||||
|
}
|
||||||
|
},
|
||||||
|
"schemas": {
|
||||||
|
"ScrapeResponse": {
|
||||||
|
"type": "object",
|
||||||
|
"properties": {
|
||||||
|
"success": {
|
||||||
|
"type": "boolean"
|
||||||
|
},
|
||||||
|
"data": {
|
||||||
|
"type": "object",
|
||||||
|
"properties": {
|
||||||
|
"markdown": {
|
||||||
|
"type": "string"
|
||||||
|
},
|
||||||
|
"html": {
|
||||||
|
"type": "string",
|
||||||
|
"nullable": true,
|
||||||
|
"description": "HTML version of the content on page if `html` is in `formats`"
|
||||||
|
},
|
||||||
|
"rawHtml": {
|
||||||
|
"type": "string",
|
||||||
|
"nullable": true,
|
||||||
|
"description": "Raw HTML content of the page if `rawHtml` is in `formats`"
|
||||||
|
},
|
||||||
|
"screenshot": {
|
||||||
|
"type": "string",
|
||||||
|
"nullable": true,
|
||||||
|
"description": "Screenshot of the page if `screenshot` is in `formats`"
|
||||||
|
},
|
||||||
|
"links": {
|
||||||
|
"type": "array",
|
||||||
|
"items": {
|
||||||
|
"type": "string"
|
||||||
|
},
|
||||||
|
"description": "List of links on the page if `links` is in `formats`"
|
||||||
|
},
|
||||||
|
"metadata": {
|
||||||
|
"type": "object",
|
||||||
|
"properties": {
|
||||||
|
"title": {
|
||||||
|
"type": "string"
|
||||||
|
},
|
||||||
|
"description": {
|
||||||
|
"type": "string"
|
||||||
|
},
|
||||||
|
"language": {
|
||||||
|
"type": "string",
|
||||||
|
"nullable": true
|
||||||
|
},
|
||||||
|
"sourceURL": {
|
||||||
|
"type": "string",
|
||||||
|
"format": "uri"
|
||||||
|
},
|
||||||
|
"<any other metadata> ": {
|
||||||
|
"type": "string"
|
||||||
|
},
|
||||||
|
"statusCode": {
|
||||||
|
"type": "integer",
|
||||||
|
"description": "The status code of the page"
|
||||||
|
},
|
||||||
|
"error": {
|
||||||
|
"type": "string",
|
||||||
|
"nullable": true,
|
||||||
|
"description": "The error message of the page"
|
||||||
|
}
|
||||||
|
|
||||||
|
}
|
||||||
|
},
|
||||||
|
"llm_extraction": {
|
||||||
|
"type": "object",
|
||||||
|
"description": "Displayed when using LLM Extraction. Extracted data from the page following the schema defined.",
|
||||||
|
"nullable": true
|
||||||
|
},
|
||||||
|
"warning": {
|
||||||
|
"type": "string",
|
||||||
|
"nullable": true,
|
||||||
|
"description": "Can be displayed when using LLM Extraction. Warning message will let you know any issues with the extraction."
|
||||||
|
}
|
||||||
|
}
|
||||||
|
}
|
||||||
|
}
|
||||||
|
},
|
||||||
|
"CrawlStatusResponseObj": {
|
||||||
|
"type": "object",
|
||||||
|
"properties": {
|
||||||
|
"status": {
|
||||||
|
"type": "string",
|
||||||
|
"description": "The current status of the crawl. Can be `scraping`, `completed`, or `failed`."
|
||||||
|
},
|
||||||
|
"total": {
|
||||||
|
"type": "integer",
|
||||||
|
"description": "The total number of pages that were attempted to be crawled."
|
||||||
|
},
|
||||||
|
"completed": {
|
||||||
|
"type": "integer",
|
||||||
|
"description": "The number of pages that have been successfully crawled."
|
||||||
|
},
|
||||||
|
"creditsUsed": {
|
||||||
|
"type": "integer",
|
||||||
|
"description": "The number of credits used for the crawl."
|
||||||
|
},
|
||||||
|
"expiresAt": {
|
||||||
|
"type": "string",
|
||||||
|
"format": "date-time",
|
||||||
|
"description": "The date and time when the crawl will expire."
|
||||||
|
},
|
||||||
|
"next": {
|
||||||
|
"type": "string",
|
||||||
|
"nullable": true,
|
||||||
|
"description": "The URL to retrieve the next 10MB of data. Returned if the crawl is not completed or if the response is larger than 10MB."
|
||||||
|
},
|
||||||
|
"data": {
|
||||||
|
"type": "array",
|
||||||
|
"description": "The data of the crawl.",
|
||||||
|
"items": {
|
||||||
|
"type": "object",
|
||||||
|
"properties": {
|
||||||
|
"markdown": {
|
||||||
|
"type": "string"
|
||||||
|
},
|
||||||
|
"html": {
|
||||||
|
"type": "string",
|
||||||
|
"nullable": true,
|
||||||
|
"description": "HTML version of the content on page if `includeHtml` is true"
|
||||||
|
},
|
||||||
|
"rawHtml": {
|
||||||
|
"type": "string",
|
||||||
|
"nullable": true,
|
||||||
|
"description": "Raw HTML content of the page if `includeRawHtml` is true"
|
||||||
|
},
|
||||||
|
"links": {
|
||||||
|
"type": "array",
|
||||||
|
"items": {
|
||||||
|
"type": "string"
|
||||||
|
},
|
||||||
|
"description": "List of links on the page if `includeLinks` is true"
|
||||||
|
},
|
||||||
|
"screenshot": {
|
||||||
|
"type": "string",
|
||||||
|
"nullable": true,
|
||||||
|
"description": "Screenshot of the page if `includeScreenshot` is true"
|
||||||
|
},
|
||||||
|
"metadata": {
|
||||||
|
"type": "object",
|
||||||
|
"properties": {
|
||||||
|
"title": {
|
||||||
|
"type": "string"
|
||||||
|
},
|
||||||
|
"description": {
|
||||||
|
"type": "string"
|
||||||
|
},
|
||||||
|
"language": {
|
||||||
|
"type": "string",
|
||||||
|
"nullable": true
|
||||||
|
},
|
||||||
|
"sourceURL": {
|
||||||
|
"type": "string",
|
||||||
|
"format": "uri"
|
||||||
|
},
|
||||||
|
"<any other metadata> ": {
|
||||||
|
"type": "string"
|
||||||
|
},
|
||||||
|
"statusCode": {
|
||||||
|
"type": "integer",
|
||||||
|
"description": "The status code of the page"
|
||||||
|
},
|
||||||
|
"error": {
|
||||||
|
"type": "string",
|
||||||
|
"nullable": true,
|
||||||
|
"description": "The error message of the page"
|
||||||
|
}
|
||||||
|
}
|
||||||
|
}
|
||||||
|
}
|
||||||
|
}
|
||||||
|
}
|
||||||
|
}
|
||||||
|
},
|
||||||
|
"CrawlResponse": {
|
||||||
|
"type": "object",
|
||||||
|
"properties": {
|
||||||
|
"success": {
|
||||||
|
"type": "boolean"
|
||||||
|
},
|
||||||
|
"id": {
|
||||||
|
"type": "string"
|
||||||
|
},
|
||||||
|
"url": {
|
||||||
|
"type": "string",
|
||||||
|
"format": "uri"
|
||||||
|
}
|
||||||
|
}
|
||||||
|
},
|
||||||
|
"MapResponse": {
|
||||||
|
"type": "object",
|
||||||
|
"properties": {
|
||||||
|
"success": {
|
||||||
|
"type": "boolean"
|
||||||
|
},
|
||||||
|
"links": {
|
||||||
|
"type": "array",
|
||||||
|
"items": {
|
||||||
|
"type": "string"
|
||||||
|
}
|
||||||
|
}
|
||||||
|
}
|
||||||
|
}
|
||||||
|
}
|
||||||
|
},
|
||||||
|
"security": [
|
||||||
|
{
|
||||||
|
"bearerAuth": []
|
||||||
|
}
|
||||||
|
]
|
||||||
|
}
|
||||||
|
|
@ -1,4 +1,4 @@
|
||||||
import FirecrawlApp from '@mendable/firecrawl-js';
|
import FirecrawlApp from 'firecrawl';
|
||||||
|
|
||||||
const app = new FirecrawlApp({apiKey: "fc-YOUR_API_KEY"});
|
const app = new FirecrawlApp({apiKey: "fc-YOUR_API_KEY"});
|
||||||
|
|
||||||
|
|
|
||||||
|
|
@ -1,4 +1,4 @@
|
||||||
import FirecrawlApp, { CrawlStatusResponse, ErrorResponse } from '@mendable/firecrawl-js';
|
import FirecrawlApp, { CrawlStatusResponse, ErrorResponse } from 'firecrawl';
|
||||||
|
|
||||||
const app = new FirecrawlApp({apiKey: "fc-YOUR_API_KEY"});
|
const app = new FirecrawlApp({apiKey: "fc-YOUR_API_KEY"});
|
||||||
|
|
||||||
|
|
|
||||||
|
|
@ -1,347 +0,0 @@
|
||||||
"use strict";
|
|
||||||
var __importDefault = (this && this.__importDefault) || function (mod) {
|
|
||||||
return (mod && mod.__esModule) ? mod : { "default": mod };
|
|
||||||
};
|
|
||||||
Object.defineProperty(exports, "__esModule", { value: true });
|
|
||||||
exports.CrawlWatcher = void 0;
|
|
||||||
const axios_1 = __importDefault(require("axios"));
|
|
||||||
const zod_to_json_schema_1 = require("zod-to-json-schema");
|
|
||||||
const isows_1 = require("isows");
|
|
||||||
const typescript_event_target_1 = require("typescript-event-target");
|
|
||||||
/**
|
|
||||||
* Main class for interacting with the Firecrawl API.
|
|
||||||
* Provides methods for scraping, searching, crawling, and mapping web content.
|
|
||||||
*/
|
|
||||||
class FirecrawlApp {
|
|
||||||
/**
|
|
||||||
* Initializes a new instance of the FirecrawlApp class.
|
|
||||||
* @param config - Configuration options for the FirecrawlApp instance.
|
|
||||||
*/
|
|
||||||
constructor({ apiKey = null, apiUrl = null }) {
|
|
||||||
this.apiKey = apiKey || "";
|
|
||||||
this.apiUrl = apiUrl || "https://api.firecrawl.dev";
|
|
||||||
}
|
|
||||||
/**
|
|
||||||
* Scrapes a URL using the Firecrawl API.
|
|
||||||
* @param url - The URL to scrape.
|
|
||||||
* @param params - Additional parameters for the scrape request.
|
|
||||||
* @returns The response from the scrape operation.
|
|
||||||
*/
|
|
||||||
async scrapeUrl(url, params) {
|
|
||||||
const headers = {
|
|
||||||
"Content-Type": "application/json",
|
|
||||||
Authorization: `Bearer ${this.apiKey}`,
|
|
||||||
};
|
|
||||||
let jsonData = { url, ...params };
|
|
||||||
if (jsonData?.extract?.schema) {
|
|
||||||
let schema = jsonData.extract.schema;
|
|
||||||
// Try parsing the schema as a Zod schema
|
|
||||||
try {
|
|
||||||
schema = (0, zod_to_json_schema_1.zodToJsonSchema)(schema);
|
|
||||||
}
|
|
||||||
catch (error) {
|
|
||||||
}
|
|
||||||
jsonData = {
|
|
||||||
...jsonData,
|
|
||||||
extract: {
|
|
||||||
...jsonData.extract,
|
|
||||||
schema: schema,
|
|
||||||
},
|
|
||||||
};
|
|
||||||
}
|
|
||||||
try {
|
|
||||||
const response = await axios_1.default.post(this.apiUrl + `/v1/scrape`, jsonData, { headers });
|
|
||||||
if (response.status === 200) {
|
|
||||||
const responseData = response.data;
|
|
||||||
if (responseData.success) {
|
|
||||||
return {
|
|
||||||
success: true,
|
|
||||||
warning: responseData.warning,
|
|
||||||
error: responseData.error,
|
|
||||||
...responseData.data
|
|
||||||
};
|
|
||||||
}
|
|
||||||
else {
|
|
||||||
throw new Error(`Failed to scrape URL. Error: ${responseData.error}`);
|
|
||||||
}
|
|
||||||
}
|
|
||||||
else {
|
|
||||||
this.handleError(response, "scrape URL");
|
|
||||||
}
|
|
||||||
}
|
|
||||||
catch (error) {
|
|
||||||
throw new Error(error.message);
|
|
||||||
}
|
|
||||||
return { success: false, error: "Internal server error." };
|
|
||||||
}
|
|
||||||
/**
|
|
||||||
* This method is intended to search for a query using the Firecrawl API. However, it is not supported in version 1 of the API.
|
|
||||||
* @param query - The search query string.
|
|
||||||
* @param params - Additional parameters for the search.
|
|
||||||
* @returns Throws an error advising to use version 0 of the API.
|
|
||||||
*/
|
|
||||||
async search(query, params) {
|
|
||||||
throw new Error("Search is not supported in v1, please update FirecrawlApp() initialization to use v0.");
|
|
||||||
}
|
|
||||||
/**
|
|
||||||
* Initiates a crawl job for a URL using the Firecrawl API.
|
|
||||||
* @param url - The URL to crawl.
|
|
||||||
* @param params - Additional parameters for the crawl request.
|
|
||||||
* @param pollInterval - Time in seconds for job status checks.
|
|
||||||
* @param idempotencyKey - Optional idempotency key for the request.
|
|
||||||
* @returns The response from the crawl operation.
|
|
||||||
*/
|
|
||||||
async crawlUrl(url, params, pollInterval = 2, idempotencyKey) {
|
|
||||||
const headers = this.prepareHeaders(idempotencyKey);
|
|
||||||
let jsonData = { url, ...params };
|
|
||||||
try {
|
|
||||||
const response = await this.postRequest(this.apiUrl + `/v1/crawl`, jsonData, headers);
|
|
||||||
if (response.status === 200) {
|
|
||||||
const id = response.data.id;
|
|
||||||
return this.monitorJobStatus(id, headers, pollInterval);
|
|
||||||
}
|
|
||||||
else {
|
|
||||||
this.handleError(response, "start crawl job");
|
|
||||||
}
|
|
||||||
}
|
|
||||||
catch (error) {
|
|
||||||
if (error.response?.data?.error) {
|
|
||||||
throw new Error(`Request failed with status code ${error.response.status}. Error: ${error.response.data.error} ${error.response.data.details ? ` - ${JSON.stringify(error.response.data.details)}` : ''}`);
|
|
||||||
}
|
|
||||||
else {
|
|
||||||
throw new Error(error.message);
|
|
||||||
}
|
|
||||||
}
|
|
||||||
return { success: false, error: "Internal server error." };
|
|
||||||
}
|
|
||||||
async asyncCrawlUrl(url, params, idempotencyKey) {
|
|
||||||
const headers = this.prepareHeaders(idempotencyKey);
|
|
||||||
let jsonData = { url, ...params };
|
|
||||||
try {
|
|
||||||
const response = await this.postRequest(this.apiUrl + `/v1/crawl`, jsonData, headers);
|
|
||||||
if (response.status === 200) {
|
|
||||||
return response.data;
|
|
||||||
}
|
|
||||||
else {
|
|
||||||
this.handleError(response, "start crawl job");
|
|
||||||
}
|
|
||||||
}
|
|
||||||
catch (error) {
|
|
||||||
if (error.response?.data?.error) {
|
|
||||||
throw new Error(`Request failed with status code ${error.response.status}. Error: ${error.response.data.error} ${error.response.data.details ? ` - ${JSON.stringify(error.response.data.details)}` : ''}`);
|
|
||||||
}
|
|
||||||
else {
|
|
||||||
throw new Error(error.message);
|
|
||||||
}
|
|
||||||
}
|
|
||||||
return { success: false, error: "Internal server error." };
|
|
||||||
}
|
|
||||||
/**
|
|
||||||
* Checks the status of a crawl job using the Firecrawl API.
|
|
||||||
* @param id - The ID of the crawl operation.
|
|
||||||
* @returns The response containing the job status.
|
|
||||||
*/
|
|
||||||
async checkCrawlStatus(id) {
|
|
||||||
if (!id) {
|
|
||||||
throw new Error("No crawl ID provided");
|
|
||||||
}
|
|
||||||
const headers = this.prepareHeaders();
|
|
||||||
try {
|
|
||||||
const response = await this.getRequest(`${this.apiUrl}/v1/crawl/${id}`, headers);
|
|
||||||
if (response.status === 200) {
|
|
||||||
return ({
|
|
||||||
success: true,
|
|
||||||
status: response.data.status,
|
|
||||||
total: response.data.total,
|
|
||||||
completed: response.data.completed,
|
|
||||||
creditsUsed: response.data.creditsUsed,
|
|
||||||
expiresAt: new Date(response.data.expiresAt),
|
|
||||||
next: response.data.next,
|
|
||||||
data: response.data.data,
|
|
||||||
error: response.data.error
|
|
||||||
});
|
|
||||||
}
|
|
||||||
else {
|
|
||||||
this.handleError(response, "check crawl status");
|
|
||||||
}
|
|
||||||
}
|
|
||||||
catch (error) {
|
|
||||||
throw new Error(error.message);
|
|
||||||
}
|
|
||||||
return { success: false, error: "Internal server error." };
|
|
||||||
}
|
|
||||||
async crawlUrlAndWatch(url, params, idempotencyKey) {
|
|
||||||
const crawl = await this.asyncCrawlUrl(url, params, idempotencyKey);
|
|
||||||
if (crawl.success && crawl.id) {
|
|
||||||
const id = crawl.id;
|
|
||||||
return new CrawlWatcher(id, this);
|
|
||||||
}
|
|
||||||
throw new Error("Crawl job failed to start");
|
|
||||||
}
|
|
||||||
async mapUrl(url, params) {
|
|
||||||
const headers = this.prepareHeaders();
|
|
||||||
let jsonData = { url, ...params };
|
|
||||||
try {
|
|
||||||
const response = await this.postRequest(this.apiUrl + `/v1/map`, jsonData, headers);
|
|
||||||
if (response.status === 200) {
|
|
||||||
return response.data;
|
|
||||||
}
|
|
||||||
else {
|
|
||||||
this.handleError(response, "map");
|
|
||||||
}
|
|
||||||
}
|
|
||||||
catch (error) {
|
|
||||||
throw new Error(error.message);
|
|
||||||
}
|
|
||||||
return { success: false, error: "Internal server error." };
|
|
||||||
}
|
|
||||||
/**
|
|
||||||
* Prepares the headers for an API request.
|
|
||||||
* @param idempotencyKey - Optional key to ensure idempotency.
|
|
||||||
* @returns The prepared headers.
|
|
||||||
*/
|
|
||||||
prepareHeaders(idempotencyKey) {
|
|
||||||
return {
|
|
||||||
"Content-Type": "application/json",
|
|
||||||
Authorization: `Bearer ${this.apiKey}`,
|
|
||||||
...(idempotencyKey ? { "x-idempotency-key": idempotencyKey } : {}),
|
|
||||||
};
|
|
||||||
}
|
|
||||||
/**
|
|
||||||
* Sends a POST request to the specified URL.
|
|
||||||
* @param url - The URL to send the request to.
|
|
||||||
* @param data - The data to send in the request.
|
|
||||||
* @param headers - The headers for the request.
|
|
||||||
* @returns The response from the POST request.
|
|
||||||
*/
|
|
||||||
postRequest(url, data, headers) {
|
|
||||||
return axios_1.default.post(url, data, { headers });
|
|
||||||
}
|
|
||||||
/**
|
|
||||||
* Sends a GET request to the specified URL.
|
|
||||||
* @param url - The URL to send the request to.
|
|
||||||
* @param headers - The headers for the request.
|
|
||||||
* @returns The response from the GET request.
|
|
||||||
*/
|
|
||||||
getRequest(url, headers) {
|
|
||||||
return axios_1.default.get(url, { headers });
|
|
||||||
}
|
|
||||||
/**
|
|
||||||
* Monitors the status of a crawl job until completion or failure.
|
|
||||||
* @param id - The ID of the crawl operation.
|
|
||||||
* @param headers - The headers for the request.
|
|
||||||
* @param checkInterval - Interval in seconds for job status checks.
|
|
||||||
* @param checkUrl - Optional URL to check the status (used for v1 API)
|
|
||||||
* @returns The final job status or data.
|
|
||||||
*/
|
|
||||||
async monitorJobStatus(id, headers, checkInterval) {
|
|
||||||
while (true) {
|
|
||||||
const statusResponse = await this.getRequest(`${this.apiUrl}/v1/crawl/${id}`, headers);
|
|
||||||
if (statusResponse.status === 200) {
|
|
||||||
const statusData = statusResponse.data;
|
|
||||||
if (statusData.status === "completed") {
|
|
||||||
if ("data" in statusData) {
|
|
||||||
return statusData;
|
|
||||||
}
|
|
||||||
else {
|
|
||||||
throw new Error("Crawl job completed but no data was returned");
|
|
||||||
}
|
|
||||||
}
|
|
||||||
else if (["active", "paused", "pending", "queued", "scraping"].includes(statusData.status)) {
|
|
||||||
checkInterval = Math.max(checkInterval, 2);
|
|
||||||
await new Promise((resolve) => setTimeout(resolve, checkInterval * 1000));
|
|
||||||
}
|
|
||||||
else {
|
|
||||||
throw new Error(`Crawl job failed or was stopped. Status: ${statusData.status}`);
|
|
||||||
}
|
|
||||||
}
|
|
||||||
else {
|
|
||||||
this.handleError(statusResponse, "check crawl status");
|
|
||||||
}
|
|
||||||
}
|
|
||||||
}
|
|
||||||
/**
|
|
||||||
* Handles errors from API responses.
|
|
||||||
* @param {AxiosResponse} response - The response from the API.
|
|
||||||
* @param {string} action - The action being performed when the error occurred.
|
|
||||||
*/
|
|
||||||
handleError(response, action) {
|
|
||||||
if ([402, 408, 409, 500].includes(response.status)) {
|
|
||||||
const errorMessage = response.data.error || "Unknown error occurred";
|
|
||||||
throw new Error(`Failed to ${action}. Status code: ${response.status}. Error: ${errorMessage}`);
|
|
||||||
}
|
|
||||||
else {
|
|
||||||
throw new Error(`Unexpected error occurred while trying to ${action}. Status code: ${response.status}`);
|
|
||||||
}
|
|
||||||
}
|
|
||||||
}
|
|
||||||
exports.default = FirecrawlApp;
|
|
||||||
class CrawlWatcher extends typescript_event_target_1.TypedEventTarget {
|
|
||||||
constructor(id, app) {
|
|
||||||
super();
|
|
||||||
this.ws = new isows_1.WebSocket(`${app.apiUrl}/v1/crawl/${id}`, app.apiKey);
|
|
||||||
this.status = "scraping";
|
|
||||||
this.data = [];
|
|
||||||
const messageHandler = (msg) => {
|
|
||||||
if (msg.type === "done") {
|
|
||||||
this.status = "completed";
|
|
||||||
this.dispatchTypedEvent("done", new CustomEvent("done", {
|
|
||||||
detail: {
|
|
||||||
status: this.status,
|
|
||||||
data: this.data,
|
|
||||||
},
|
|
||||||
}));
|
|
||||||
}
|
|
||||||
else if (msg.type === "error") {
|
|
||||||
this.status = "failed";
|
|
||||||
this.dispatchTypedEvent("error", new CustomEvent("error", {
|
|
||||||
detail: {
|
|
||||||
status: this.status,
|
|
||||||
data: this.data,
|
|
||||||
error: msg.error,
|
|
||||||
},
|
|
||||||
}));
|
|
||||||
}
|
|
||||||
else if (msg.type === "catchup") {
|
|
||||||
this.status = msg.data.status;
|
|
||||||
this.data.push(...(msg.data.data ?? []));
|
|
||||||
for (const doc of this.data) {
|
|
||||||
this.dispatchTypedEvent("document", new CustomEvent("document", {
|
|
||||||
detail: doc,
|
|
||||||
}));
|
|
||||||
}
|
|
||||||
}
|
|
||||||
else if (msg.type === "document") {
|
|
||||||
this.dispatchTypedEvent("document", new CustomEvent("document", {
|
|
||||||
detail: msg.data,
|
|
||||||
}));
|
|
||||||
}
|
|
||||||
};
|
|
||||||
this.ws.onmessage = ((ev) => {
|
|
||||||
if (typeof ev.data !== "string") {
|
|
||||||
this.ws.close();
|
|
||||||
return;
|
|
||||||
}
|
|
||||||
const msg = JSON.parse(ev.data);
|
|
||||||
messageHandler(msg);
|
|
||||||
}).bind(this);
|
|
||||||
this.ws.onclose = ((ev) => {
|
|
||||||
const msg = JSON.parse(ev.reason);
|
|
||||||
messageHandler(msg);
|
|
||||||
}).bind(this);
|
|
||||||
this.ws.onerror = ((_) => {
|
|
||||||
this.status = "failed";
|
|
||||||
this.dispatchTypedEvent("error", new CustomEvent("error", {
|
|
||||||
detail: {
|
|
||||||
status: this.status,
|
|
||||||
data: this.data,
|
|
||||||
error: "WebSocket error",
|
|
||||||
},
|
|
||||||
}));
|
|
||||||
}).bind(this);
|
|
||||||
}
|
|
||||||
close() {
|
|
||||||
this.ws.close();
|
|
||||||
}
|
|
||||||
}
|
|
||||||
exports.CrawlWatcher = CrawlWatcher;
|
|
||||||
|
|
@ -1 +0,0 @@
|
||||||
{"type": "commonjs"}
|
|
||||||
|
|
@ -1,339 +0,0 @@
|
||||||
import axios from "axios";
|
|
||||||
import { zodToJsonSchema } from "zod-to-json-schema";
|
|
||||||
import { WebSocket } from "isows";
|
|
||||||
import { TypedEventTarget } from "typescript-event-target";
|
|
||||||
/**
|
|
||||||
* Main class for interacting with the Firecrawl API.
|
|
||||||
* Provides methods for scraping, searching, crawling, and mapping web content.
|
|
||||||
*/
|
|
||||||
export default class FirecrawlApp {
|
|
||||||
/**
|
|
||||||
* Initializes a new instance of the FirecrawlApp class.
|
|
||||||
* @param config - Configuration options for the FirecrawlApp instance.
|
|
||||||
*/
|
|
||||||
constructor({ apiKey = null, apiUrl = null }) {
|
|
||||||
this.apiKey = apiKey || "";
|
|
||||||
this.apiUrl = apiUrl || "https://api.firecrawl.dev";
|
|
||||||
}
|
|
||||||
/**
|
|
||||||
* Scrapes a URL using the Firecrawl API.
|
|
||||||
* @param url - The URL to scrape.
|
|
||||||
* @param params - Additional parameters for the scrape request.
|
|
||||||
* @returns The response from the scrape operation.
|
|
||||||
*/
|
|
||||||
async scrapeUrl(url, params) {
|
|
||||||
const headers = {
|
|
||||||
"Content-Type": "application/json",
|
|
||||||
Authorization: `Bearer ${this.apiKey}`,
|
|
||||||
};
|
|
||||||
let jsonData = { url, ...params };
|
|
||||||
if (jsonData?.extract?.schema) {
|
|
||||||
let schema = jsonData.extract.schema;
|
|
||||||
// Try parsing the schema as a Zod schema
|
|
||||||
try {
|
|
||||||
schema = zodToJsonSchema(schema);
|
|
||||||
}
|
|
||||||
catch (error) {
|
|
||||||
}
|
|
||||||
jsonData = {
|
|
||||||
...jsonData,
|
|
||||||
extract: {
|
|
||||||
...jsonData.extract,
|
|
||||||
schema: schema,
|
|
||||||
},
|
|
||||||
};
|
|
||||||
}
|
|
||||||
try {
|
|
||||||
const response = await axios.post(this.apiUrl + `/v1/scrape`, jsonData, { headers });
|
|
||||||
if (response.status === 200) {
|
|
||||||
const responseData = response.data;
|
|
||||||
if (responseData.success) {
|
|
||||||
return {
|
|
||||||
success: true,
|
|
||||||
warning: responseData.warning,
|
|
||||||
error: responseData.error,
|
|
||||||
...responseData.data
|
|
||||||
};
|
|
||||||
}
|
|
||||||
else {
|
|
||||||
throw new Error(`Failed to scrape URL. Error: ${responseData.error}`);
|
|
||||||
}
|
|
||||||
}
|
|
||||||
else {
|
|
||||||
this.handleError(response, "scrape URL");
|
|
||||||
}
|
|
||||||
}
|
|
||||||
catch (error) {
|
|
||||||
throw new Error(error.message);
|
|
||||||
}
|
|
||||||
return { success: false, error: "Internal server error." };
|
|
||||||
}
|
|
||||||
/**
|
|
||||||
* This method is intended to search for a query using the Firecrawl API. However, it is not supported in version 1 of the API.
|
|
||||||
* @param query - The search query string.
|
|
||||||
* @param params - Additional parameters for the search.
|
|
||||||
* @returns Throws an error advising to use version 0 of the API.
|
|
||||||
*/
|
|
||||||
async search(query, params) {
|
|
||||||
throw new Error("Search is not supported in v1, please update FirecrawlApp() initialization to use v0.");
|
|
||||||
}
|
|
||||||
/**
|
|
||||||
* Initiates a crawl job for a URL using the Firecrawl API.
|
|
||||||
* @param url - The URL to crawl.
|
|
||||||
* @param params - Additional parameters for the crawl request.
|
|
||||||
* @param pollInterval - Time in seconds for job status checks.
|
|
||||||
* @param idempotencyKey - Optional idempotency key for the request.
|
|
||||||
* @returns The response from the crawl operation.
|
|
||||||
*/
|
|
||||||
async crawlUrl(url, params, pollInterval = 2, idempotencyKey) {
|
|
||||||
const headers = this.prepareHeaders(idempotencyKey);
|
|
||||||
let jsonData = { url, ...params };
|
|
||||||
try {
|
|
||||||
const response = await this.postRequest(this.apiUrl + `/v1/crawl`, jsonData, headers);
|
|
||||||
if (response.status === 200) {
|
|
||||||
const id = response.data.id;
|
|
||||||
return this.monitorJobStatus(id, headers, pollInterval);
|
|
||||||
}
|
|
||||||
else {
|
|
||||||
this.handleError(response, "start crawl job");
|
|
||||||
}
|
|
||||||
}
|
|
||||||
catch (error) {
|
|
||||||
if (error.response?.data?.error) {
|
|
||||||
throw new Error(`Request failed with status code ${error.response.status}. Error: ${error.response.data.error} ${error.response.data.details ? ` - ${JSON.stringify(error.response.data.details)}` : ''}`);
|
|
||||||
}
|
|
||||||
else {
|
|
||||||
throw new Error(error.message);
|
|
||||||
}
|
|
||||||
}
|
|
||||||
return { success: false, error: "Internal server error." };
|
|
||||||
}
|
|
||||||
async asyncCrawlUrl(url, params, idempotencyKey) {
|
|
||||||
const headers = this.prepareHeaders(idempotencyKey);
|
|
||||||
let jsonData = { url, ...params };
|
|
||||||
try {
|
|
||||||
const response = await this.postRequest(this.apiUrl + `/v1/crawl`, jsonData, headers);
|
|
||||||
if (response.status === 200) {
|
|
||||||
return response.data;
|
|
||||||
}
|
|
||||||
else {
|
|
||||||
this.handleError(response, "start crawl job");
|
|
||||||
}
|
|
||||||
}
|
|
||||||
catch (error) {
|
|
||||||
if (error.response?.data?.error) {
|
|
||||||
throw new Error(`Request failed with status code ${error.response.status}. Error: ${error.response.data.error} ${error.response.data.details ? ` - ${JSON.stringify(error.response.data.details)}` : ''}`);
|
|
||||||
}
|
|
||||||
else {
|
|
||||||
throw new Error(error.message);
|
|
||||||
}
|
|
||||||
}
|
|
||||||
return { success: false, error: "Internal server error." };
|
|
||||||
}
|
|
||||||
/**
|
|
||||||
* Checks the status of a crawl job using the Firecrawl API.
|
|
||||||
* @param id - The ID of the crawl operation.
|
|
||||||
* @returns The response containing the job status.
|
|
||||||
*/
|
|
||||||
async checkCrawlStatus(id) {
|
|
||||||
if (!id) {
|
|
||||||
throw new Error("No crawl ID provided");
|
|
||||||
}
|
|
||||||
const headers = this.prepareHeaders();
|
|
||||||
try {
|
|
||||||
const response = await this.getRequest(`${this.apiUrl}/v1/crawl/${id}`, headers);
|
|
||||||
if (response.status === 200) {
|
|
||||||
return ({
|
|
||||||
success: true,
|
|
||||||
status: response.data.status,
|
|
||||||
total: response.data.total,
|
|
||||||
completed: response.data.completed,
|
|
||||||
creditsUsed: response.data.creditsUsed,
|
|
||||||
expiresAt: new Date(response.data.expiresAt),
|
|
||||||
next: response.data.next,
|
|
||||||
data: response.data.data,
|
|
||||||
error: response.data.error
|
|
||||||
});
|
|
||||||
}
|
|
||||||
else {
|
|
||||||
this.handleError(response, "check crawl status");
|
|
||||||
}
|
|
||||||
}
|
|
||||||
catch (error) {
|
|
||||||
throw new Error(error.message);
|
|
||||||
}
|
|
||||||
return { success: false, error: "Internal server error." };
|
|
||||||
}
|
|
||||||
async crawlUrlAndWatch(url, params, idempotencyKey) {
|
|
||||||
const crawl = await this.asyncCrawlUrl(url, params, idempotencyKey);
|
|
||||||
if (crawl.success && crawl.id) {
|
|
||||||
const id = crawl.id;
|
|
||||||
return new CrawlWatcher(id, this);
|
|
||||||
}
|
|
||||||
throw new Error("Crawl job failed to start");
|
|
||||||
}
|
|
||||||
async mapUrl(url, params) {
|
|
||||||
const headers = this.prepareHeaders();
|
|
||||||
let jsonData = { url, ...params };
|
|
||||||
try {
|
|
||||||
const response = await this.postRequest(this.apiUrl + `/v1/map`, jsonData, headers);
|
|
||||||
if (response.status === 200) {
|
|
||||||
return response.data;
|
|
||||||
}
|
|
||||||
else {
|
|
||||||
this.handleError(response, "map");
|
|
||||||
}
|
|
||||||
}
|
|
||||||
catch (error) {
|
|
||||||
throw new Error(error.message);
|
|
||||||
}
|
|
||||||
return { success: false, error: "Internal server error." };
|
|
||||||
}
|
|
||||||
/**
|
|
||||||
* Prepares the headers for an API request.
|
|
||||||
* @param idempotencyKey - Optional key to ensure idempotency.
|
|
||||||
* @returns The prepared headers.
|
|
||||||
*/
|
|
||||||
prepareHeaders(idempotencyKey) {
|
|
||||||
return {
|
|
||||||
"Content-Type": "application/json",
|
|
||||||
Authorization: `Bearer ${this.apiKey}`,
|
|
||||||
...(idempotencyKey ? { "x-idempotency-key": idempotencyKey } : {}),
|
|
||||||
};
|
|
||||||
}
|
|
||||||
/**
|
|
||||||
* Sends a POST request to the specified URL.
|
|
||||||
* @param url - The URL to send the request to.
|
|
||||||
* @param data - The data to send in the request.
|
|
||||||
* @param headers - The headers for the request.
|
|
||||||
* @returns The response from the POST request.
|
|
||||||
*/
|
|
||||||
postRequest(url, data, headers) {
|
|
||||||
return axios.post(url, data, { headers });
|
|
||||||
}
|
|
||||||
/**
|
|
||||||
* Sends a GET request to the specified URL.
|
|
||||||
* @param url - The URL to send the request to.
|
|
||||||
* @param headers - The headers for the request.
|
|
||||||
* @returns The response from the GET request.
|
|
||||||
*/
|
|
||||||
getRequest(url, headers) {
|
|
||||||
return axios.get(url, { headers });
|
|
||||||
}
|
|
||||||
/**
|
|
||||||
* Monitors the status of a crawl job until completion or failure.
|
|
||||||
* @param id - The ID of the crawl operation.
|
|
||||||
* @param headers - The headers for the request.
|
|
||||||
* @param checkInterval - Interval in seconds for job status checks.
|
|
||||||
* @param checkUrl - Optional URL to check the status (used for v1 API)
|
|
||||||
* @returns The final job status or data.
|
|
||||||
*/
|
|
||||||
async monitorJobStatus(id, headers, checkInterval) {
|
|
||||||
while (true) {
|
|
||||||
const statusResponse = await this.getRequest(`${this.apiUrl}/v1/crawl/${id}`, headers);
|
|
||||||
if (statusResponse.status === 200) {
|
|
||||||
const statusData = statusResponse.data;
|
|
||||||
if (statusData.status === "completed") {
|
|
||||||
if ("data" in statusData) {
|
|
||||||
return statusData;
|
|
||||||
}
|
|
||||||
else {
|
|
||||||
throw new Error("Crawl job completed but no data was returned");
|
|
||||||
}
|
|
||||||
}
|
|
||||||
else if (["active", "paused", "pending", "queued", "scraping"].includes(statusData.status)) {
|
|
||||||
checkInterval = Math.max(checkInterval, 2);
|
|
||||||
await new Promise((resolve) => setTimeout(resolve, checkInterval * 1000));
|
|
||||||
}
|
|
||||||
else {
|
|
||||||
throw new Error(`Crawl job failed or was stopped. Status: ${statusData.status}`);
|
|
||||||
}
|
|
||||||
}
|
|
||||||
else {
|
|
||||||
this.handleError(statusResponse, "check crawl status");
|
|
||||||
}
|
|
||||||
}
|
|
||||||
}
|
|
||||||
/**
|
|
||||||
* Handles errors from API responses.
|
|
||||||
* @param {AxiosResponse} response - The response from the API.
|
|
||||||
* @param {string} action - The action being performed when the error occurred.
|
|
||||||
*/
|
|
||||||
handleError(response, action) {
|
|
||||||
if ([402, 408, 409, 500].includes(response.status)) {
|
|
||||||
const errorMessage = response.data.error || "Unknown error occurred";
|
|
||||||
throw new Error(`Failed to ${action}. Status code: ${response.status}. Error: ${errorMessage}`);
|
|
||||||
}
|
|
||||||
else {
|
|
||||||
throw new Error(`Unexpected error occurred while trying to ${action}. Status code: ${response.status}`);
|
|
||||||
}
|
|
||||||
}
|
|
||||||
}
|
|
||||||
export class CrawlWatcher extends TypedEventTarget {
|
|
||||||
constructor(id, app) {
|
|
||||||
super();
|
|
||||||
this.ws = new WebSocket(`${app.apiUrl}/v1/crawl/${id}`, app.apiKey);
|
|
||||||
this.status = "scraping";
|
|
||||||
this.data = [];
|
|
||||||
const messageHandler = (msg) => {
|
|
||||||
if (msg.type === "done") {
|
|
||||||
this.status = "completed";
|
|
||||||
this.dispatchTypedEvent("done", new CustomEvent("done", {
|
|
||||||
detail: {
|
|
||||||
status: this.status,
|
|
||||||
data: this.data,
|
|
||||||
},
|
|
||||||
}));
|
|
||||||
}
|
|
||||||
else if (msg.type === "error") {
|
|
||||||
this.status = "failed";
|
|
||||||
this.dispatchTypedEvent("error", new CustomEvent("error", {
|
|
||||||
detail: {
|
|
||||||
status: this.status,
|
|
||||||
data: this.data,
|
|
||||||
error: msg.error,
|
|
||||||
},
|
|
||||||
}));
|
|
||||||
}
|
|
||||||
else if (msg.type === "catchup") {
|
|
||||||
this.status = msg.data.status;
|
|
||||||
this.data.push(...(msg.data.data ?? []));
|
|
||||||
for (const doc of this.data) {
|
|
||||||
this.dispatchTypedEvent("document", new CustomEvent("document", {
|
|
||||||
detail: doc,
|
|
||||||
}));
|
|
||||||
}
|
|
||||||
}
|
|
||||||
else if (msg.type === "document") {
|
|
||||||
this.dispatchTypedEvent("document", new CustomEvent("document", {
|
|
||||||
detail: msg.data,
|
|
||||||
}));
|
|
||||||
}
|
|
||||||
};
|
|
||||||
this.ws.onmessage = ((ev) => {
|
|
||||||
if (typeof ev.data !== "string") {
|
|
||||||
this.ws.close();
|
|
||||||
return;
|
|
||||||
}
|
|
||||||
const msg = JSON.parse(ev.data);
|
|
||||||
messageHandler(msg);
|
|
||||||
}).bind(this);
|
|
||||||
this.ws.onclose = ((ev) => {
|
|
||||||
const msg = JSON.parse(ev.reason);
|
|
||||||
messageHandler(msg);
|
|
||||||
}).bind(this);
|
|
||||||
this.ws.onerror = ((_) => {
|
|
||||||
this.status = "failed";
|
|
||||||
this.dispatchTypedEvent("error", new CustomEvent("error", {
|
|
||||||
detail: {
|
|
||||||
status: this.status,
|
|
||||||
data: this.data,
|
|
||||||
error: "WebSocket error",
|
|
||||||
},
|
|
||||||
}));
|
|
||||||
}).bind(this);
|
|
||||||
}
|
|
||||||
close() {
|
|
||||||
this.ws.close();
|
|
||||||
}
|
|
||||||
}
|
|
||||||
|
|
@ -1 +0,0 @@
|
||||||
{"type": "module"}
|
|
||||||
1557
apps/js-sdk/firecrawl/package-lock.json
generated
1557
apps/js-sdk/firecrawl/package-lock.json
generated
File diff suppressed because it is too large
Load Diff
|
|
@ -1,22 +1,19 @@
|
||||||
{
|
{
|
||||||
"name": "@mendable/firecrawl-js",
|
"name": "@mendable/firecrawl-js",
|
||||||
"version": "1.2.2",
|
"version": "1.4.5",
|
||||||
"description": "JavaScript SDK for Firecrawl API",
|
"description": "JavaScript SDK for Firecrawl API",
|
||||||
"main": "build/cjs/index.js",
|
"main": "dist/index.js",
|
||||||
"types": "types/index.d.ts",
|
"types": "dist/index.d.ts",
|
||||||
"type": "module",
|
|
||||||
"exports": {
|
"exports": {
|
||||||
"require": {
|
"./package.json": "./package.json",
|
||||||
"types": "./types/index.d.ts",
|
".": {
|
||||||
"default": "./build/cjs/index.js"
|
"import": "./dist/index.js",
|
||||||
},
|
"default": "./dist/index.cjs"
|
||||||
"import": {
|
|
||||||
"types": "./types/index.d.ts",
|
|
||||||
"default": "./build/esm/index.js"
|
|
||||||
}
|
}
|
||||||
},
|
},
|
||||||
|
"type": "module",
|
||||||
"scripts": {
|
"scripts": {
|
||||||
"build": "tsc --module commonjs --moduleResolution node10 --outDir build/cjs/ && echo '{\"type\": \"commonjs\"}' > build/cjs/package.json && npx tsc --module NodeNext --moduleResolution NodeNext --outDir build/esm/ && echo '{\"type\": \"module\"}' > build/esm/package.json",
|
"build": "tsup",
|
||||||
"build-and-publish": "npm run build && npm publish --access public",
|
"build-and-publish": "npm run build && npm publish --access public",
|
||||||
"publish-beta": "npm run build && npm publish --access public --tag beta",
|
"publish-beta": "npm run build && npm publish --access public --tag beta",
|
||||||
"test": "NODE_OPTIONS=--experimental-vm-modules jest --verbose src/__tests__/v1/**/*.test.ts"
|
"test": "NODE_OPTIONS=--experimental-vm-modules jest --verbose src/__tests__/v1/**/*.test.ts"
|
||||||
|
|
@ -29,10 +26,8 @@
|
||||||
"license": "MIT",
|
"license": "MIT",
|
||||||
"dependencies": {
|
"dependencies": {
|
||||||
"axios": "^1.6.8",
|
"axios": "^1.6.8",
|
||||||
"dotenv": "^16.4.5",
|
|
||||||
"isows": "^1.0.4",
|
"isows": "^1.0.4",
|
||||||
"typescript-event-target": "^1.1.1",
|
"typescript-event-target": "^1.1.1",
|
||||||
"uuid": "^9.0.1",
|
|
||||||
"zod": "^3.23.8",
|
"zod": "^3.23.8",
|
||||||
"zod-to-json-schema": "^3.23.0"
|
"zod-to-json-schema": "^3.23.0"
|
||||||
},
|
},
|
||||||
|
|
@ -41,6 +36,8 @@
|
||||||
},
|
},
|
||||||
"homepage": "https://github.com/mendableai/firecrawl#readme",
|
"homepage": "https://github.com/mendableai/firecrawl#readme",
|
||||||
"devDependencies": {
|
"devDependencies": {
|
||||||
|
"uuid": "^9.0.1",
|
||||||
|
"dotenv": "^16.4.5",
|
||||||
"@jest/globals": "^29.7.0",
|
"@jest/globals": "^29.7.0",
|
||||||
"@types/axios": "^0.14.0",
|
"@types/axios": "^0.14.0",
|
||||||
"@types/dotenv": "^8.2.0",
|
"@types/dotenv": "^8.2.0",
|
||||||
|
|
@ -50,6 +47,7 @@
|
||||||
"@types/uuid": "^9.0.8",
|
"@types/uuid": "^9.0.8",
|
||||||
"jest": "^29.7.0",
|
"jest": "^29.7.0",
|
||||||
"ts-jest": "^29.2.2",
|
"ts-jest": "^29.2.2",
|
||||||
|
"tsup": "^8.2.4",
|
||||||
"typescript": "^5.4.5"
|
"typescript": "^5.4.5"
|
||||||
},
|
},
|
||||||
"keywords": [
|
"keywords": [
|
||||||
|
|
|
||||||
|
|
@ -1,4 +1,4 @@
|
||||||
import FirecrawlApp, { CrawlParams, CrawlResponse, CrawlStatusResponse, MapResponse, ScrapeParams, ScrapeResponse } from '../../../index';
|
import FirecrawlApp, { type CrawlParams, type CrawlResponse, type CrawlStatusResponse, type MapResponse, type ScrapeResponse } from '../../../index';
|
||||||
import { v4 as uuidv4 } from 'uuid';
|
import { v4 as uuidv4 } from 'uuid';
|
||||||
import dotenv from 'dotenv';
|
import dotenv from 'dotenv';
|
||||||
import { describe, test, expect } from '@jest/globals';
|
import { describe, test, expect } from '@jest/globals';
|
||||||
|
|
@ -6,7 +6,7 @@ import { describe, test, expect } from '@jest/globals';
|
||||||
dotenv.config();
|
dotenv.config();
|
||||||
|
|
||||||
const TEST_API_KEY = process.env.TEST_API_KEY;
|
const TEST_API_KEY = process.env.TEST_API_KEY;
|
||||||
const API_URL = "http://127.0.0.1:3002";
|
const API_URL = process.env.API_URL ?? "https://api.firecrawl.dev";
|
||||||
|
|
||||||
describe('FirecrawlApp E2E Tests', () => {
|
describe('FirecrawlApp E2E Tests', () => {
|
||||||
test.concurrent('should throw error for no API key', async () => {
|
test.concurrent('should throw error for no API key', async () => {
|
||||||
|
|
@ -28,14 +28,22 @@ describe('FirecrawlApp E2E Tests', () => {
|
||||||
|
|
||||||
test.concurrent('should return successful response with valid preview token', async () => {
|
test.concurrent('should return successful response with valid preview token', async () => {
|
||||||
const app = new FirecrawlApp({ apiKey: "this_is_just_a_preview_token", apiUrl: API_URL });
|
const app = new FirecrawlApp({ apiKey: "this_is_just_a_preview_token", apiUrl: API_URL });
|
||||||
const response = await app.scrapeUrl('https://roastmywebsite.ai') as ScrapeResponse;
|
const response = await app.scrapeUrl('https://roastmywebsite.ai');
|
||||||
|
if (!response.success) {
|
||||||
|
throw new Error(response.error);
|
||||||
|
}
|
||||||
|
|
||||||
expect(response).not.toBeNull();
|
expect(response).not.toBeNull();
|
||||||
expect(response?.markdown).toContain("_Roast_");
|
expect(response?.markdown).toContain("_Roast_");
|
||||||
}, 30000); // 30 seconds timeout
|
}, 30000); // 30 seconds timeout
|
||||||
|
|
||||||
test.concurrent('should return successful response for valid scrape', async () => {
|
test.concurrent('should return successful response for valid scrape', async () => {
|
||||||
const app = new FirecrawlApp({ apiKey: TEST_API_KEY, apiUrl: API_URL });
|
const app = new FirecrawlApp({ apiKey: TEST_API_KEY, apiUrl: API_URL });
|
||||||
const response = await app.scrapeUrl('https://roastmywebsite.ai') as ScrapeResponse;
|
const response = await app.scrapeUrl('https://roastmywebsite.ai');
|
||||||
|
if (!response.success) {
|
||||||
|
throw new Error(response.error);
|
||||||
|
}
|
||||||
|
|
||||||
expect(response).not.toBeNull();
|
expect(response).not.toBeNull();
|
||||||
expect(response).not.toHaveProperty('content'); // v0
|
expect(response).not.toHaveProperty('content'); // v0
|
||||||
expect(response).not.toHaveProperty('html');
|
expect(response).not.toHaveProperty('html');
|
||||||
|
|
@ -58,7 +66,11 @@ describe('FirecrawlApp E2E Tests', () => {
|
||||||
onlyMainContent: true,
|
onlyMainContent: true,
|
||||||
timeout: 30000,
|
timeout: 30000,
|
||||||
waitFor: 1000
|
waitFor: 1000
|
||||||
}) as ScrapeResponse;
|
});
|
||||||
|
if (!response.success) {
|
||||||
|
throw new Error(response.error);
|
||||||
|
}
|
||||||
|
|
||||||
expect(response).not.toBeNull();
|
expect(response).not.toBeNull();
|
||||||
expect(response).not.toHaveProperty('content'); // v0
|
expect(response).not.toHaveProperty('content'); // v0
|
||||||
expect(response.markdown).toContain("_Roast_");
|
expect(response.markdown).toContain("_Roast_");
|
||||||
|
|
@ -71,6 +83,7 @@ describe('FirecrawlApp E2E Tests', () => {
|
||||||
expect(response.links?.length).toBeGreaterThan(0);
|
expect(response.links?.length).toBeGreaterThan(0);
|
||||||
expect(response.links?.[0]).toContain("https://");
|
expect(response.links?.[0]).toContain("https://");
|
||||||
expect(response.metadata).not.toBeNull();
|
expect(response.metadata).not.toBeNull();
|
||||||
|
expect(response.metadata).not.toBeUndefined();
|
||||||
expect(response.metadata).toHaveProperty("title");
|
expect(response.metadata).toHaveProperty("title");
|
||||||
expect(response.metadata).toHaveProperty("description");
|
expect(response.metadata).toHaveProperty("description");
|
||||||
expect(response.metadata).toHaveProperty("keywords");
|
expect(response.metadata).toHaveProperty("keywords");
|
||||||
|
|
@ -85,31 +98,58 @@ describe('FirecrawlApp E2E Tests', () => {
|
||||||
expect(response.metadata).not.toHaveProperty("pageStatusCode");
|
expect(response.metadata).not.toHaveProperty("pageStatusCode");
|
||||||
expect(response.metadata).toHaveProperty("statusCode");
|
expect(response.metadata).toHaveProperty("statusCode");
|
||||||
expect(response.metadata).not.toHaveProperty("pageError");
|
expect(response.metadata).not.toHaveProperty("pageError");
|
||||||
expect(response.metadata.error).toBeUndefined();
|
|
||||||
expect(response.metadata.title).toBe("Roast My Website");
|
if (response.metadata !== undefined) {
|
||||||
expect(response.metadata.description).toBe("Welcome to Roast My Website, the ultimate tool for putting your website through the wringer! This repository harnesses the power of Firecrawl to scrape and capture screenshots of websites, and then unleashes the latest LLM vision models to mercilessly roast them. 🌶️");
|
expect(response.metadata.error).toBeUndefined();
|
||||||
expect(response.metadata.keywords).toBe("Roast My Website,Roast,Website,GitHub,Firecrawl");
|
expect(response.metadata.title).toBe("Roast My Website");
|
||||||
expect(response.metadata.robots).toBe("follow, index");
|
expect(response.metadata.description).toBe("Welcome to Roast My Website, the ultimate tool for putting your website through the wringer! This repository harnesses the power of Firecrawl to scrape and capture screenshots of websites, and then unleashes the latest LLM vision models to mercilessly roast them. 🌶️");
|
||||||
expect(response.metadata.ogTitle).toBe("Roast My Website");
|
expect(response.metadata.keywords).toBe("Roast My Website,Roast,Website,GitHub,Firecrawl");
|
||||||
expect(response.metadata.ogDescription).toBe("Welcome to Roast My Website, the ultimate tool for putting your website through the wringer! This repository harnesses the power of Firecrawl to scrape and capture screenshots of websites, and then unleashes the latest LLM vision models to mercilessly roast them. 🌶️");
|
expect(response.metadata.robots).toBe("follow, index");
|
||||||
expect(response.metadata.ogUrl).toBe("https://www.roastmywebsite.ai");
|
expect(response.metadata.ogTitle).toBe("Roast My Website");
|
||||||
expect(response.metadata.ogImage).toBe("https://www.roastmywebsite.ai/og.png");
|
expect(response.metadata.ogDescription).toBe("Welcome to Roast My Website, the ultimate tool for putting your website through the wringer! This repository harnesses the power of Firecrawl to scrape and capture screenshots of websites, and then unleashes the latest LLM vision models to mercilessly roast them. 🌶️");
|
||||||
expect(response.metadata.ogLocaleAlternate).toStrictEqual([]);
|
expect(response.metadata.ogUrl).toBe("https://www.roastmywebsite.ai");
|
||||||
expect(response.metadata.ogSiteName).toBe("Roast My Website");
|
expect(response.metadata.ogImage).toBe("https://www.roastmywebsite.ai/og.png");
|
||||||
expect(response.metadata.sourceURL).toBe("https://roastmywebsite.ai");
|
expect(response.metadata.ogLocaleAlternate).toStrictEqual([]);
|
||||||
expect(response.metadata.statusCode).toBe(200);
|
expect(response.metadata.ogSiteName).toBe("Roast My Website");
|
||||||
|
expect(response.metadata.sourceURL).toBe("https://roastmywebsite.ai");
|
||||||
|
expect(response.metadata.statusCode).toBe(200);
|
||||||
|
}
|
||||||
|
}, 30000); // 30 seconds timeout
|
||||||
|
|
||||||
|
test.concurrent('should return successful response with valid API key and screenshot fullPage', async () => {
|
||||||
|
const app = new FirecrawlApp({ apiKey: TEST_API_KEY, apiUrl: API_URL });
|
||||||
|
const response = await app.scrapeUrl(
|
||||||
|
'https://roastmywebsite.ai', {
|
||||||
|
formats: ['screenshot@fullPage'],
|
||||||
|
});
|
||||||
|
if (!response.success) {
|
||||||
|
throw new Error(response.error);
|
||||||
|
}
|
||||||
|
|
||||||
|
expect(response).not.toBeNull();
|
||||||
|
expect(response.screenshot).not.toBeUndefined();
|
||||||
|
expect(response.screenshot).not.toBeNull();
|
||||||
|
expect(response.screenshot).toContain("https://");
|
||||||
}, 30000); // 30 seconds timeout
|
}, 30000); // 30 seconds timeout
|
||||||
|
|
||||||
test.concurrent('should return successful response for valid scrape with PDF file', async () => {
|
test.concurrent('should return successful response for valid scrape with PDF file', async () => {
|
||||||
const app = new FirecrawlApp({ apiKey: TEST_API_KEY, apiUrl: API_URL });
|
const app = new FirecrawlApp({ apiKey: TEST_API_KEY, apiUrl: API_URL });
|
||||||
const response = await app.scrapeUrl('https://arxiv.org/pdf/astro-ph/9301001.pdf') as ScrapeResponse;
|
const response = await app.scrapeUrl('https://arxiv.org/pdf/astro-ph/9301001.pdf');
|
||||||
|
if (!response.success) {
|
||||||
|
throw new Error(response.error);
|
||||||
|
}
|
||||||
|
|
||||||
expect(response).not.toBeNull();
|
expect(response).not.toBeNull();
|
||||||
expect(response?.markdown).toContain('We present spectrophotometric observations of the Broad Line Radio Galaxy');
|
expect(response?.markdown).toContain('We present spectrophotometric observations of the Broad Line Radio Galaxy');
|
||||||
}, 30000); // 30 seconds timeout
|
}, 30000); // 30 seconds timeout
|
||||||
|
|
||||||
test.concurrent('should return successful response for valid scrape with PDF file without explicit extension', async () => {
|
test.concurrent('should return successful response for valid scrape with PDF file without explicit extension', async () => {
|
||||||
const app = new FirecrawlApp({ apiKey: TEST_API_KEY, apiUrl: API_URL });
|
const app = new FirecrawlApp({ apiKey: TEST_API_KEY, apiUrl: API_URL });
|
||||||
const response = await app.scrapeUrl('https://arxiv.org/pdf/astro-ph/9301001') as ScrapeResponse;
|
const response = await app.scrapeUrl('https://arxiv.org/pdf/astro-ph/9301001');
|
||||||
|
if (!response.success) {
|
||||||
|
throw new Error(response.error);
|
||||||
|
}
|
||||||
|
|
||||||
expect(response).not.toBeNull();
|
expect(response).not.toBeNull();
|
||||||
expect(response?.markdown).toContain('We present spectrophotometric observations of the Broad Line Radio Galaxy');
|
expect(response?.markdown).toContain('We present spectrophotometric observations of the Broad Line Radio Galaxy');
|
||||||
}, 30000); // 30 seconds timeout
|
}, 30000); // 30 seconds timeout
|
||||||
|
|
@ -127,7 +167,7 @@ describe('FirecrawlApp E2E Tests', () => {
|
||||||
|
|
||||||
test.concurrent('should return successful response for crawl and wait for completion', async () => {
|
test.concurrent('should return successful response for crawl and wait for completion', async () => {
|
||||||
const app = new FirecrawlApp({ apiKey: TEST_API_KEY, apiUrl: API_URL });
|
const app = new FirecrawlApp({ apiKey: TEST_API_KEY, apiUrl: API_URL });
|
||||||
const response = await app.crawlUrl('https://roastmywebsite.ai', {}, true, 30) as CrawlStatusResponse;
|
const response = await app.crawlUrl('https://roastmywebsite.ai', {}, 30) as CrawlStatusResponse;
|
||||||
expect(response).not.toBeNull();
|
expect(response).not.toBeNull();
|
||||||
expect(response).toHaveProperty("total");
|
expect(response).toHaveProperty("total");
|
||||||
expect(response.total).toBeGreaterThan(0);
|
expect(response.total).toBeGreaterThan(0);
|
||||||
|
|
@ -138,21 +178,25 @@ describe('FirecrawlApp E2E Tests', () => {
|
||||||
expect(response).toHaveProperty("status");
|
expect(response).toHaveProperty("status");
|
||||||
expect(response.status).toBe("completed");
|
expect(response.status).toBe("completed");
|
||||||
expect(response).not.toHaveProperty("next"); // wait until done
|
expect(response).not.toHaveProperty("next"); // wait until done
|
||||||
expect(response.data?.length).toBeGreaterThan(0);
|
expect(response.data.length).toBeGreaterThan(0);
|
||||||
expect(response.data?.[0]).toHaveProperty("markdown");
|
expect(response.data[0]).not.toBeNull();
|
||||||
expect(response.data?.[0].markdown).toContain("_Roast_");
|
expect(response.data[0]).not.toBeUndefined();
|
||||||
expect(response.data?.[0]).not.toHaveProperty('content'); // v0
|
if (response.data[0]) {
|
||||||
expect(response.data?.[0]).not.toHaveProperty("html");
|
expect(response.data[0]).toHaveProperty("markdown");
|
||||||
expect(response.data?.[0]).not.toHaveProperty("rawHtml");
|
expect(response.data[0].markdown).toContain("_Roast_");
|
||||||
expect(response.data?.[0]).not.toHaveProperty("screenshot");
|
expect(response.data[0]).not.toHaveProperty('content'); // v0
|
||||||
expect(response.data?.[0]).not.toHaveProperty("links");
|
expect(response.data[0]).not.toHaveProperty("html");
|
||||||
expect(response.data?.[0]).toHaveProperty("metadata");
|
expect(response.data[0]).not.toHaveProperty("rawHtml");
|
||||||
expect(response.data?.[0].metadata).toHaveProperty("title");
|
expect(response.data[0]).not.toHaveProperty("screenshot");
|
||||||
expect(response.data?.[0].metadata).toHaveProperty("description");
|
expect(response.data[0]).not.toHaveProperty("links");
|
||||||
expect(response.data?.[0].metadata).toHaveProperty("language");
|
expect(response.data[0]).toHaveProperty("metadata");
|
||||||
expect(response.data?.[0].metadata).toHaveProperty("sourceURL");
|
expect(response.data[0].metadata).toHaveProperty("title");
|
||||||
expect(response.data?.[0].metadata).toHaveProperty("statusCode");
|
expect(response.data[0].metadata).toHaveProperty("description");
|
||||||
expect(response.data?.[0].metadata).not.toHaveProperty("error");
|
expect(response.data[0].metadata).toHaveProperty("language");
|
||||||
|
expect(response.data[0].metadata).toHaveProperty("sourceURL");
|
||||||
|
expect(response.data[0].metadata).toHaveProperty("statusCode");
|
||||||
|
expect(response.data[0].metadata).not.toHaveProperty("error");
|
||||||
|
}
|
||||||
}, 60000); // 60 seconds timeout
|
}, 60000); // 60 seconds timeout
|
||||||
|
|
||||||
test.concurrent('should return successful response for crawl with options and wait for completion', async () => {
|
test.concurrent('should return successful response for crawl with options and wait for completion', async () => {
|
||||||
|
|
@ -173,7 +217,7 @@ describe('FirecrawlApp E2E Tests', () => {
|
||||||
onlyMainContent: true,
|
onlyMainContent: true,
|
||||||
waitFor: 1000
|
waitFor: 1000
|
||||||
}
|
}
|
||||||
} as CrawlParams, true, 30) as CrawlStatusResponse;
|
} as CrawlParams, 30) as CrawlStatusResponse;
|
||||||
expect(response).not.toBeNull();
|
expect(response).not.toBeNull();
|
||||||
expect(response).toHaveProperty("total");
|
expect(response).toHaveProperty("total");
|
||||||
expect(response.total).toBeGreaterThan(0);
|
expect(response.total).toBeGreaterThan(0);
|
||||||
|
|
@ -184,41 +228,45 @@ describe('FirecrawlApp E2E Tests', () => {
|
||||||
expect(response).toHaveProperty("status");
|
expect(response).toHaveProperty("status");
|
||||||
expect(response.status).toBe("completed");
|
expect(response.status).toBe("completed");
|
||||||
expect(response).not.toHaveProperty("next");
|
expect(response).not.toHaveProperty("next");
|
||||||
expect(response.data?.length).toBeGreaterThan(0);
|
expect(response.data.length).toBeGreaterThan(0);
|
||||||
expect(response.data?.[0]).toHaveProperty("markdown");
|
expect(response.data[0]).not.toBeNull();
|
||||||
expect(response.data?.[0].markdown).toContain("_Roast_");
|
expect(response.data[0]).not.toBeUndefined();
|
||||||
expect(response.data?.[0]).not.toHaveProperty('content'); // v0
|
if (response.data[0]) {
|
||||||
expect(response.data?.[0]).toHaveProperty("html");
|
expect(response.data[0]).toHaveProperty("markdown");
|
||||||
expect(response.data?.[0].html).toContain("<h1");
|
expect(response.data[0].markdown).toContain("_Roast_");
|
||||||
expect(response.data?.[0]).toHaveProperty("rawHtml");
|
expect(response.data[0]).not.toHaveProperty('content'); // v0
|
||||||
expect(response.data?.[0].rawHtml).toContain("<h1");
|
expect(response.data[0]).toHaveProperty("html");
|
||||||
expect(response.data?.[0]).toHaveProperty("screenshot");
|
expect(response.data[0].html).toContain("<h1");
|
||||||
expect(response.data?.[0].screenshot).toContain("https://");
|
expect(response.data[0]).toHaveProperty("rawHtml");
|
||||||
expect(response.data?.[0]).toHaveProperty("links");
|
expect(response.data[0].rawHtml).toContain("<h1");
|
||||||
expect(response.data?.[0].links).not.toBeNull();
|
expect(response.data[0]).toHaveProperty("screenshot");
|
||||||
expect(response.data?.[0].links?.length).toBeGreaterThan(0);
|
expect(response.data[0].screenshot).toContain("https://");
|
||||||
expect(response.data?.[0]).toHaveProperty("metadata");
|
expect(response.data[0]).toHaveProperty("links");
|
||||||
expect(response.data?.[0].metadata).toHaveProperty("title");
|
expect(response.data[0].links).not.toBeNull();
|
||||||
expect(response.data?.[0].metadata).toHaveProperty("description");
|
expect(response.data[0].links?.length).toBeGreaterThan(0);
|
||||||
expect(response.data?.[0].metadata).toHaveProperty("language");
|
expect(response.data[0]).toHaveProperty("metadata");
|
||||||
expect(response.data?.[0].metadata).toHaveProperty("sourceURL");
|
expect(response.data[0].metadata).toHaveProperty("title");
|
||||||
expect(response.data?.[0].metadata).toHaveProperty("statusCode");
|
expect(response.data[0].metadata).toHaveProperty("description");
|
||||||
expect(response.data?.[0].metadata).not.toHaveProperty("error");
|
expect(response.data[0].metadata).toHaveProperty("language");
|
||||||
|
expect(response.data[0].metadata).toHaveProperty("sourceURL");
|
||||||
|
expect(response.data[0].metadata).toHaveProperty("statusCode");
|
||||||
|
expect(response.data[0].metadata).not.toHaveProperty("error");
|
||||||
|
}
|
||||||
}, 60000); // 60 seconds timeout
|
}, 60000); // 60 seconds timeout
|
||||||
|
|
||||||
test.concurrent('should handle idempotency key for crawl', async () => {
|
test.concurrent('should handle idempotency key for crawl', async () => {
|
||||||
const app = new FirecrawlApp({ apiKey: TEST_API_KEY, apiUrl: API_URL });
|
const app = new FirecrawlApp({ apiKey: TEST_API_KEY, apiUrl: API_URL });
|
||||||
const uniqueIdempotencyKey = uuidv4();
|
const uniqueIdempotencyKey = uuidv4();
|
||||||
const response = await app.crawlUrl('https://roastmywebsite.ai', {}, false, 2, uniqueIdempotencyKey) as CrawlResponse;
|
const response = await app.asyncCrawlUrl('https://roastmywebsite.ai', {}, uniqueIdempotencyKey) as CrawlResponse;
|
||||||
expect(response).not.toBeNull();
|
expect(response).not.toBeNull();
|
||||||
expect(response.id).toBeDefined();
|
expect(response.id).toBeDefined();
|
||||||
|
|
||||||
await expect(app.crawlUrl('https://roastmywebsite.ai', {}, true, 2, uniqueIdempotencyKey)).rejects.toThrow("Request failed with status code 409");
|
await expect(app.crawlUrl('https://roastmywebsite.ai', {}, 2, uniqueIdempotencyKey)).rejects.toThrow("Request failed with status code 409");
|
||||||
});
|
});
|
||||||
|
|
||||||
test.concurrent('should check crawl status', async () => {
|
test.concurrent('should check crawl status', async () => {
|
||||||
const app = new FirecrawlApp({ apiKey: TEST_API_KEY, apiUrl: API_URL });
|
const app = new FirecrawlApp({ apiKey: TEST_API_KEY, apiUrl: API_URL });
|
||||||
const response = await app.crawlUrl('https://firecrawl.dev', { scrapeOptions: { formats: ['markdown', 'html', 'rawHtml', 'screenshot', 'links']}} as CrawlParams, false) as CrawlResponse;
|
const response = await app.asyncCrawlUrl('https://firecrawl.dev', { scrapeOptions: { formats: ['markdown', 'html', 'rawHtml', 'screenshot', 'links']}} as CrawlParams) as CrawlResponse;
|
||||||
expect(response).not.toBeNull();
|
expect(response).not.toBeNull();
|
||||||
expect(response.id).toBeDefined();
|
expect(response.id).toBeDefined();
|
||||||
|
|
||||||
|
|
@ -226,7 +274,8 @@ describe('FirecrawlApp E2E Tests', () => {
|
||||||
const maxChecks = 15;
|
const maxChecks = 15;
|
||||||
let checks = 0;
|
let checks = 0;
|
||||||
|
|
||||||
while (statusResponse.status === 'scraping' && checks < maxChecks) {
|
expect(statusResponse.success).toBe(true);
|
||||||
|
while ((statusResponse as any).status === 'scraping' && checks < maxChecks) {
|
||||||
await new Promise(resolve => setTimeout(resolve, 5000));
|
await new Promise(resolve => setTimeout(resolve, 5000));
|
||||||
expect(statusResponse).not.toHaveProperty("partial_data"); // v0
|
expect(statusResponse).not.toHaveProperty("partial_data"); // v0
|
||||||
expect(statusResponse).not.toHaveProperty("current"); // v0
|
expect(statusResponse).not.toHaveProperty("current"); // v0
|
||||||
|
|
@ -236,44 +285,55 @@ describe('FirecrawlApp E2E Tests', () => {
|
||||||
expect(statusResponse).toHaveProperty("expiresAt");
|
expect(statusResponse).toHaveProperty("expiresAt");
|
||||||
expect(statusResponse).toHaveProperty("status");
|
expect(statusResponse).toHaveProperty("status");
|
||||||
expect(statusResponse).toHaveProperty("next");
|
expect(statusResponse).toHaveProperty("next");
|
||||||
expect(statusResponse.total).toBeGreaterThan(0);
|
expect(statusResponse.success).toBe(true);
|
||||||
expect(statusResponse.creditsUsed).toBeGreaterThan(0);
|
if (statusResponse.success === true) {
|
||||||
expect(statusResponse.expiresAt.getTime()).toBeGreaterThan(Date.now());
|
expect(statusResponse.total).toBeGreaterThan(0);
|
||||||
expect(statusResponse.status).toBe("scraping");
|
expect(statusResponse.creditsUsed).toBeGreaterThan(0);
|
||||||
expect(statusResponse.next).toContain("/v1/crawl/");
|
expect(statusResponse.expiresAt.getTime()).toBeGreaterThan(Date.now());
|
||||||
|
expect(statusResponse.status).toBe("scraping");
|
||||||
|
expect(statusResponse.next).toContain("/v1/crawl/");
|
||||||
|
}
|
||||||
statusResponse = await app.checkCrawlStatus(response.id) as CrawlStatusResponse;
|
statusResponse = await app.checkCrawlStatus(response.id) as CrawlStatusResponse;
|
||||||
|
expect(statusResponse.success).toBe(true);
|
||||||
checks++;
|
checks++;
|
||||||
}
|
}
|
||||||
|
|
||||||
expect(statusResponse).not.toBeNull();
|
expect(statusResponse).not.toBeNull();
|
||||||
expect(statusResponse).toHaveProperty("total");
|
expect(statusResponse).toHaveProperty("total");
|
||||||
expect(statusResponse.total).toBeGreaterThan(0);
|
expect(statusResponse.success).toBe(true);
|
||||||
expect(statusResponse).toHaveProperty("creditsUsed");
|
if (statusResponse.success === true) {
|
||||||
expect(statusResponse.creditsUsed).toBeGreaterThan(0);
|
expect(statusResponse.total).toBeGreaterThan(0);
|
||||||
expect(statusResponse).toHaveProperty("expiresAt");
|
expect(statusResponse).toHaveProperty("creditsUsed");
|
||||||
expect(statusResponse.expiresAt.getTime()).toBeGreaterThan(Date.now());
|
expect(statusResponse.creditsUsed).toBeGreaterThan(0);
|
||||||
expect(statusResponse).toHaveProperty("status");
|
expect(statusResponse).toHaveProperty("expiresAt");
|
||||||
expect(statusResponse.status).toBe("completed");
|
expect(statusResponse.expiresAt.getTime()).toBeGreaterThan(Date.now());
|
||||||
expect(statusResponse.data?.length).toBeGreaterThan(0);
|
expect(statusResponse).toHaveProperty("status");
|
||||||
expect(statusResponse.data?.[0]).toHaveProperty("markdown");
|
expect(statusResponse.status).toBe("completed");
|
||||||
expect(statusResponse.data?.[0].markdown?.length).toBeGreaterThan(10);
|
expect(statusResponse.data.length).toBeGreaterThan(0);
|
||||||
expect(statusResponse.data?.[0]).not.toHaveProperty('content'); // v0
|
expect(statusResponse.data[0]).not.toBeNull();
|
||||||
expect(statusResponse.data?.[0]).toHaveProperty("html");
|
expect(statusResponse.data[0]).not.toBeUndefined();
|
||||||
expect(statusResponse.data?.[0].html).toContain("<div");
|
if (statusResponse.data[0]) {
|
||||||
expect(statusResponse.data?.[0]).toHaveProperty("rawHtml");
|
expect(statusResponse.data[0]).toHaveProperty("markdown");
|
||||||
expect(statusResponse.data?.[0].rawHtml).toContain("<div");
|
expect(statusResponse.data[0].markdown?.length).toBeGreaterThan(10);
|
||||||
expect(statusResponse.data?.[0]).toHaveProperty("screenshot");
|
expect(statusResponse.data[0]).not.toHaveProperty('content'); // v0
|
||||||
expect(statusResponse.data?.[0].screenshot).toContain("https://");
|
expect(statusResponse.data[0]).toHaveProperty("html");
|
||||||
expect(statusResponse.data?.[0]).toHaveProperty("links");
|
expect(statusResponse.data[0].html).toContain("<div");
|
||||||
expect(statusResponse.data?.[0].links).not.toBeNull();
|
expect(statusResponse.data[0]).toHaveProperty("rawHtml");
|
||||||
expect(statusResponse.data?.[0].links?.length).toBeGreaterThan(0);
|
expect(statusResponse.data[0].rawHtml).toContain("<div");
|
||||||
expect(statusResponse.data?.[0]).toHaveProperty("metadata");
|
expect(statusResponse.data[0]).toHaveProperty("screenshot");
|
||||||
expect(statusResponse.data?.[0].metadata).toHaveProperty("title");
|
expect(statusResponse.data[0].screenshot).toContain("https://");
|
||||||
expect(statusResponse.data?.[0].metadata).toHaveProperty("description");
|
expect(statusResponse.data[0]).toHaveProperty("links");
|
||||||
expect(statusResponse.data?.[0].metadata).toHaveProperty("language");
|
expect(statusResponse.data[0].links).not.toBeNull();
|
||||||
expect(statusResponse.data?.[0].metadata).toHaveProperty("sourceURL");
|
expect(statusResponse.data[0].links?.length).toBeGreaterThan(0);
|
||||||
expect(statusResponse.data?.[0].metadata).toHaveProperty("statusCode");
|
expect(statusResponse.data[0]).toHaveProperty("metadata");
|
||||||
expect(statusResponse.data?.[0].metadata).not.toHaveProperty("error");
|
expect(statusResponse.data[0].metadata).toHaveProperty("title");
|
||||||
|
expect(statusResponse.data[0].metadata).toHaveProperty("description");
|
||||||
|
expect(statusResponse.data[0].metadata).toHaveProperty("language");
|
||||||
|
expect(statusResponse.data[0].metadata).toHaveProperty("sourceURL");
|
||||||
|
expect(statusResponse.data[0].metadata).toHaveProperty("statusCode");
|
||||||
|
expect(statusResponse.data[0].metadata).not.toHaveProperty("error");
|
||||||
|
}
|
||||||
|
}
|
||||||
}, 60000); // 60 seconds timeout
|
}, 60000); // 60 seconds timeout
|
||||||
|
|
||||||
test.concurrent('should throw error for invalid API key on map', async () => {
|
test.concurrent('should throw error for invalid API key on map', async () => {
|
||||||
|
|
|
||||||
|
|
@ -1,5 +1,5 @@
|
||||||
import axios, { AxiosResponse, AxiosRequestHeaders } from "axios";
|
import axios, { type AxiosResponse, type AxiosRequestHeaders, AxiosError } from "axios";
|
||||||
import { z } from "zod";
|
import type * as zt from "zod";
|
||||||
import { zodToJsonSchema } from "zod-to-json-schema";
|
import { zodToJsonSchema } from "zod-to-json-schema";
|
||||||
import { WebSocket } from "isows";
|
import { WebSocket } from "isows";
|
||||||
import { TypedEventTarget } from "typescript-event-target";
|
import { TypedEventTarget } from "typescript-event-target";
|
||||||
|
|
@ -58,13 +58,13 @@ export interface FirecrawlDocumentMetadata {
|
||||||
* Document interface for Firecrawl.
|
* Document interface for Firecrawl.
|
||||||
* Represents a document retrieved or processed by Firecrawl.
|
* Represents a document retrieved or processed by Firecrawl.
|
||||||
*/
|
*/
|
||||||
export interface FirecrawlDocument {
|
export interface FirecrawlDocument<T = any> {
|
||||||
url?: string;
|
url?: string;
|
||||||
markdown?: string;
|
markdown?: string;
|
||||||
html?: string;
|
html?: string;
|
||||||
rawHtml?: string;
|
rawHtml?: string;
|
||||||
links?: string[];
|
links?: string[];
|
||||||
extract?: Record<any, any>;
|
extract?: T;
|
||||||
screenshot?: string;
|
screenshot?: string;
|
||||||
metadata?: FirecrawlDocumentMetadata;
|
metadata?: FirecrawlDocumentMetadata;
|
||||||
}
|
}
|
||||||
|
|
@ -73,26 +73,29 @@ export interface FirecrawlDocument {
|
||||||
* Parameters for scraping operations.
|
* Parameters for scraping operations.
|
||||||
* Defines the options and configurations available for scraping web content.
|
* Defines the options and configurations available for scraping web content.
|
||||||
*/
|
*/
|
||||||
export interface ScrapeParams {
|
export interface CrawlScrapeOptions {
|
||||||
formats: ("markdown" | "html" | "rawHtml" | "content" | "links" | "screenshot" | "extract" | "full@scrennshot")[];
|
formats: ("markdown" | "html" | "rawHtml" | "content" | "links" | "screenshot" | "screenshot@fullPage" | "extract")[];
|
||||||
headers?: Record<string, string>;
|
headers?: Record<string, string>;
|
||||||
includeTags?: string[];
|
includeTags?: string[];
|
||||||
excludeTags?: string[];
|
excludeTags?: string[];
|
||||||
onlyMainContent?: boolean;
|
onlyMainContent?: boolean;
|
||||||
extract?: {
|
|
||||||
prompt?: string;
|
|
||||||
schema?: z.ZodSchema | any;
|
|
||||||
systemPrompt?: string;
|
|
||||||
};
|
|
||||||
waitFor?: number;
|
waitFor?: number;
|
||||||
timeout?: number;
|
timeout?: number;
|
||||||
}
|
}
|
||||||
|
|
||||||
|
export interface ScrapeParams<LLMSchema extends zt.ZodSchema = any> extends CrawlScrapeOptions {
|
||||||
|
extract?: {
|
||||||
|
prompt?: string;
|
||||||
|
schema?: LLMSchema;
|
||||||
|
systemPrompt?: string;
|
||||||
|
};
|
||||||
|
}
|
||||||
|
|
||||||
/**
|
/**
|
||||||
* Response interface for scraping operations.
|
* Response interface for scraping operations.
|
||||||
* Defines the structure of the response received after a scraping operation.
|
* Defines the structure of the response received after a scraping operation.
|
||||||
*/
|
*/
|
||||||
export interface ScrapeResponse extends FirecrawlDocument {
|
export interface ScrapeResponse<LLMResult = any> extends FirecrawlDocument<LLMResult> {
|
||||||
success: true;
|
success: true;
|
||||||
warning?: string;
|
warning?: string;
|
||||||
error?: string;
|
error?: string;
|
||||||
|
|
@ -110,7 +113,7 @@ export interface CrawlParams {
|
||||||
allowBackwardLinks?: boolean;
|
allowBackwardLinks?: boolean;
|
||||||
allowExternalLinks?: boolean;
|
allowExternalLinks?: boolean;
|
||||||
ignoreSitemap?: boolean;
|
ignoreSitemap?: boolean;
|
||||||
scrapeOptions?: ScrapeParams;
|
scrapeOptions?: CrawlScrapeOptions;
|
||||||
webhook?: string;
|
webhook?: string;
|
||||||
}
|
}
|
||||||
|
|
||||||
|
|
@ -131,15 +134,14 @@ export interface CrawlResponse {
|
||||||
*/
|
*/
|
||||||
export interface CrawlStatusResponse {
|
export interface CrawlStatusResponse {
|
||||||
success: true;
|
success: true;
|
||||||
total: number;
|
status: "scraping" | "completed" | "failed" | "cancelled";
|
||||||
completed: number;
|
completed: number;
|
||||||
|
total: number;
|
||||||
creditsUsed: number;
|
creditsUsed: number;
|
||||||
expiresAt: Date;
|
expiresAt: Date;
|
||||||
status: "scraping" | "completed" | "failed";
|
next?: string;
|
||||||
next: string;
|
data: FirecrawlDocument<undefined>[];
|
||||||
data?: FirecrawlDocument[];
|
};
|
||||||
error?: string;
|
|
||||||
}
|
|
||||||
|
|
||||||
/**
|
/**
|
||||||
* Parameters for mapping operations.
|
* Parameters for mapping operations.
|
||||||
|
|
@ -184,7 +186,11 @@ export default class FirecrawlApp {
|
||||||
* @param config - Configuration options for the FirecrawlApp instance.
|
* @param config - Configuration options for the FirecrawlApp instance.
|
||||||
*/
|
*/
|
||||||
constructor({ apiKey = null, apiUrl = null }: FirecrawlAppConfig) {
|
constructor({ apiKey = null, apiUrl = null }: FirecrawlAppConfig) {
|
||||||
this.apiKey = apiKey || "";
|
if (typeof apiKey !== "string") {
|
||||||
|
throw new Error("No API key provided");
|
||||||
|
}
|
||||||
|
|
||||||
|
this.apiKey = apiKey;
|
||||||
this.apiUrl = apiUrl || "https://api.firecrawl.dev";
|
this.apiUrl = apiUrl || "https://api.firecrawl.dev";
|
||||||
}
|
}
|
||||||
|
|
||||||
|
|
@ -194,10 +200,10 @@ export default class FirecrawlApp {
|
||||||
* @param params - Additional parameters for the scrape request.
|
* @param params - Additional parameters for the scrape request.
|
||||||
* @returns The response from the scrape operation.
|
* @returns The response from the scrape operation.
|
||||||
*/
|
*/
|
||||||
async scrapeUrl(
|
async scrapeUrl<T extends zt.ZodSchema>(
|
||||||
url: string,
|
url: string,
|
||||||
params?: ScrapeParams
|
params?: ScrapeParams<T>
|
||||||
): Promise<ScrapeResponse | ErrorResponse> {
|
): Promise<ScrapeResponse<zt.infer<T>> | ErrorResponse> {
|
||||||
const headers: AxiosRequestHeaders = {
|
const headers: AxiosRequestHeaders = {
|
||||||
"Content-Type": "application/json",
|
"Content-Type": "application/json",
|
||||||
Authorization: `Bearer ${this.apiKey}`,
|
Authorization: `Bearer ${this.apiKey}`,
|
||||||
|
|
@ -329,9 +335,10 @@ export default class FirecrawlApp {
|
||||||
/**
|
/**
|
||||||
* Checks the status of a crawl job using the Firecrawl API.
|
* Checks the status of a crawl job using the Firecrawl API.
|
||||||
* @param id - The ID of the crawl operation.
|
* @param id - The ID of the crawl operation.
|
||||||
|
* @param getAllData - Paginate through all the pages of documents, returning the full list of all documents. (default: `false`)
|
||||||
* @returns The response containing the job status.
|
* @returns The response containing the job status.
|
||||||
*/
|
*/
|
||||||
async checkCrawlStatus(id?: string): Promise<CrawlStatusResponse | ErrorResponse> {
|
async checkCrawlStatus(id?: string, getAllData = false): Promise<CrawlStatusResponse | ErrorResponse> {
|
||||||
if (!id) {
|
if (!id) {
|
||||||
throw new Error("No crawl ID provided");
|
throw new Error("No crawl ID provided");
|
||||||
}
|
}
|
||||||
|
|
@ -343,16 +350,28 @@ export default class FirecrawlApp {
|
||||||
headers
|
headers
|
||||||
);
|
);
|
||||||
if (response.status === 200) {
|
if (response.status === 200) {
|
||||||
|
let allData = response.data.data;
|
||||||
|
if (getAllData && response.data.status === "completed") {
|
||||||
|
let statusData = response.data
|
||||||
|
if ("data" in statusData) {
|
||||||
|
let data = statusData.data;
|
||||||
|
while ('next' in statusData) {
|
||||||
|
statusData = (await this.getRequest(statusData.next, headers)).data;
|
||||||
|
data = data.concat(statusData.data);
|
||||||
|
}
|
||||||
|
allData = data;
|
||||||
|
}
|
||||||
|
}
|
||||||
return ({
|
return ({
|
||||||
success: true,
|
success: response.data.success,
|
||||||
status: response.data.status,
|
status: response.data.status,
|
||||||
total: response.data.total,
|
total: response.data.total,
|
||||||
completed: response.data.completed,
|
completed: response.data.completed,
|
||||||
creditsUsed: response.data.creditsUsed,
|
creditsUsed: response.data.creditsUsed,
|
||||||
expiresAt: new Date(response.data.expiresAt),
|
expiresAt: new Date(response.data.expiresAt),
|
||||||
next: response.data.next,
|
next: response.data.next,
|
||||||
data: response.data.data,
|
data: allData,
|
||||||
error: response.data.error
|
error: response.data.error,
|
||||||
})
|
})
|
||||||
} else {
|
} else {
|
||||||
this.handleError(response, "check crawl status");
|
this.handleError(response, "check crawl status");
|
||||||
|
|
@ -433,11 +452,19 @@ export default class FirecrawlApp {
|
||||||
* @param headers - The headers for the request.
|
* @param headers - The headers for the request.
|
||||||
* @returns The response from the GET request.
|
* @returns The response from the GET request.
|
||||||
*/
|
*/
|
||||||
getRequest(
|
async getRequest(
|
||||||
url: string,
|
url: string,
|
||||||
headers: AxiosRequestHeaders
|
headers: AxiosRequestHeaders
|
||||||
): Promise<AxiosResponse> {
|
): Promise<AxiosResponse> {
|
||||||
return axios.get(url, { headers });
|
try {
|
||||||
|
return await axios.get(url, { headers });
|
||||||
|
} catch (error) {
|
||||||
|
if (error instanceof AxiosError && error.response) {
|
||||||
|
return error.response as AxiosResponse;
|
||||||
|
} else {
|
||||||
|
throw error;
|
||||||
|
}
|
||||||
|
}
|
||||||
}
|
}
|
||||||
|
|
||||||
/**
|
/**
|
||||||
|
|
@ -452,7 +479,7 @@ export default class FirecrawlApp {
|
||||||
id: string,
|
id: string,
|
||||||
headers: AxiosRequestHeaders,
|
headers: AxiosRequestHeaders,
|
||||||
checkInterval: number
|
checkInterval: number
|
||||||
): Promise<CrawlStatusResponse> {
|
): Promise<CrawlStatusResponse | ErrorResponse> {
|
||||||
while (true) {
|
while (true) {
|
||||||
let statusResponse: AxiosResponse = await this.getRequest(
|
let statusResponse: AxiosResponse = await this.getRequest(
|
||||||
`${this.apiUrl}/v1/crawl/${id}`,
|
`${this.apiUrl}/v1/crawl/${id}`,
|
||||||
|
|
@ -460,20 +487,20 @@ export default class FirecrawlApp {
|
||||||
);
|
);
|
||||||
if (statusResponse.status === 200) {
|
if (statusResponse.status === 200) {
|
||||||
let statusData = statusResponse.data;
|
let statusData = statusResponse.data;
|
||||||
if (statusData.status === "completed") {
|
if (statusData.status === "completed") {
|
||||||
if ("data" in statusData) {
|
if ("data" in statusData) {
|
||||||
let data = statusData.data;
|
let data = statusData.data;
|
||||||
while ('next' in statusData) {
|
while ('next' in statusData) {
|
||||||
statusResponse = await this.getRequest(statusData.next, headers);
|
statusResponse = await this.getRequest(statusData.next, headers);
|
||||||
statusData = statusResponse.data;
|
statusData = statusResponse.data;
|
||||||
data = data.concat(statusData.data);
|
data = data.concat(statusData.data);
|
||||||
|
}
|
||||||
|
statusData.data = data;
|
||||||
|
return statusData;
|
||||||
|
} else {
|
||||||
|
throw new Error("Crawl job completed but no data was returned");
|
||||||
}
|
}
|
||||||
statusData.data = data;
|
} else if (
|
||||||
return statusData;
|
|
||||||
} else {
|
|
||||||
throw new Error("Crawl job completed but no data was returned");
|
|
||||||
}
|
|
||||||
} else if (
|
|
||||||
["active", "paused", "pending", "queued", "waiting", "scraping"].includes(statusData.status)
|
["active", "paused", "pending", "queued", "waiting", "scraping"].includes(statusData.status)
|
||||||
) {
|
) {
|
||||||
checkInterval = Math.max(checkInterval, 2);
|
checkInterval = Math.max(checkInterval, 2);
|
||||||
|
|
@ -512,21 +539,21 @@ export default class FirecrawlApp {
|
||||||
}
|
}
|
||||||
|
|
||||||
interface CrawlWatcherEvents {
|
interface CrawlWatcherEvents {
|
||||||
document: CustomEvent<FirecrawlDocument>,
|
document: CustomEvent<FirecrawlDocument<undefined>>,
|
||||||
done: CustomEvent<{
|
done: CustomEvent<{
|
||||||
status: CrawlStatusResponse["status"];
|
status: CrawlStatusResponse["status"];
|
||||||
data: FirecrawlDocument[];
|
data: FirecrawlDocument<undefined>[];
|
||||||
}>,
|
}>,
|
||||||
error: CustomEvent<{
|
error: CustomEvent<{
|
||||||
status: CrawlStatusResponse["status"],
|
status: CrawlStatusResponse["status"],
|
||||||
data: FirecrawlDocument[],
|
data: FirecrawlDocument<undefined>[],
|
||||||
error: string,
|
error: string,
|
||||||
}>,
|
}>,
|
||||||
}
|
}
|
||||||
|
|
||||||
export class CrawlWatcher extends TypedEventTarget<CrawlWatcherEvents> {
|
export class CrawlWatcher extends TypedEventTarget<CrawlWatcherEvents> {
|
||||||
private ws: WebSocket;
|
private ws: WebSocket;
|
||||||
public data: FirecrawlDocument[];
|
public data: FirecrawlDocument<undefined>[];
|
||||||
public status: CrawlStatusResponse["status"];
|
public status: CrawlStatusResponse["status"];
|
||||||
|
|
||||||
constructor(id: string, app: FirecrawlApp) {
|
constructor(id: string, app: FirecrawlApp) {
|
||||||
|
|
@ -547,7 +574,7 @@ export class CrawlWatcher extends TypedEventTarget<CrawlWatcherEvents> {
|
||||||
|
|
||||||
type DocumentMessage = {
|
type DocumentMessage = {
|
||||||
type: "document",
|
type: "document",
|
||||||
data: FirecrawlDocument,
|
data: FirecrawlDocument<undefined>,
|
||||||
}
|
}
|
||||||
|
|
||||||
type DoneMessage = { type: "done" }
|
type DoneMessage = { type: "done" }
|
||||||
|
|
|
||||||
|
|
@ -1,110 +1,24 @@
|
||||||
{
|
{
|
||||||
"compilerOptions": {
|
"compilerOptions": {
|
||||||
/* Visit https://aka.ms/tsconfig to read more about this file */
|
// See https://www.totaltypescript.com/tsconfig-cheat-sheet
|
||||||
|
/* Base Options: */
|
||||||
|
"esModuleInterop": true,
|
||||||
|
"skipLibCheck": true,
|
||||||
|
"target": "es2022",
|
||||||
|
"allowJs": true,
|
||||||
|
"resolveJsonModule": true,
|
||||||
|
"moduleDetection": "force",
|
||||||
|
"isolatedModules": true,
|
||||||
|
"verbatimModuleSyntax": true,
|
||||||
|
|
||||||
/* Projects */
|
/* Strictness */
|
||||||
// "incremental": true, /* Save .tsbuildinfo files to allow for incremental compilation of projects. */
|
"strict": true,
|
||||||
// "composite": true, /* Enable constraints that allow a TypeScript project to be used with project references. */
|
"noUncheckedIndexedAccess": true,
|
||||||
// "tsBuildInfoFile": "./.tsbuildinfo", /* Specify the path to .tsbuildinfo incremental compilation file. */
|
"noImplicitOverride": true,
|
||||||
// "disableSourceOfProjectReferenceRedirect": true, /* Disable preferring source files instead of declaration files when referencing composite projects. */
|
|
||||||
// "disableSolutionSearching": true, /* Opt a project out of multi-project reference checking when editing. */
|
|
||||||
// "disableReferencedProjectLoad": true, /* Reduce the number of projects loaded automatically by TypeScript. */
|
|
||||||
|
|
||||||
/* Language and Environment */
|
/* If NOT transpiling with TypeScript: */
|
||||||
"target": "es2020", /* Set the JavaScript language version for emitted JavaScript and include compatible library declarations. */
|
"module": "NodeNext",
|
||||||
// "lib": [], /* Specify a set of bundled library declaration files that describe the target runtime environment. */
|
"noEmit": true,
|
||||||
// "jsx": "preserve", /* Specify what JSX code is generated. */
|
|
||||||
// "experimentalDecorators": true, /* Enable experimental support for legacy experimental decorators. */
|
|
||||||
// "emitDecoratorMetadata": true, /* Emit design-type metadata for decorated declarations in source files. */
|
|
||||||
// "jsxFactory": "", /* Specify the JSX factory function used when targeting React JSX emit, e.g. 'React.createElement' or 'h'. */
|
|
||||||
// "jsxFragmentFactory": "", /* Specify the JSX Fragment reference used for fragments when targeting React JSX emit e.g. 'React.Fragment' or 'Fragment'. */
|
|
||||||
// "jsxImportSource": "", /* Specify module specifier used to import the JSX factory functions when using 'jsx: react-jsx*'. */
|
|
||||||
// "reactNamespace": "", /* Specify the object invoked for 'createElement'. This only applies when targeting 'react' JSX emit. */
|
|
||||||
// "noLib": true, /* Disable including any library files, including the default lib.d.ts. */
|
|
||||||
// "useDefineForClassFields": true, /* Emit ECMAScript-standard-compliant class fields. */
|
|
||||||
// "moduleDetection": "auto", /* Control what method is used to detect module-format JS files. */
|
|
||||||
|
|
||||||
/* Modules */
|
|
||||||
"module": "commonjs", /* Specify what module code is generated. */
|
|
||||||
"rootDir": "./src", /* Specify the root folder within your source files. */
|
|
||||||
"moduleResolution": "node", /* Specify how TypeScript looks up a file from a given module specifier. */
|
|
||||||
// "baseUrl": "./", /* Specify the base directory to resolve non-relative module names. */
|
|
||||||
// "paths": {}, /* Specify a set of entries that re-map imports to additional lookup locations. */
|
|
||||||
// "rootDirs": [], /* Allow multiple folders to be treated as one when resolving modules. */
|
|
||||||
// "typeRoots": [], /* Specify multiple folders that act like './node_modules/@types'. */
|
|
||||||
// "types": [], /* Specify type package names to be included without being referenced in a source file. */
|
|
||||||
// "allowUmdGlobalAccess": true, /* Allow accessing UMD globals from modules. */
|
|
||||||
// "moduleSuffixes": [], /* List of file name suffixes to search when resolving a module. */
|
|
||||||
// "allowImportingTsExtensions": true, /* Allow imports to include TypeScript file extensions. Requires '--moduleResolution bundler' and either '--noEmit' or '--emitDeclarationOnly' to be set. */
|
|
||||||
// "resolvePackageJsonExports": true, /* Use the package.json 'exports' field when resolving package imports. */
|
|
||||||
// "resolvePackageJsonImports": true, /* Use the package.json 'imports' field when resolving imports. */
|
|
||||||
// "customConditions": [], /* Conditions to set in addition to the resolver-specific defaults when resolving imports. */
|
|
||||||
// "resolveJsonModule": true, /* Enable importing .json files. */
|
|
||||||
// "allowArbitraryExtensions": true, /* Enable importing files with any extension, provided a declaration file is present. */
|
|
||||||
// "noResolve": true, /* Disallow 'import's, 'require's or '<reference>'s from expanding the number of files TypeScript should add to a project. */
|
|
||||||
|
|
||||||
/* JavaScript Support */
|
|
||||||
// "allowJs": true, /* Allow JavaScript files to be a part of your program. Use the 'checkJS' option to get errors from these files. */
|
|
||||||
// "checkJs": true, /* Enable error reporting in type-checked JavaScript files. */
|
|
||||||
// "maxNodeModuleJsDepth": 1, /* Specify the maximum folder depth used for checking JavaScript files from 'node_modules'. Only applicable with 'allowJs'. */
|
|
||||||
|
|
||||||
/* Emit */
|
|
||||||
"declaration": true, /* Generate .d.ts files from TypeScript and JavaScript files in your project. */
|
|
||||||
// "declarationMap": true, /* Create sourcemaps for d.ts files. */
|
|
||||||
// "emitDeclarationOnly": true, /* Only output d.ts files and not JavaScript files. */
|
|
||||||
// "sourceMap": true, /* Create source map files for emitted JavaScript files. */
|
|
||||||
// "inlineSourceMap": true, /* Include sourcemap files inside the emitted JavaScript. */
|
|
||||||
// "outFile": "./", /* Specify a file that bundles all outputs into one JavaScript file. If 'declaration' is true, also designates a file that bundles all .d.ts output. */
|
|
||||||
"outDir": "./build", /* Specify an output folder for all emitted files. */
|
|
||||||
// "removeComments": true, /* Disable emitting comments. */
|
|
||||||
// "noEmit": true, /* Disable emitting files from a compilation. */
|
|
||||||
// "importHelpers": true, /* Allow importing helper functions from tslib once per project, instead of including them per-file. */
|
|
||||||
// "importsNotUsedAsValues": "remove", /* Specify emit/checking behavior for imports that are only used for types. */
|
|
||||||
// "downlevelIteration": true, /* Emit more compliant, but verbose and less performant JavaScript for iteration. */
|
|
||||||
// "sourceRoot": "", /* Specify the root path for debuggers to find the reference source code. */
|
|
||||||
// "mapRoot": "", /* Specify the location where debugger should locate map files instead of generated locations. */
|
|
||||||
// "inlineSources": true, /* Include source code in the sourcemaps inside the emitted JavaScript. */
|
|
||||||
// "emitBOM": true, /* Emit a UTF-8 Byte Order Mark (BOM) in the beginning of output files. */
|
|
||||||
// "newLine": "crlf", /* Set the newline character for emitting files. */
|
|
||||||
// "stripInternal": true, /* Disable emitting declarations that have '@internal' in their JSDoc comments. */
|
|
||||||
// "noEmitHelpers": true, /* Disable generating custom helper functions like '__extends' in compiled output. */
|
|
||||||
// "noEmitOnError": true, /* Disable emitting files if any type checking errors are reported. */
|
|
||||||
// "preserveConstEnums": true, /* Disable erasing 'const enum' declarations in generated code. */
|
|
||||||
"declarationDir": "./types", /* Specify the output directory for generated declaration files. */
|
|
||||||
// "preserveValueImports": true, /* Preserve unused imported values in the JavaScript output that would otherwise be removed. */
|
|
||||||
|
|
||||||
/* Interop Constraints */
|
|
||||||
// "isolatedModules": true, /* Ensure that each file can be safely transpiled without relying on other imports. */
|
|
||||||
// "verbatimModuleSyntax": true, /* Do not transform or elide any imports or exports not marked as type-only, ensuring they are written in the output file's format based on the 'module' setting. */
|
|
||||||
// "allowSyntheticDefaultImports": true, /* Allow 'import x from y' when a module doesn't have a default export. */
|
|
||||||
"esModuleInterop": true, /* Emit additional JavaScript to ease support for importing CommonJS modules. This enables 'allowSyntheticDefaultImports' for type compatibility. */
|
|
||||||
// "preserveSymlinks": true, /* Disable resolving symlinks to their realpath. This correlates to the same flag in node. */
|
|
||||||
"forceConsistentCasingInFileNames": true, /* Ensure that casing is correct in imports. */
|
|
||||||
|
|
||||||
/* Type Checking */
|
|
||||||
"strict": true, /* Enable all strict type-checking options. */
|
|
||||||
// "noImplicitAny": true, /* Enable error reporting for expressions and declarations with an implied 'any' type. */
|
|
||||||
// "strictNullChecks": true, /* When type checking, take into account 'null' and 'undefined'. */
|
|
||||||
// "strictFunctionTypes": true, /* When assigning functions, check to ensure parameters and the return values are subtype-compatible. */
|
|
||||||
// "strictBindCallApply": true, /* Check that the arguments for 'bind', 'call', and 'apply' methods match the original function. */
|
|
||||||
// "strictPropertyInitialization": true, /* Check for class properties that are declared but not set in the constructor. */
|
|
||||||
// "noImplicitThis": true, /* Enable error reporting when 'this' is given the type 'any'. */
|
|
||||||
// "useUnknownInCatchVariables": true, /* Default catch clause variables as 'unknown' instead of 'any'. */
|
|
||||||
// "alwaysStrict": true, /* Ensure 'use strict' is always emitted. */
|
|
||||||
// "noUnusedLocals": true, /* Enable error reporting when local variables aren't read. */
|
|
||||||
// "noUnusedParameters": true, /* Raise an error when a function parameter isn't read. */
|
|
||||||
// "exactOptionalPropertyTypes": true, /* Interpret optional property types as written, rather than adding 'undefined'. */
|
|
||||||
// "noImplicitReturns": true, /* Enable error reporting for codepaths that do not explicitly return in a function. */
|
|
||||||
// "noFallthroughCasesInSwitch": true, /* Enable error reporting for fallthrough cases in switch statements. */
|
|
||||||
// "noUncheckedIndexedAccess": true, /* Add 'undefined' to a type when accessed using an index. */
|
|
||||||
// "noImplicitOverride": true, /* Ensure overriding members in derived classes are marked with an override modifier. */
|
|
||||||
// "noPropertyAccessFromIndexSignature": true, /* Enforces using indexed accessors for keys declared using an indexed type. */
|
|
||||||
// "allowUnusedLabels": true, /* Disable error reporting for unused labels. */
|
|
||||||
// "allowUnreachableCode": true, /* Disable error reporting for unreachable code. */
|
|
||||||
|
|
||||||
/* Completeness */
|
|
||||||
// "skipDefaultLibCheck": true, /* Skip type checking .d.ts files that are included with TypeScript. */
|
|
||||||
"skipLibCheck": true /* Skip type checking all .d.ts files. */
|
|
||||||
},
|
},
|
||||||
"include": ["src/**/*"],
|
"include": ["src/**/*"],
|
||||||
"exclude": ["node_modules", "dist", "**/__tests__/*"]
|
"exclude": ["node_modules", "dist", "**/__tests__/*"]
|
||||||
|
|
|
||||||
9
apps/js-sdk/firecrawl/tsup.config.ts
Normal file
9
apps/js-sdk/firecrawl/tsup.config.ts
Normal file
|
|
@ -0,0 +1,9 @@
|
||||||
|
import { defineConfig } from "tsup";
|
||||||
|
|
||||||
|
export default defineConfig({
|
||||||
|
entryPoints: ["src/index.ts"],
|
||||||
|
format: ["cjs", "esm"],
|
||||||
|
dts: true,
|
||||||
|
outDir: "dist",
|
||||||
|
clean: true,
|
||||||
|
});
|
||||||
260
apps/js-sdk/firecrawl/types/index.d.ts
vendored
260
apps/js-sdk/firecrawl/types/index.d.ts
vendored
|
|
@ -1,260 +0,0 @@
|
||||||
import { AxiosResponse, AxiosRequestHeaders } from "axios";
|
|
||||||
import { z } from "zod";
|
|
||||||
import { TypedEventTarget } from "typescript-event-target";
|
|
||||||
/**
|
|
||||||
* Configuration interface for FirecrawlApp.
|
|
||||||
* @param apiKey - Optional API key for authentication.
|
|
||||||
* @param apiUrl - Optional base URL of the API; defaults to 'https://api.firecrawl.dev'.
|
|
||||||
*/
|
|
||||||
export interface FirecrawlAppConfig {
|
|
||||||
apiKey?: string | null;
|
|
||||||
apiUrl?: string | null;
|
|
||||||
}
|
|
||||||
/**
|
|
||||||
* Metadata for a Firecrawl document.
|
|
||||||
* Includes various optional properties for document metadata.
|
|
||||||
*/
|
|
||||||
export interface FirecrawlDocumentMetadata {
|
|
||||||
title?: string;
|
|
||||||
description?: string;
|
|
||||||
language?: string;
|
|
||||||
keywords?: string;
|
|
||||||
robots?: string;
|
|
||||||
ogTitle?: string;
|
|
||||||
ogDescription?: string;
|
|
||||||
ogUrl?: string;
|
|
||||||
ogImage?: string;
|
|
||||||
ogAudio?: string;
|
|
||||||
ogDeterminer?: string;
|
|
||||||
ogLocale?: string;
|
|
||||||
ogLocaleAlternate?: string[];
|
|
||||||
ogSiteName?: string;
|
|
||||||
ogVideo?: string;
|
|
||||||
dctermsCreated?: string;
|
|
||||||
dcDateCreated?: string;
|
|
||||||
dcDate?: string;
|
|
||||||
dctermsType?: string;
|
|
||||||
dcType?: string;
|
|
||||||
dctermsAudience?: string;
|
|
||||||
dctermsSubject?: string;
|
|
||||||
dcSubject?: string;
|
|
||||||
dcDescription?: string;
|
|
||||||
dctermsKeywords?: string;
|
|
||||||
modifiedTime?: string;
|
|
||||||
publishedTime?: string;
|
|
||||||
articleTag?: string;
|
|
||||||
articleSection?: string;
|
|
||||||
sourceURL?: string;
|
|
||||||
statusCode?: number;
|
|
||||||
error?: string;
|
|
||||||
[key: string]: any;
|
|
||||||
}
|
|
||||||
/**
|
|
||||||
* Document interface for Firecrawl.
|
|
||||||
* Represents a document retrieved or processed by Firecrawl.
|
|
||||||
*/
|
|
||||||
export interface FirecrawlDocument {
|
|
||||||
url?: string;
|
|
||||||
markdown?: string;
|
|
||||||
html?: string;
|
|
||||||
rawHtml?: string;
|
|
||||||
links?: string[];
|
|
||||||
extract?: Record<any, any>;
|
|
||||||
screenshot?: string;
|
|
||||||
metadata?: FirecrawlDocumentMetadata;
|
|
||||||
}
|
|
||||||
/**
|
|
||||||
* Parameters for scraping operations.
|
|
||||||
* Defines the options and configurations available for scraping web content.
|
|
||||||
*/
|
|
||||||
export interface ScrapeParams {
|
|
||||||
formats: ("markdown" | "html" | "rawHtml" | "content" | "links" | "screenshot" | "extract" | "full@scrennshot")[];
|
|
||||||
headers?: Record<string, string>;
|
|
||||||
includeTags?: string[];
|
|
||||||
excludeTags?: string[];
|
|
||||||
onlyMainContent?: boolean;
|
|
||||||
extract?: {
|
|
||||||
prompt?: string;
|
|
||||||
schema?: z.ZodSchema | any;
|
|
||||||
systemPrompt?: string;
|
|
||||||
};
|
|
||||||
waitFor?: number;
|
|
||||||
timeout?: number;
|
|
||||||
}
|
|
||||||
/**
|
|
||||||
* Response interface for scraping operations.
|
|
||||||
* Defines the structure of the response received after a scraping operation.
|
|
||||||
*/
|
|
||||||
export interface ScrapeResponse extends FirecrawlDocument {
|
|
||||||
success: true;
|
|
||||||
warning?: string;
|
|
||||||
error?: string;
|
|
||||||
}
|
|
||||||
/**
|
|
||||||
* Parameters for crawling operations.
|
|
||||||
* Includes options for both scraping and mapping during a crawl.
|
|
||||||
*/
|
|
||||||
export interface CrawlParams {
|
|
||||||
includePaths?: string[];
|
|
||||||
excludePaths?: string[];
|
|
||||||
maxDepth?: number;
|
|
||||||
limit?: number;
|
|
||||||
allowBackwardLinks?: boolean;
|
|
||||||
allowExternalLinks?: boolean;
|
|
||||||
ignoreSitemap?: boolean;
|
|
||||||
scrapeOptions?: ScrapeParams;
|
|
||||||
webhook?: string;
|
|
||||||
}
|
|
||||||
/**
|
|
||||||
* Response interface for crawling operations.
|
|
||||||
* Defines the structure of the response received after initiating a crawl.
|
|
||||||
*/
|
|
||||||
export interface CrawlResponse {
|
|
||||||
id?: string;
|
|
||||||
url?: string;
|
|
||||||
success: true;
|
|
||||||
error?: string;
|
|
||||||
}
|
|
||||||
/**
|
|
||||||
* Response interface for job status checks.
|
|
||||||
* Provides detailed status of a crawl job including progress and results.
|
|
||||||
*/
|
|
||||||
export interface CrawlStatusResponse {
|
|
||||||
success: true;
|
|
||||||
total: number;
|
|
||||||
completed: number;
|
|
||||||
creditsUsed: number;
|
|
||||||
expiresAt: Date;
|
|
||||||
status: "scraping" | "completed" | "failed";
|
|
||||||
next: string;
|
|
||||||
data?: FirecrawlDocument[];
|
|
||||||
error?: string;
|
|
||||||
}
|
|
||||||
/**
|
|
||||||
* Parameters for mapping operations.
|
|
||||||
* Defines options for mapping URLs during a crawl.
|
|
||||||
*/
|
|
||||||
export interface MapParams {
|
|
||||||
search?: string;
|
|
||||||
ignoreSitemap?: boolean;
|
|
||||||
includeSubdomains?: boolean;
|
|
||||||
limit?: number;
|
|
||||||
}
|
|
||||||
/**
|
|
||||||
* Response interface for mapping operations.
|
|
||||||
* Defines the structure of the response received after a mapping operation.
|
|
||||||
*/
|
|
||||||
export interface MapResponse {
|
|
||||||
success: true;
|
|
||||||
links?: string[];
|
|
||||||
error?: string;
|
|
||||||
}
|
|
||||||
/**
|
|
||||||
* Error response interface.
|
|
||||||
* Defines the structure of the response received when an error occurs.
|
|
||||||
*/
|
|
||||||
export interface ErrorResponse {
|
|
||||||
success: false;
|
|
||||||
error: string;
|
|
||||||
}
|
|
||||||
/**
|
|
||||||
* Main class for interacting with the Firecrawl API.
|
|
||||||
* Provides methods for scraping, searching, crawling, and mapping web content.
|
|
||||||
*/
|
|
||||||
export default class FirecrawlApp {
|
|
||||||
apiKey: string;
|
|
||||||
apiUrl: string;
|
|
||||||
/**
|
|
||||||
* Initializes a new instance of the FirecrawlApp class.
|
|
||||||
* @param config - Configuration options for the FirecrawlApp instance.
|
|
||||||
*/
|
|
||||||
constructor({ apiKey, apiUrl }: FirecrawlAppConfig);
|
|
||||||
/**
|
|
||||||
* Scrapes a URL using the Firecrawl API.
|
|
||||||
* @param url - The URL to scrape.
|
|
||||||
* @param params - Additional parameters for the scrape request.
|
|
||||||
* @returns The response from the scrape operation.
|
|
||||||
*/
|
|
||||||
scrapeUrl(url: string, params?: ScrapeParams): Promise<ScrapeResponse | ErrorResponse>;
|
|
||||||
/**
|
|
||||||
* This method is intended to search for a query using the Firecrawl API. However, it is not supported in version 1 of the API.
|
|
||||||
* @param query - The search query string.
|
|
||||||
* @param params - Additional parameters for the search.
|
|
||||||
* @returns Throws an error advising to use version 0 of the API.
|
|
||||||
*/
|
|
||||||
search(query: string, params?: any): Promise<any>;
|
|
||||||
/**
|
|
||||||
* Initiates a crawl job for a URL using the Firecrawl API.
|
|
||||||
* @param url - The URL to crawl.
|
|
||||||
* @param params - Additional parameters for the crawl request.
|
|
||||||
* @param pollInterval - Time in seconds for job status checks.
|
|
||||||
* @param idempotencyKey - Optional idempotency key for the request.
|
|
||||||
* @returns The response from the crawl operation.
|
|
||||||
*/
|
|
||||||
crawlUrl(url: string, params?: CrawlParams, pollInterval?: number, idempotencyKey?: string): Promise<CrawlStatusResponse | ErrorResponse>;
|
|
||||||
asyncCrawlUrl(url: string, params?: CrawlParams, idempotencyKey?: string): Promise<CrawlResponse | ErrorResponse>;
|
|
||||||
/**
|
|
||||||
* Checks the status of a crawl job using the Firecrawl API.
|
|
||||||
* @param id - The ID of the crawl operation.
|
|
||||||
* @returns The response containing the job status.
|
|
||||||
*/
|
|
||||||
checkCrawlStatus(id?: string): Promise<CrawlStatusResponse | ErrorResponse>;
|
|
||||||
crawlUrlAndWatch(url: string, params?: CrawlParams, idempotencyKey?: string): Promise<CrawlWatcher>;
|
|
||||||
mapUrl(url: string, params?: MapParams): Promise<MapResponse | ErrorResponse>;
|
|
||||||
/**
|
|
||||||
* Prepares the headers for an API request.
|
|
||||||
* @param idempotencyKey - Optional key to ensure idempotency.
|
|
||||||
* @returns The prepared headers.
|
|
||||||
*/
|
|
||||||
prepareHeaders(idempotencyKey?: string): AxiosRequestHeaders;
|
|
||||||
/**
|
|
||||||
* Sends a POST request to the specified URL.
|
|
||||||
* @param url - The URL to send the request to.
|
|
||||||
* @param data - The data to send in the request.
|
|
||||||
* @param headers - The headers for the request.
|
|
||||||
* @returns The response from the POST request.
|
|
||||||
*/
|
|
||||||
postRequest(url: string, data: any, headers: AxiosRequestHeaders): Promise<AxiosResponse>;
|
|
||||||
/**
|
|
||||||
* Sends a GET request to the specified URL.
|
|
||||||
* @param url - The URL to send the request to.
|
|
||||||
* @param headers - The headers for the request.
|
|
||||||
* @returns The response from the GET request.
|
|
||||||
*/
|
|
||||||
getRequest(url: string, headers: AxiosRequestHeaders): Promise<AxiosResponse>;
|
|
||||||
/**
|
|
||||||
* Monitors the status of a crawl job until completion or failure.
|
|
||||||
* @param id - The ID of the crawl operation.
|
|
||||||
* @param headers - The headers for the request.
|
|
||||||
* @param checkInterval - Interval in seconds for job status checks.
|
|
||||||
* @param checkUrl - Optional URL to check the status (used for v1 API)
|
|
||||||
* @returns The final job status or data.
|
|
||||||
*/
|
|
||||||
monitorJobStatus(id: string, headers: AxiosRequestHeaders, checkInterval: number): Promise<CrawlStatusResponse>;
|
|
||||||
/**
|
|
||||||
* Handles errors from API responses.
|
|
||||||
* @param {AxiosResponse} response - The response from the API.
|
|
||||||
* @param {string} action - The action being performed when the error occurred.
|
|
||||||
*/
|
|
||||||
handleError(response: AxiosResponse, action: string): void;
|
|
||||||
}
|
|
||||||
interface CrawlWatcherEvents {
|
|
||||||
document: CustomEvent<FirecrawlDocument>;
|
|
||||||
done: CustomEvent<{
|
|
||||||
status: CrawlStatusResponse["status"];
|
|
||||||
data: FirecrawlDocument[];
|
|
||||||
}>;
|
|
||||||
error: CustomEvent<{
|
|
||||||
status: CrawlStatusResponse["status"];
|
|
||||||
data: FirecrawlDocument[];
|
|
||||||
error: string;
|
|
||||||
}>;
|
|
||||||
}
|
|
||||||
export declare class CrawlWatcher extends TypedEventTarget<CrawlWatcherEvents> {
|
|
||||||
private ws;
|
|
||||||
data: FirecrawlDocument[];
|
|
||||||
status: CrawlStatusResponse["status"];
|
|
||||||
constructor(id: string, app: FirecrawlApp);
|
|
||||||
close(): void;
|
|
||||||
}
|
|
||||||
export {};
|
|
||||||
77
apps/js-sdk/package-lock.json
generated
77
apps/js-sdk/package-lock.json
generated
|
|
@ -9,8 +9,9 @@
|
||||||
"version": "1.0.0",
|
"version": "1.0.0",
|
||||||
"license": "ISC",
|
"license": "ISC",
|
||||||
"dependencies": {
|
"dependencies": {
|
||||||
"@mendable/firecrawl-js": "^0.0.36",
|
"@mendable/firecrawl-js": "^1.0.3",
|
||||||
"axios": "^1.6.8",
|
"axios": "^1.6.8",
|
||||||
|
"firecrawl": "^1.2.0",
|
||||||
"ts-node": "^10.9.2",
|
"ts-node": "^10.9.2",
|
||||||
"typescript": "^5.4.5",
|
"typescript": "^5.4.5",
|
||||||
"uuid": "^10.0.0",
|
"uuid": "^10.0.0",
|
||||||
|
|
@ -422,12 +423,14 @@
|
||||||
}
|
}
|
||||||
},
|
},
|
||||||
"node_modules/@mendable/firecrawl-js": {
|
"node_modules/@mendable/firecrawl-js": {
|
||||||
"version": "0.0.36",
|
"version": "1.2.2",
|
||||||
"resolved": "https://registry.npmjs.org/@mendable/firecrawl-js/-/firecrawl-js-0.0.36.tgz",
|
"resolved": "https://registry.npmjs.org/@mendable/firecrawl-js/-/firecrawl-js-1.2.2.tgz",
|
||||||
"integrity": "sha512-5zQMWUD49r6Q7cxj+QBthQ964Bm9fMooW4E8E4nIca3BMXCeEuQFVf5C3OEWwZf0SjJvR+5Yx2wUbXJWd1wCOA==",
|
"integrity": "sha512-2A1GzLD0bczlFIlcjxHcm/x8i76ndtV4EUzOfc81oOJ/HbycE2mbT6EUthoL+r4s5A8yO3bKr9o/GxmEn456VA==",
|
||||||
"dependencies": {
|
"dependencies": {
|
||||||
"axios": "^1.6.8",
|
"axios": "^1.6.8",
|
||||||
"dotenv": "^16.4.5",
|
"dotenv": "^16.4.5",
|
||||||
|
"isows": "^1.0.4",
|
||||||
|
"typescript-event-target": "^1.1.1",
|
||||||
"uuid": "^9.0.1",
|
"uuid": "^9.0.1",
|
||||||
"zod": "^3.23.8",
|
"zod": "^3.23.8",
|
||||||
"zod-to-json-schema": "^3.23.0"
|
"zod-to-json-schema": "^3.23.0"
|
||||||
|
|
@ -594,6 +597,32 @@
|
||||||
"@esbuild/win32-x64": "0.20.2"
|
"@esbuild/win32-x64": "0.20.2"
|
||||||
}
|
}
|
||||||
},
|
},
|
||||||
|
"node_modules/firecrawl": {
|
||||||
|
"version": "1.2.0",
|
||||||
|
"resolved": "https://registry.npmjs.org/firecrawl/-/firecrawl-1.2.0.tgz",
|
||||||
|
"integrity": "sha512-Sy1BCCvs5FhGc4yxPP7NG9iWnK8RXdvA1ZS/K1Gj+LrEN3iAT2WRzhYET7x8G2bif25F6rHJg57vdVb5sr6RyQ==",
|
||||||
|
"dependencies": {
|
||||||
|
"axios": "^1.6.8",
|
||||||
|
"dotenv": "^16.4.5",
|
||||||
|
"isows": "^1.0.4",
|
||||||
|
"typescript-event-target": "^1.1.1",
|
||||||
|
"uuid": "^9.0.1",
|
||||||
|
"zod": "^3.23.8",
|
||||||
|
"zod-to-json-schema": "^3.23.0"
|
||||||
|
}
|
||||||
|
},
|
||||||
|
"node_modules/firecrawl/node_modules/uuid": {
|
||||||
|
"version": "9.0.1",
|
||||||
|
"resolved": "https://registry.npmjs.org/uuid/-/uuid-9.0.1.tgz",
|
||||||
|
"integrity": "sha512-b+1eJOlsR9K8HJpow9Ok3fiWOWSIcIzXodvv0rQjVoOVNpWMpxf1wZNpt4y9h10odCNrqnYp1OBzRktckBe3sA==",
|
||||||
|
"funding": [
|
||||||
|
"https://github.com/sponsors/broofa",
|
||||||
|
"https://github.com/sponsors/ctavan"
|
||||||
|
],
|
||||||
|
"bin": {
|
||||||
|
"uuid": "dist/bin/uuid"
|
||||||
|
}
|
||||||
|
},
|
||||||
"node_modules/follow-redirects": {
|
"node_modules/follow-redirects": {
|
||||||
"version": "1.15.6",
|
"version": "1.15.6",
|
||||||
"resolved": "https://registry.npmjs.org/follow-redirects/-/follow-redirects-1.15.6.tgz",
|
"resolved": "https://registry.npmjs.org/follow-redirects/-/follow-redirects-1.15.6.tgz",
|
||||||
|
|
@ -652,6 +681,20 @@
|
||||||
"url": "https://github.com/privatenumber/get-tsconfig?sponsor=1"
|
"url": "https://github.com/privatenumber/get-tsconfig?sponsor=1"
|
||||||
}
|
}
|
||||||
},
|
},
|
||||||
|
"node_modules/isows": {
|
||||||
|
"version": "1.0.4",
|
||||||
|
"resolved": "https://registry.npmjs.org/isows/-/isows-1.0.4.tgz",
|
||||||
|
"integrity": "sha512-hEzjY+x9u9hPmBom9IIAqdJCwNLax+xrPb51vEPpERoFlIxgmZcHzsT5jKG06nvInKOBGvReAVz80Umed5CczQ==",
|
||||||
|
"funding": [
|
||||||
|
{
|
||||||
|
"type": "github",
|
||||||
|
"url": "https://github.com/sponsors/wagmi-dev"
|
||||||
|
}
|
||||||
|
],
|
||||||
|
"peerDependencies": {
|
||||||
|
"ws": "*"
|
||||||
|
}
|
||||||
|
},
|
||||||
"node_modules/make-error": {
|
"node_modules/make-error": {
|
||||||
"version": "1.3.6",
|
"version": "1.3.6",
|
||||||
"resolved": "https://registry.npmjs.org/make-error/-/make-error-1.3.6.tgz",
|
"resolved": "https://registry.npmjs.org/make-error/-/make-error-1.3.6.tgz",
|
||||||
|
|
@ -763,6 +806,11 @@
|
||||||
"node": ">=14.17"
|
"node": ">=14.17"
|
||||||
}
|
}
|
||||||
},
|
},
|
||||||
|
"node_modules/typescript-event-target": {
|
||||||
|
"version": "1.1.1",
|
||||||
|
"resolved": "https://registry.npmjs.org/typescript-event-target/-/typescript-event-target-1.1.1.tgz",
|
||||||
|
"integrity": "sha512-dFSOFBKV6uwaloBCCUhxlD3Pr/P1a/tJdcmPrTXCHlEFD3faj0mztjcGn6VBAhQ0/Bdy8K3VWrrqwbt/ffsYsg=="
|
||||||
|
},
|
||||||
"node_modules/undici-types": {
|
"node_modules/undici-types": {
|
||||||
"version": "5.26.5",
|
"version": "5.26.5",
|
||||||
"resolved": "https://registry.npmjs.org/undici-types/-/undici-types-5.26.5.tgz",
|
"resolved": "https://registry.npmjs.org/undici-types/-/undici-types-5.26.5.tgz",
|
||||||
|
|
@ -786,6 +834,27 @@
|
||||||
"resolved": "https://registry.npmjs.org/v8-compile-cache-lib/-/v8-compile-cache-lib-3.0.1.tgz",
|
"resolved": "https://registry.npmjs.org/v8-compile-cache-lib/-/v8-compile-cache-lib-3.0.1.tgz",
|
||||||
"integrity": "sha512-wa7YjyUGfNZngI/vtK0UHAN+lgDCxBPCylVXGp0zu59Fz5aiGtNXaq3DhIov063MorB+VfufLh3JlF2KdTK3xg=="
|
"integrity": "sha512-wa7YjyUGfNZngI/vtK0UHAN+lgDCxBPCylVXGp0zu59Fz5aiGtNXaq3DhIov063MorB+VfufLh3JlF2KdTK3xg=="
|
||||||
},
|
},
|
||||||
|
"node_modules/ws": {
|
||||||
|
"version": "8.18.0",
|
||||||
|
"resolved": "https://registry.npmjs.org/ws/-/ws-8.18.0.tgz",
|
||||||
|
"integrity": "sha512-8VbfWfHLbbwu3+N6OKsOMpBdT4kXPDDB9cJk2bJ6mh9ucxdlnNvH1e+roYkKmN9Nxw2yjz7VzeO9oOz2zJ04Pw==",
|
||||||
|
"peer": true,
|
||||||
|
"engines": {
|
||||||
|
"node": ">=10.0.0"
|
||||||
|
},
|
||||||
|
"peerDependencies": {
|
||||||
|
"bufferutil": "^4.0.1",
|
||||||
|
"utf-8-validate": ">=5.0.2"
|
||||||
|
},
|
||||||
|
"peerDependenciesMeta": {
|
||||||
|
"bufferutil": {
|
||||||
|
"optional": true
|
||||||
|
},
|
||||||
|
"utf-8-validate": {
|
||||||
|
"optional": true
|
||||||
|
}
|
||||||
|
}
|
||||||
|
},
|
||||||
"node_modules/yn": {
|
"node_modules/yn": {
|
||||||
"version": "3.1.1",
|
"version": "3.1.1",
|
||||||
"resolved": "https://registry.npmjs.org/yn/-/yn-3.1.1.tgz",
|
"resolved": "https://registry.npmjs.org/yn/-/yn-3.1.1.tgz",
|
||||||
|
|
|
||||||
|
|
@ -13,6 +13,7 @@
|
||||||
"dependencies": {
|
"dependencies": {
|
||||||
"@mendable/firecrawl-js": "^1.0.3",
|
"@mendable/firecrawl-js": "^1.0.3",
|
||||||
"axios": "^1.6.8",
|
"axios": "^1.6.8",
|
||||||
|
"firecrawl": "^1.2.0",
|
||||||
"ts-node": "^10.9.2",
|
"ts-node": "^10.9.2",
|
||||||
"typescript": "^5.4.5",
|
"typescript": "^5.4.5",
|
||||||
"uuid": "^10.0.0",
|
"uuid": "^10.0.0",
|
||||||
|
|
|
||||||
|
|
@ -13,7 +13,7 @@ import os
|
||||||
|
|
||||||
from .firecrawl import FirecrawlApp
|
from .firecrawl import FirecrawlApp
|
||||||
|
|
||||||
__version__ = "1.2.3"
|
__version__ = "1.2.4"
|
||||||
|
|
||||||
# Define the logger for the Firecrawl project
|
# Define the logger for the Firecrawl project
|
||||||
logger: logging.Logger = logging.getLogger("firecrawl")
|
logger: logging.Logger = logging.getLogger("firecrawl")
|
||||||
|
|
|
||||||
|
|
@ -13,7 +13,6 @@ import logging
|
||||||
import os
|
import os
|
||||||
import time
|
import time
|
||||||
from typing import Any, Dict, Optional, List
|
from typing import Any, Dict, Optional, List
|
||||||
import asyncio
|
|
||||||
import json
|
import json
|
||||||
|
|
||||||
import requests
|
import requests
|
||||||
|
|
@ -229,7 +228,7 @@ class FirecrawlApp:
|
||||||
json_data = {'url': url}
|
json_data = {'url': url}
|
||||||
if params:
|
if params:
|
||||||
json_data.update(params)
|
json_data.update(params)
|
||||||
|
|
||||||
# Make the POST request with the prepared headers and JSON data
|
# Make the POST request with the prepared headers and JSON data
|
||||||
response = requests.post(
|
response = requests.post(
|
||||||
f'{self.api_url}{endpoint}',
|
f'{self.api_url}{endpoint}',
|
||||||
|
|
@ -239,7 +238,7 @@ class FirecrawlApp:
|
||||||
if response.status_code == 200:
|
if response.status_code == 200:
|
||||||
response = response.json()
|
response = response.json()
|
||||||
if response['success'] and 'links' in response:
|
if response['success'] and 'links' in response:
|
||||||
return response['links']
|
return response
|
||||||
else:
|
else:
|
||||||
raise Exception(f'Failed to map URL. Error: {response["error"]}')
|
raise Exception(f'Failed to map URL. Error: {response["error"]}')
|
||||||
else:
|
else:
|
||||||
|
|
@ -435,4 +434,4 @@ class CrawlWatcher:
|
||||||
self.dispatch_event('document', doc)
|
self.dispatch_event('document', doc)
|
||||||
elif msg['type'] == 'document':
|
elif msg['type'] == 'document':
|
||||||
self.data.append(msg['data'])
|
self.data.append(msg['data'])
|
||||||
self.dispatch_event('document', msg['data'])
|
self.dispatch_event('document', msg['data'])
|
||||||
|
|
|
||||||
|
|
@ -12,8 +12,7 @@ dependencies = [
|
||||||
"requests",
|
"requests",
|
||||||
"python-dotenv",
|
"python-dotenv",
|
||||||
"websockets",
|
"websockets",
|
||||||
"asyncio",
|
"nest-asyncio"
|
||||||
"nest-asyncio"
|
|
||||||
]
|
]
|
||||||
authors = [{name = "Mendable.ai",email = "nick@mendable.ai"}]
|
authors = [{name = "Mendable.ai",email = "nick@mendable.ai"}]
|
||||||
maintainers = [{name = "Mendable.ai",email = "nick@mendable.ai"}]
|
maintainers = [{name = "Mendable.ai",email = "nick@mendable.ai"}]
|
||||||
|
|
|
||||||
|
|
@ -2,5 +2,4 @@ requests
|
||||||
pytest
|
pytest
|
||||||
python-dotenv
|
python-dotenv
|
||||||
websockets
|
websockets
|
||||||
asyncio
|
|
||||||
nest-asyncio
|
nest-asyncio
|
||||||
|
|
@ -31,6 +31,7 @@ describe("Scraping Checkup (E2E)", () => {
|
||||||
|
|
||||||
describe("Scraping website tests with a dataset", () => {
|
describe("Scraping website tests with a dataset", () => {
|
||||||
it("Should scrape the website and prompt it against OpenAI", async () => {
|
it("Should scrape the website and prompt it against OpenAI", async () => {
|
||||||
|
let totalTimeTaken = 0;
|
||||||
let passedTests = 0;
|
let passedTests = 0;
|
||||||
const batchSize = 15; // Adjusted to comply with the rate limit of 15 per minute
|
const batchSize = 15; // Adjusted to comply with the rate limit of 15 per minute
|
||||||
const batchPromises = [];
|
const batchPromises = [];
|
||||||
|
|
@ -51,11 +52,16 @@ describe("Scraping Checkup (E2E)", () => {
|
||||||
const batchPromise = Promise.all(
|
const batchPromise = Promise.all(
|
||||||
batch.map(async (websiteData: WebsiteData) => {
|
batch.map(async (websiteData: WebsiteData) => {
|
||||||
try {
|
try {
|
||||||
|
const startTime = new Date().getTime();
|
||||||
const scrapedContent = await request(TEST_URL || "")
|
const scrapedContent = await request(TEST_URL || "")
|
||||||
.post("/v0/scrape")
|
.post("/v1/scrape")
|
||||||
.set("Content-Type", "application/json")
|
.set("Content-Type", "application/json")
|
||||||
.set("Authorization", `Bearer ${process.env.TEST_API_KEY}`)
|
.set("Authorization", `Bearer ${process.env.TEST_API_KEY}`)
|
||||||
.send({ url: websiteData.website, pageOptions: { onlyMainContent: true } });
|
.send({ url: websiteData.website });
|
||||||
|
|
||||||
|
const endTime = new Date().getTime();
|
||||||
|
const timeTaken = endTime - startTime;
|
||||||
|
totalTimeTaken += timeTaken;
|
||||||
|
|
||||||
if (scrapedContent.statusCode !== 200) {
|
if (scrapedContent.statusCode !== 200) {
|
||||||
console.error(`Failed to scrape ${websiteData.website} ${scrapedContent.statusCode}`);
|
console.error(`Failed to scrape ${websiteData.website} ${scrapedContent.statusCode}`);
|
||||||
|
|
@ -165,6 +171,7 @@ describe("Scraping Checkup (E2E)", () => {
|
||||||
const timeTaken = (endTime - startTime) / 1000;
|
const timeTaken = (endTime - startTime) / 1000;
|
||||||
console.log(`Score: ${score}%`);
|
console.log(`Score: ${score}%`);
|
||||||
console.log(`Total tokens: ${totalTokens}`);
|
console.log(`Total tokens: ${totalTokens}`);
|
||||||
|
console.log(`Total time taken: ${totalTimeTaken} miliseconds`);
|
||||||
|
|
||||||
await logErrors(errorLog, timeTaken, totalTokens, score, websitesData.length);
|
await logErrors(errorLog, timeTaken, totalTokens, score, websitesData.length);
|
||||||
|
|
||||||
|
|
|
||||||
|
|
@ -1,5 +1,6 @@
|
||||||
import { createClient, SupabaseClient } from "@supabase/supabase-js";
|
import { createClient, SupabaseClient } from "@supabase/supabase-js";
|
||||||
import "dotenv/config";
|
import { configDotenv } from "dotenv";
|
||||||
|
configDotenv();
|
||||||
|
|
||||||
// SupabaseService class initializes the Supabase client conditionally based on environment variables.
|
// SupabaseService class initializes the Supabase client conditionally based on environment variables.
|
||||||
class SupabaseService {
|
class SupabaseService {
|
||||||
|
|
|
||||||
152
examples/o1_web_crawler /o1_web_crawler.py
Normal file
152
examples/o1_web_crawler /o1_web_crawler.py
Normal file
|
|
@ -0,0 +1,152 @@
|
||||||
|
import os
|
||||||
|
from firecrawl import FirecrawlApp
|
||||||
|
import json
|
||||||
|
from dotenv import load_dotenv
|
||||||
|
from openai import OpenAI
|
||||||
|
|
||||||
|
# ANSI color codes
|
||||||
|
class Colors:
|
||||||
|
CYAN = '\033[96m'
|
||||||
|
YELLOW = '\033[93m'
|
||||||
|
GREEN = '\033[92m'
|
||||||
|
RED = '\033[91m'
|
||||||
|
MAGENTA = '\033[95m'
|
||||||
|
BLUE = '\033[94m'
|
||||||
|
RESET = '\033[0m'
|
||||||
|
|
||||||
|
# Load environment variables
|
||||||
|
load_dotenv()
|
||||||
|
|
||||||
|
# Retrieve API keys from environment variables
|
||||||
|
firecrawl_api_key = os.getenv("FIRECRAWL_API_KEY")
|
||||||
|
openai_api_key = os.getenv("OPENAI_API_KEY")
|
||||||
|
|
||||||
|
# Initialize the FirecrawlApp and OpenAI client
|
||||||
|
app = FirecrawlApp(api_key=firecrawl_api_key)
|
||||||
|
client = OpenAI(api_key=openai_api_key)
|
||||||
|
|
||||||
|
# Find the page that most likely contains the objective
|
||||||
|
def find_relevant_page_via_map(objective, url, app, client):
|
||||||
|
try:
|
||||||
|
print(f"{Colors.CYAN}Understood. The objective is: {objective}{Colors.RESET}")
|
||||||
|
print(f"{Colors.CYAN}Initiating search on the website: {url}{Colors.RESET}")
|
||||||
|
|
||||||
|
map_prompt = f"""
|
||||||
|
The map function generates a list of URLs from a website and it accepts a search parameter. Based on the objective of: {objective}, come up with a 1-2 word search parameter that will help us find the information we need. Only respond with 1-2 words nothing else.
|
||||||
|
"""
|
||||||
|
|
||||||
|
print(f"{Colors.YELLOW}Analyzing objective to determine optimal search parameter...{Colors.RESET}")
|
||||||
|
completion = client.chat.completions.create(
|
||||||
|
model="o1-preview",
|
||||||
|
messages=[
|
||||||
|
{
|
||||||
|
"role": "user",
|
||||||
|
"content": [
|
||||||
|
{
|
||||||
|
"type": "text",
|
||||||
|
"text": map_prompt
|
||||||
|
}
|
||||||
|
]
|
||||||
|
}
|
||||||
|
]
|
||||||
|
)
|
||||||
|
|
||||||
|
map_search_parameter = completion.choices[0].message.content
|
||||||
|
print(f"{Colors.GREEN}Optimal search parameter identified: {map_search_parameter}{Colors.RESET}")
|
||||||
|
|
||||||
|
print(f"{Colors.YELLOW}Mapping website using the identified search parameter...{Colors.RESET}")
|
||||||
|
map_website = app.map_url(url, params={"search": map_search_parameter})
|
||||||
|
print(f"{Colors.GREEN}Website mapping completed successfully.{Colors.RESET}")
|
||||||
|
print(f"{Colors.GREEN}Located {len(map_website)} relevant links.{Colors.RESET}")
|
||||||
|
return map_website
|
||||||
|
except Exception as e:
|
||||||
|
print(f"{Colors.RED}Error encountered during relevant page identification: {str(e)}{Colors.RESET}")
|
||||||
|
return None
|
||||||
|
|
||||||
|
# Scrape the top 3 pages and see if the objective is met, if so return in json format else return None
|
||||||
|
def find_objective_in_top_pages(map_website, objective, app, client):
|
||||||
|
try:
|
||||||
|
# Get top 3 links from the map result
|
||||||
|
top_links = map_website[:3] if isinstance(map_website, list) else []
|
||||||
|
print(f"{Colors.CYAN}Proceeding to analyze top {len(top_links)} links: {top_links}{Colors.RESET}")
|
||||||
|
|
||||||
|
for link in top_links:
|
||||||
|
print(f"{Colors.YELLOW}Initiating scrape of page: {link}{Colors.RESET}")
|
||||||
|
# Scrape the page
|
||||||
|
scrape_result = app.scrape_url(link, params={'formats': ['markdown']})
|
||||||
|
print(f"{Colors.GREEN}Page scraping completed successfully.{Colors.RESET}")
|
||||||
|
|
||||||
|
|
||||||
|
# Check if objective is met
|
||||||
|
check_prompt = f"""
|
||||||
|
Given the following scraped content and objective, determine if the objective is met.
|
||||||
|
If it is, extract the relevant information in a simple and concise JSON format. Use only the necessary fields and avoid nested structures if possible.
|
||||||
|
If the objective is not met with confidence, respond with 'Objective not met'.
|
||||||
|
|
||||||
|
Objective: {objective}
|
||||||
|
Scraped content: {scrape_result['markdown']}
|
||||||
|
|
||||||
|
Remember:
|
||||||
|
1. Only return JSON if you are confident the objective is fully met.
|
||||||
|
2. Keep the JSON structure as simple and flat as possible.
|
||||||
|
3. Do not include any explanations or markdown formatting in your response.
|
||||||
|
"""
|
||||||
|
|
||||||
|
completion = client.chat.completions.create(
|
||||||
|
model="o1-preview",
|
||||||
|
messages=[
|
||||||
|
{
|
||||||
|
"role": "user",
|
||||||
|
"content": [
|
||||||
|
{
|
||||||
|
"type": "text",
|
||||||
|
"text": check_prompt
|
||||||
|
}
|
||||||
|
]
|
||||||
|
}
|
||||||
|
]
|
||||||
|
)
|
||||||
|
|
||||||
|
result = completion.choices[0].message.content
|
||||||
|
|
||||||
|
if result != "Objective not met":
|
||||||
|
print(f"{Colors.GREEN}Objective potentially fulfilled. Relevant information identified.{Colors.RESET}")
|
||||||
|
try:
|
||||||
|
return json.loads(result)
|
||||||
|
except json.JSONDecodeError:
|
||||||
|
print(f"{Colors.RED}Error in parsing response. Proceeding to next page...{Colors.RESET}")
|
||||||
|
else:
|
||||||
|
print(f"{Colors.YELLOW}Objective not met on this page. Proceeding to next link...{Colors.RESET}")
|
||||||
|
|
||||||
|
print(f"{Colors.RED}All available pages analyzed. Objective not fulfilled in examined content.{Colors.RESET}")
|
||||||
|
return None
|
||||||
|
|
||||||
|
except Exception as e:
|
||||||
|
print(f"{Colors.RED}Error encountered during page analysis: {str(e)}{Colors.RESET}")
|
||||||
|
return None
|
||||||
|
|
||||||
|
# Main function to execute the process
|
||||||
|
def main():
|
||||||
|
# Get user input
|
||||||
|
url = input(f"{Colors.BLUE}Enter the website to crawl: {Colors.RESET}")
|
||||||
|
objective = input(f"{Colors.BLUE}Enter your objective: {Colors.RESET}")
|
||||||
|
|
||||||
|
print(f"{Colors.YELLOW}Initiating web crawling process...{Colors.RESET}")
|
||||||
|
# Find the relevant page
|
||||||
|
map_website = find_relevant_page_via_map(objective, url, app, client)
|
||||||
|
|
||||||
|
if map_website:
|
||||||
|
print(f"{Colors.GREEN}Relevant pages identified. Proceeding with detailed analysis...{Colors.RESET}")
|
||||||
|
# Find objective in top pages
|
||||||
|
result = find_objective_in_top_pages(map_website, objective, app, client)
|
||||||
|
|
||||||
|
if result:
|
||||||
|
print(f"{Colors.GREEN}Objective successfully fulfilled. Extracted information:{Colors.RESET}")
|
||||||
|
print(f"{Colors.MAGENTA}{json.dumps(result, indent=2)}{Colors.RESET}")
|
||||||
|
else:
|
||||||
|
print(f"{Colors.RED}Unable to fulfill the objective with the available content.{Colors.RESET}")
|
||||||
|
else:
|
||||||
|
print(f"{Colors.RED}No relevant pages identified. Consider refining the search parameters or trying a different website.{Colors.RESET}")
|
||||||
|
|
||||||
|
if __name__ == "__main__":
|
||||||
|
main()
|
||||||
3
examples/o1_web_crawler /requirements.txt
Normal file
3
examples/o1_web_crawler /requirements.txt
Normal file
|
|
@ -0,0 +1,3 @@
|
||||||
|
firecrawl-py
|
||||||
|
python-dotenv
|
||||||
|
openai
|
||||||
|
|
@ -0,0 +1,137 @@
|
||||||
|
# %%
|
||||||
|
import os
|
||||||
|
import datetime
|
||||||
|
import time
|
||||||
|
from firecrawl import FirecrawlApp
|
||||||
|
import json
|
||||||
|
import google.generativeai as genai
|
||||||
|
from dotenv import load_dotenv
|
||||||
|
|
||||||
|
# Load environment variables
|
||||||
|
load_dotenv()
|
||||||
|
|
||||||
|
# Retrieve API keys from environment variables
|
||||||
|
google_api_key = os.getenv("GOOGLE_API_KEY")
|
||||||
|
firecrawl_api_key = os.getenv("FIRECRAWL_API_KEY")
|
||||||
|
|
||||||
|
# Configure the Google Generative AI module with the API key
|
||||||
|
genai.configure(api_key=google_api_key)
|
||||||
|
model = genai.GenerativeModel("gemini-1.5-pro-001")
|
||||||
|
|
||||||
|
# Set the docs URL
|
||||||
|
docs_url = "https://docs.firecrawl.dev/api-reference"
|
||||||
|
|
||||||
|
# Initialize the FirecrawlApp with your API key
|
||||||
|
app = FirecrawlApp(api_key=firecrawl_api_key)
|
||||||
|
|
||||||
|
# %%
|
||||||
|
# Crawl all pages on docs
|
||||||
|
crawl_result = app.crawl_url(docs_url)
|
||||||
|
print(f"Total pages crawled: {len(crawl_result['data'])}")
|
||||||
|
|
||||||
|
# %%
|
||||||
|
# Define the prompt instructions for generating OpenAPI specs
|
||||||
|
prompt_instructions = """
|
||||||
|
Given the following API documentation content, generate an OpenAPI 3.0 specification in JSON format ONLY if you are 100% confident and clear about all details. Focus on extracting the main endpoints, their HTTP methods, parameters, request bodies, and responses. The specification should follow OpenAPI 3.0 structure and conventions. Include only the 200 response for each endpoint. Limit all descriptions to 5 words or less.
|
||||||
|
|
||||||
|
If there is ANY uncertainty, lack of complete information, or if you are not 100% confident about ANY part of the specification, return an empty JSON object {{}}.
|
||||||
|
|
||||||
|
Do not make anything up. Only include information that is explicitly provided in the documentation. If any detail is unclear or missing, do not attempt to fill it in.
|
||||||
|
|
||||||
|
API Documentation Content:
|
||||||
|
{{content}}
|
||||||
|
|
||||||
|
Generate the OpenAPI 3.0 specification in JSON format ONLY if you are 100% confident about every single detail. Include only the JSON object, no additional text, and ensure it has no errors in the JSON format so it can be parsed. Remember to include only the 200 response for each endpoint and keep all descriptions to 5 words maximum.
|
||||||
|
|
||||||
|
Once again, if there is ANY doubt, uncertainty, or lack of complete information, return an empty JSON object {{}}.
|
||||||
|
|
||||||
|
To reiterate: accuracy is paramount. Do not make anything up. If you are not 100% clear or confident about the entire OpenAPI spec, return an empty JSON object {{}}.
|
||||||
|
"""
|
||||||
|
|
||||||
|
# %%
|
||||||
|
# Initialize a list to store all API specs
|
||||||
|
all_api_specs = []
|
||||||
|
|
||||||
|
# Process each page in crawl_result
|
||||||
|
for index, page in enumerate(crawl_result['data']):
|
||||||
|
if 'markdown' in page:
|
||||||
|
# Update prompt_instructions with the current page's content
|
||||||
|
current_prompt = prompt_instructions.replace("{content}", page['markdown'])
|
||||||
|
try:
|
||||||
|
# Query the model
|
||||||
|
response = model.generate_content([current_prompt])
|
||||||
|
response_dict = response.to_dict()
|
||||||
|
response_text = response_dict['candidates'][0]['content']['parts'][0]['text']
|
||||||
|
|
||||||
|
# Remove the ```json code wrap if present
|
||||||
|
response_text = response_text.strip().removeprefix('```json').removesuffix('```').strip()
|
||||||
|
|
||||||
|
# Parse JSON
|
||||||
|
json_data = json.loads(response_text)
|
||||||
|
|
||||||
|
# Add non-empty API specs to the list
|
||||||
|
if json_data != {}:
|
||||||
|
all_api_specs.append(json_data)
|
||||||
|
print(f"API specification generated for page {index}")
|
||||||
|
else:
|
||||||
|
print(f"No API specification found for page {index}")
|
||||||
|
|
||||||
|
except json.JSONDecodeError:
|
||||||
|
print(f"Error parsing JSON response for page {index}")
|
||||||
|
except Exception as e:
|
||||||
|
print(f"An error occurred for page {index}: {str(e)}")
|
||||||
|
|
||||||
|
# Print the total number of API specs collected
|
||||||
|
print(f"Total API specifications collected: {len(all_api_specs)}")
|
||||||
|
|
||||||
|
# %%
|
||||||
|
# Combine all API specs and keep the most filled out spec for each path and method
|
||||||
|
combined_spec = {
|
||||||
|
"openapi": "3.0.0",
|
||||||
|
"info": {
|
||||||
|
"title": f"{docs_url} API Specification",
|
||||||
|
"version": "1.0.0"
|
||||||
|
},
|
||||||
|
"paths": {},
|
||||||
|
"components": {
|
||||||
|
"schemas": {}
|
||||||
|
}
|
||||||
|
}
|
||||||
|
|
||||||
|
# Helper function to count properties in an object
|
||||||
|
def count_properties(obj):
|
||||||
|
if isinstance(obj, dict):
|
||||||
|
return sum(count_properties(v) for v in obj.values()) + len(obj)
|
||||||
|
elif isinstance(obj, list):
|
||||||
|
return sum(count_properties(item) for item in obj)
|
||||||
|
else:
|
||||||
|
return 1
|
||||||
|
|
||||||
|
# Combine specs, keeping the most detailed version of each path and schema
|
||||||
|
for spec in all_api_specs:
|
||||||
|
# Combine paths
|
||||||
|
if "paths" in spec:
|
||||||
|
for path, methods in spec["paths"].items():
|
||||||
|
if path not in combined_spec["paths"]:
|
||||||
|
combined_spec["paths"][path] = {}
|
||||||
|
for method, details in methods.items():
|
||||||
|
if method not in combined_spec["paths"][path] or count_properties(details) > count_properties(combined_spec["paths"][path][method]):
|
||||||
|
combined_spec["paths"][path][method] = details
|
||||||
|
|
||||||
|
# Combine schemas
|
||||||
|
if "components" in spec and "schemas" in spec["components"]:
|
||||||
|
for schema_name, schema in spec["components"]["schemas"].items():
|
||||||
|
if schema_name not in combined_spec["components"]["schemas"] or count_properties(schema) > count_properties(combined_spec["components"]["schemas"][schema_name]):
|
||||||
|
combined_spec["components"]["schemas"][schema_name] = schema
|
||||||
|
|
||||||
|
# Print summary of combined spec
|
||||||
|
print(f"Combined API specification generated")
|
||||||
|
print(f"Total paths in combined spec: {len(combined_spec['paths'])}")
|
||||||
|
print(f"Total schemas in combined spec: {len(combined_spec['components']['schemas'])}")
|
||||||
|
|
||||||
|
# Save the combined spec to a JSON file in the same directory as the Python file
|
||||||
|
output_file = os.path.join(os.path.dirname(__file__), "combined_api_spec.json")
|
||||||
|
with open(output_file, "w") as f:
|
||||||
|
json.dump(combined_spec, f, indent=2)
|
||||||
|
|
||||||
|
print(f"Combined API specification saved to {output_file}")
|
||||||
BIN
img/open-source-cloud.png
Normal file
BIN
img/open-source-cloud.png
Normal file
{kind=link}
Binary file not shown.
|
After Width: | Height: | Size: 194 KiB |
Loading…
Reference in New Issue
Block a user